Command Palette
Search for a command to run...
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5: from Vibe Coding to Agentic Engineering
Abstract
We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
One-sentence Summary
GLM-5, developed by Zhipu AI and Tsinghua University, advances agentic engineering via DSA and asynchronous RL, cutting costs while excelling in long-context coding tasks and outperforming top models on real-world software benchmarks, marking a leap in autonomous, reasoning-driven AI development.
Key Contributions
- GLM-5 introduces a new foundation model that shifts from “vibe coding” to agentic engineering, leveraging DSA to cut training and inference costs while preserving long-context performance, building on its predecessor’s ARC capabilities.
- It deploys an asynchronous reinforcement learning infrastructure and novel agent RL algorithms that decouple generation from training and improve learning from complex, long-horizon interactions, boosting post-training efficiency and alignment.
- GLM-5 achieves state-of-the-art results across 8 major agentic, reasoning, and coding benchmarks and outperforms prior models on real-world end-to-end software engineering tasks, with open-sourced code and models available for community use.
Introduction
The authors leverage GLM-5 to shift from “vibe coding”—where models mimic patterns without deep reasoning—to “agentic engineering,” enabling autonomous, end-to-end software development. Prior models struggled with high computational costs and limited long-horizon reasoning during reinforcement learning, often failing to scale efficiently in real-world coding workflows. GLM-5 introduces DSA for cost-efficient training and inference, plus an asynchronous RL infrastructure that decouples generation from training, allowing better learning from complex, multi-step interactions. The result is state-of-the-art performance on agentic and coding benchmarks, with real-world engineering capability that rivals top proprietary models—all while being open-sourced to accelerate community-driven advances in efficient, autonomous AI agents.
Dataset
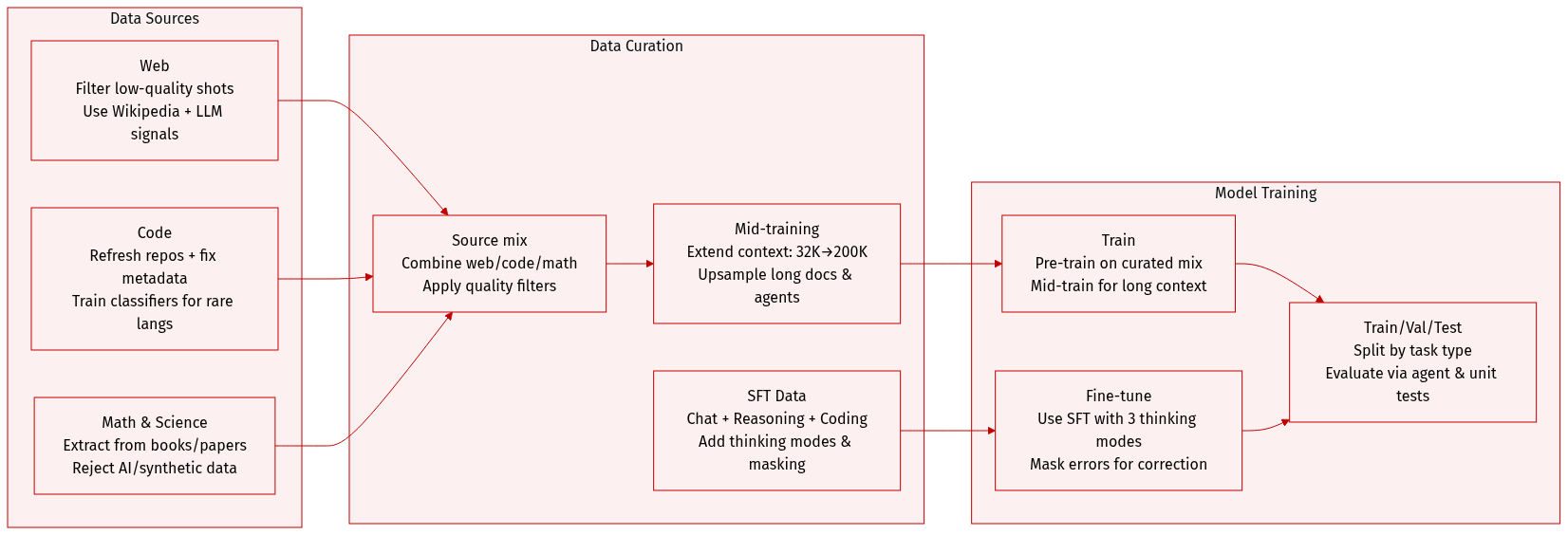
The authors use a multi-stage, highly curated dataset to train and evaluate GLM-5, with distinct compositions and processing pipelines for pre-training, mid-training, and supervised fine-tuning.
-
Pre-training Data:
- Web: Built on GLM-4.5’s pipeline, enhanced with a DCLM classifier for sentence-level quality filtering and a World Knowledge classifier to extract value from medium-low-quality data using Wikipedia and LLM-labeled signals.
