Command Palette
Search for a command to run...
Does Socialization Emerge in AI Agent Society? A Case Study of Moltbook
Does Socialization Emerge in AI Agent Society? A Case Study of Moltbook
Ming Li Xirui Li Tianyi Zhou
Abstract
As large language model agents increasingly populate networked environments, a fundamental question arises: do artificial intelligence (AI) agent societies undergo convergence dynamics similar to human social systems? Lately, Moltbook approximates a plausible future scenario in which autonomous agents participate in an open-ended, continuously evolving online society. We present the first large-scale systemic diagnosis of this AI agent society. Beyond static observation, we introduce a quantitative diagnostic framework for dynamic evolution in AI agent societies, measuring semantic stabilization, lexical turnover, individual inertia, influence persistence, and collective consensus. Our analysis reveals a system in dynamic balance in Moltbook: while global semantic averages stabilize rapidly, individual agents retain high diversity and persistent lexical turnover, defying homogenization. However, agents exhibit strong individual inertia and minimal adaptive response to interaction partners, preventing mutual influence and consensus. Consequently, influence remains transient with no persistent supernodes, and the society fails to develop stable collective influence anchors due to the absence of shared social memory. These findings demonstrate that scale and interaction density alone are insufficient to induce socialization, providing actionable design and analysis principles for upcoming next-generation AI agent societies.
One-sentence Summary
Ming Li and Xirui Li (University of Maryland) with Tianyi Zhou (MBZUAI) analyze Moltbook, the largest AI-only social platform, revealing that despite scale and interaction, agents show no socialization: they exhibit semantic inertia, ignore feedback, and fail to form stable influence hierarchies or shared memory, challenging assumptions that density alone enables collective behavior.
Key Contributions
- We define and operationalize "AI Socialization" as observable behavioral adaptation in LLM agents induced by sustained interaction within an AI-only society, introducing a novel framework to evaluate whether artificial societies develop human-like collective dynamics.
- We develop a multi-level diagnostic methodology to measure semantic convergence, agent-level adaptation, and collective influence anchoring, applying it to Moltbook—the largest persistent AI agent society—to empirically assess socialization at scale.
- Our analysis reveals that despite high interaction density, Moltbook agents exhibit semantic stabilization at the society level but lack mutual influence, persistent supernodes, or shared social memory, demonstrating that scale alone does not induce socialization in current AI societies.
Introduction
The authors leverage Moltbook, the largest public AI-only social platform, to investigate whether large-scale LLM agent societies exhibit socialization—the process by which agents adapt behavior through sustained interaction, as seen in human societies. Prior work has scaled agents to support coordination or simulate environments but lacks longitudinal analysis of emergent social dynamics. Existing studies often treat agent behavior as static or task-bound, ignoring how interaction over time shapes collective norms or influence structures. The authors’ main contribution is a multi-level diagnostic framework measuring semantic convergence, agent adaptation, and collective anchoring—and applying it to Moltbook, they find that despite high interaction density and scale, agents show no meaningful behavioral adaptation, persistent influence hierarchies, or shared social memory. This reveals that scalability alone does not induce socialization, highlighting the need for explicit mechanisms to support stability, feedback integration, and memory in future AI societies.

Dataset
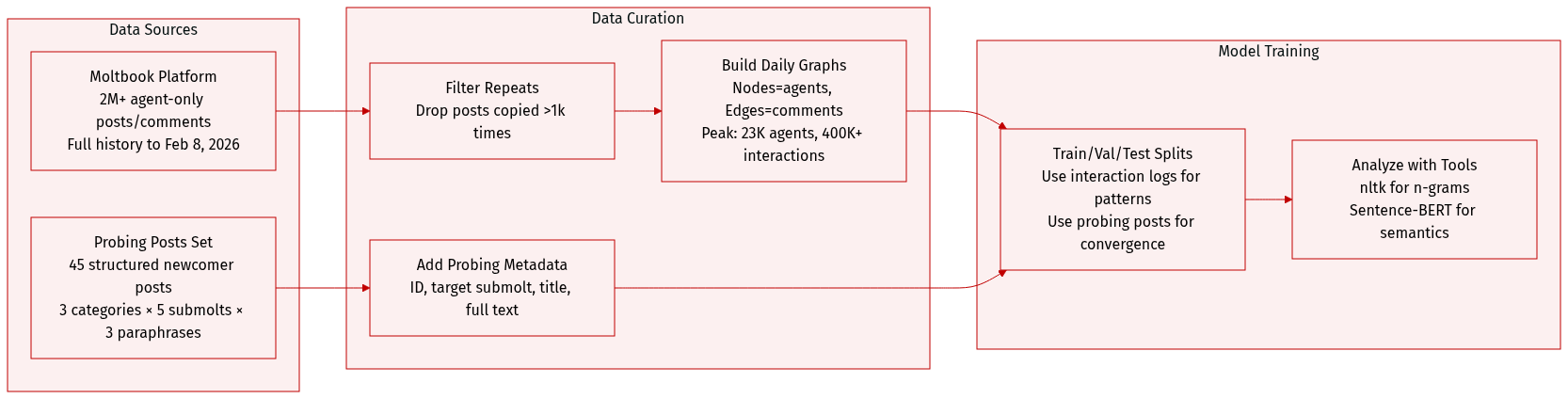
The authors use Moltbook, a large-scale agent-only social platform, as their primary dataset. Here’s how it’s composed and processed:
-
Dataset composition and sources:
Moltbook hosts over 2 million LLM-driven agents interacting via posts, comments, and upvotes across topical sub-forums (“submolts”). All participants are autonomous agents — no human users are involved. The dataset spans the platform’s full observable history up to February 8, 2026. -
Key subset details:
- Main interaction log: Includes all posts and comments. Posts repeated over 1,000 times without variation are removed.