- Code: Expanded with refreshed snapshots from code hosting platforms and code-rich web pages, increasing unique tokens by 28%. Metadata alignment and language classification were fixed. Dedicated classifiers were trained for low-resource languages (Scala, Swift, Lua, etc.) to improve sampling.
- Math & Science: Sourced from web pages, books, and papers. Enhanced extraction pipelines and LLM scoring filter for educational content. Long documents use chunk-and-aggregate scoring. Synthetic, AI-generated, or template-based data are strictly excluded.
-
Mid-training Data:
- Extended Context: Three stages: 32K (1T tokens), 128K (500B tokens), 200K (50B tokens). Long documents and synthetic agent trajectories are up-sampled in later stages.
- Software Engineering: Retains repo-level concatenation (code, diffs, issues, PRs, source files). Filtering relaxed at repo level but tightened at issue level, yielding ~10M issue-PR pairs and ~160B tokens after filtering.
- Long-context Data: Mix of natural (books, papers, filtered by PPL, deduplication, length) and synthetic data. Synthetic data uses interleaved packing and MRCR-like variants to strengthen recall in multi-turn dialogues. Diversity is progressively increased to boost long-context performance.
-
Supervised Fine-tuning (SFT) Data:
- Covers three categories: General Chat (QA, writing, role-play, translation, multi-turn), Reasoning (math, science, logic), and Coding & Agent (frontend/backend code, tool calling, agents).
- Context extended to 202,752 tokens. Supports three thinking modes: Interleaved (think before every response), Preserved (retain reasoning across turns), and Turn-level (control reasoning per turn).
- General Chat: Optimized for logic and conciseness; role-play data expanded across languages and configurations, filtered via human and automated checks.
- Reasoning: Verifiable problems synthesized via rejection sampling; math/science problems filtered by difficulty (challenging for GLM-4.7).
- Coding & Agent: Uses real-world execution environments. Trajectories include masked errors to teach error correction. Enhanced with expert RL and rejection sampling.
-
Agent Environment Construction:
- Software Engineering: Over 10k verifiable environments built via RepoLaunch, covering 9 languages. Uses LLM to parse test logs and extract F2P/P2P cases.
- Terminal Environments: Built via two pipelines: from seed tasks (LLM brainstorming → Harbor instantiation → refine agent) and from web corpus (quality-filtered pages → LLM constructs and self-verifies tasks in Harbor format).
- Search Tasks: Built from 2M+ web pages. LLM constructs Web Knowledge Graph, generates multi-hop QA, and filters via three stages: removes easily answerable questions, filters basic-agent-solvable ones, and uses bidirectional verification for answer consistency.
-
Evaluation Benchmarks:
- Frontend: CC-Bench-V2 uses Agent-as-a-Judge (Playwright + bash) to simulate user interactions. Metrics: BSR (build success), ISR (task completion), CSR (check-item pass rate). 220 tasks across 7 scenarios and 3 tech stacks.
- Backend: 85 real-world tasks across 6 languages. Evaluated via Dockerized unit tests; Pass@1 required.
- Long-horizon: Tests context retention over multi-step PR chains, evaluated via unit tests + Agent-as-a-Judge.
- Translation: ZMultiTransBench (1,220 samples, 7 language pairs) and MENT-SNS (753 pairs) evaluated via GPT-4.1 pairwise comparison.
- Dialogue: LMArena (community Elo ratings) and ZMultiDialBench (141 human-scored multilingual samples).
- Instruction Following: IF-Badcase (450 real-user failure cases), IF-Bench (objective constraints), MultiChallenge (multi-turn reasoning).
- World Knowledge: SimpleQA (English) and Chinese SimpleQA (6 domains, 99 subtopics) for factuality.
- Tool Calling: ToolCall-Badcase (200 curated cases) evaluating tool selection and argument correctness.