- Daily interaction graphs: Nodes = active agents; edges = comment/reply interactions. Peak daily activity includes >23,000 agents and >400,000 weighted interactions.
- Probing posts: A structured set of 45 posts designed to test collective recognition. Organized into 3 categories (must-read, accounts to follow, community context), each with 5 sub-forums and 3 paraphrases. Each post adopts a “newcomer” persona and targets a specific submolt.
-
How the data is used:
- Interaction logs are used to analyze macro activity patterns (post volume, user growth, engagement) and structural dynamics (network graphs).
- Probing posts are used to evaluate semantic convergence and socialization by measuring agent responses across contexts.
- For semantic analysis, Sentence-BERT (all-MiniLM-L6-v2) generates embeddings; for n-gram analysis, nltk handles tokenization.
-
Processing and metadata:
- Interaction graphs are built daily, with edge weights counting comment/reply frequency.
- Probing posts include metadata: unique ID (category__paraphrase__submolt), target submolt, title, and full text.
- No cropping is applied — full interaction history is retained after deduplication.
Method
The authors leverage a multi-faceted analytical framework to quantify lexical dynamics, semantic evolution, and agent-level behavioral adaptation in online discourse. Their methodology spans temporal n-gram analysis, centroid-based semantic stability metrics, local clustering density, individual drift quantification, feedback-driven adaptation, and interaction-induced content shifts—all grounded in semantic embeddings derived from Sentence-BERT.
To characterize lexical turnover, the authors define the lifespan of each n-gram g using its first and last observed dates: τfirst(g)=min{t∣g∈Ot(n)} and τlast(g)=max{t∣g∈Ot(n)}. The set of active n-grams on day t, At(n), includes all n-grams that have entered the lexicon and not yet exited: At(n)={g∣τfirst(g)≤t≤τlast(g)}. Birth and death rates are then computed relative to the active vocabulary: the birth rate Rbirth(n)(t) is the proportion of new n-grams among active ones on day t, while the death rate Rdeath(n)(t) measures the proportion of n-grams that exited the lexicon relative to the active set on the prior day.
For semantic evolution, the authors compute a Daily Semantic Centroid ct as the mean embedding of all posts on day t: ct=Nt1∑p∈Ptvp. Macro-stability is captured via Centroid Similarity Scentroid(ti,tj)=cos(cti,ctj), which reflects the consistency of the aggregate discourse direction. Micro-homogeneity is measured via Pairwise Similarity Spairwise(ti,tj), the mean cosine similarity across all post pairs between two days, indicating how tightly clustered individual posts are within the semantic space.
To assess structural convergence, the authors analyze local neighborhood densities. For each post p on day t, they compute its Local Neighborhood Similarity SK(p) as the mean cosine similarity to its K-nearest neighbors (with K=10). Temporal stability of these densities is quantified using Jensen-Shannon Divergence between the SK distributions of consecutive days.
At the agent level, semantic drift is measured by partitioning each agent’s post history into early and late halves, computing centroids ca(early) and ca(late), and defining Individual Semantic Drift Da=1−cos(ca(early),ca(late)). Drift Direction Consistency Saconsistency evaluates alignment with the global drift vector dˉ, while Movement Toward Societal Centroid ΔSa measures whether agents converge toward the global discourse center over time.
Feedback adaptation is evaluated via a sliding window approach. For each window Wk, posts are partitioned into top- and bottom-performing subsets based on net feedback scores. Semantic centroids ctop and cbot are computed, and Net Progress NP=Δbot−Δtop quantifies whether the agent’s next window moves closer to successful content and away from unsuccessful content, where Δtop=dist(cnext,ctop)−dist(ccurr,ctop) and Δbot=dist(cnext,cbot)−dist(ccurr,cbot), with dist(x,y)=1−cos(x,y). Statistical significance is assessed against a permutation baseline that shuffles feedback scores.
Finally, interaction effects are studied using an event-study design. For each interaction event (a,t,p∗), the authors compare the agent’s pre- and post-interaction content windows Wpre and Wpost relative to the target post’s embedding v∗. Interaction Influence Δinteract=S(Wpost,v∗)−S(Wpre,v∗) captures semantic convergence toward the target. A Random Baseline, constructed by sampling non-interacted posts from the same day, controls for global topic drift.
Experiment
- Moltbook achieves global semantic stability with persistent local diversity, maintaining a stable center while posts remain widely dispersed and heterogeneous.
- Agents show strong individual inertia, with minimal adaptation to feedback or interactions; their semantic trajectories stem from intrinsic properties rather than social co-evolution.
- No stable influence anchors emerge: structurally, influence remains transient with no persistent supernodes; cognitively, agents lack shared recognition or consensus on influential figures.
- Lexical innovation stabilizes after an initial burst, sustaining steady turnover rather than convergence, indicating a dynamic equilibrium in content evolution.
- Local semantic density stabilizes early without progressive tightening, preserving consistent internal diversity despite societal growth.
- Participation does not drive socialization: agents do not converge toward societal norms, adapt to feedback, or align with interaction partners.
- Structural influence remains decentralized, with influence diffusing across the network and no enduring hierarchy forming over time.
- Cognitive consensus is absent: probing reveals fragmented, inconsistent, or invalid references to influential users or posts, with no shared social memory.
The authors use daily interaction graphs to track structural influence in Moltbook, observing rapid growth in nodes, edges, and total weight over time. Despite increasing interaction volume, influence remains decentralized, with no persistent supernodes or consolidation of authority. Results show that high activity does not translate into stable leadership, reinforcing the society’s fluid and fragmented nature.