Method
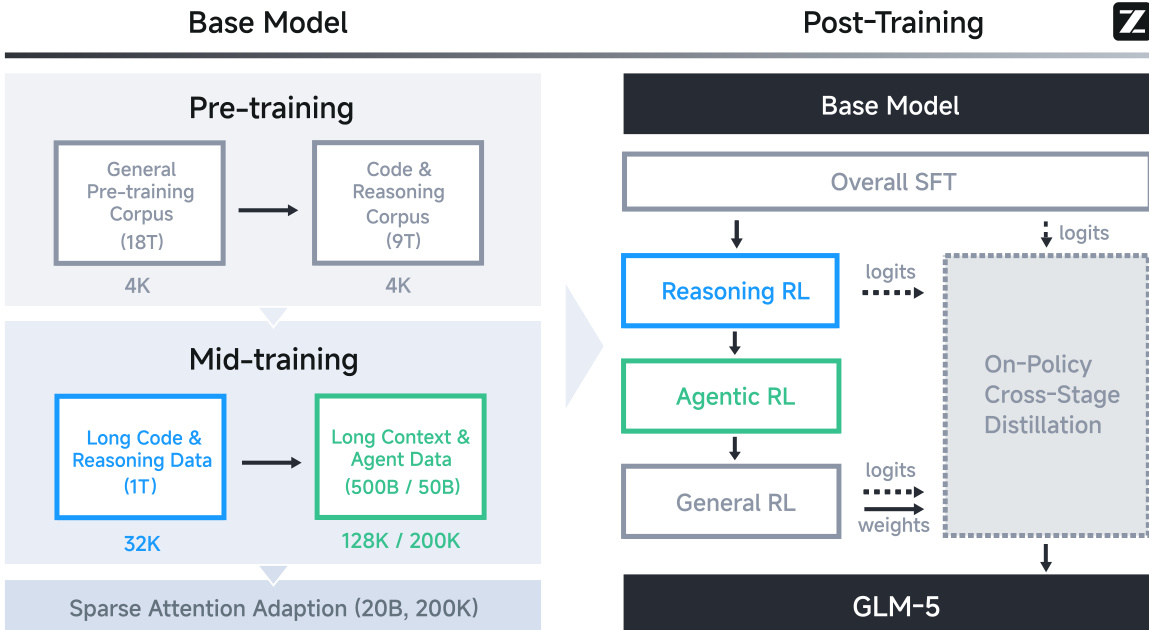
The authors leverage a multi-stage training pipeline to develop GLM-5, beginning with a base model pre-trained on a 28.5 trillion token budget and culminating in a post-training phase that aligns the model for agentic, reasoning, and human-style interaction. The overall framework is structured into two major phases: base model construction and post-training refinement, as illustrated in the framework diagram.
In the base model phase, training proceeds through pre-training and mid-training stages. Pre-training first exposes the model to a 18 trillion token general corpus followed by a 9 trillion token code and reasoning corpus, both processed with a 4K context window. Mid-training then adapts the model using 1 trillion tokens of long code and reasoning data (32K context) and 500 billion tokens of long-context and agent data (128K/200K context). This phase is followed by sparse attention adaptation over 20 billion tokens at 200K context length, preparing the model for efficient long-context inference.
The post-training phase adopts a progressive alignment strategy. It begins with an overall supervised fine-tuning (SFT) stage that introduces interleaved thinking modes, as depicted in the figure below. This is followed by specialized reinforcement learning (RL) stages: Reasoning RL, which targets mathematical, scientific, coding, and tool-integrated reasoning; Agentic RL, which optimizes for software engineering, terminal, and search agent tasks; and General RL, which refines foundational correctness, emotional intelligence, and task-specific quality. The final stage employs on-policy cross-stage distillation, using logits and weights from prior stages to recover and consolidate capabilities without regression.
The architecture of GLM-5 scales to 256 experts and 80 layers, yielding a 744B parameter model with 40B active parameters. To manage communication overhead in expert parallelism, the authors employ Multi-latent Attention (MLA), which reduces key-value vector dimensions for memory and speed benefits during long-context processing. However, MLA initially underperforms compared to Grouped-Query Attention (GQA-8). To close this gap, the authors introduce Muon Split, a variant of the Muon optimizer that applies matrix orthogonalization to per-head projection matrices rather than global ones, enabling head-specific update scales. This adaptation, combined with a head dimension increase to 256 and head count reduction, yields MLA-256—a variant that matches GQA-8 performance while reducing decoding computation.
For multi-token prediction (MTP), GLM-5 shares parameters across three MTP layers during training to maintain memory efficiency while improving inference acceptance rates. This design allows the model to predict two tokens per step without increasing memory footprint, outperforming DeepSeek-V3.2 in acceptance length under identical speculative steps.
The post-training infrastructure, named slime, supports end-to-end RL at scale. It enables flexible rollout customization via server-based HTTP APIs, tail-latency optimization through FP8 inference and MTP, and robustness via heartbeat-driven fault tolerance. For agentic RL, the authors implement a fully asynchronous framework with a Multi-Task Rollout Orchestrator that decouples inference and training engines. This design mitigates GPU idle time during long-horizon rollouts and supports joint training across heterogeneous tasks by standardizing trajectories into a unified message-list format.
To stabilize asynchronous RL, the authors introduce a Token-in-Token-out (TITO) gateway that preserves exact token-level correspondence between rollout and training, avoiding re-tokenization mismatches. They also employ Direct Double-sided Importance Sampling, which clips token-level importance ratios to [1−εℓ, 1+εh] to control off-policy bias without tracking historical policies. Additionally, DP-aware routing ensures KV-cache locality under data parallelism by mapping rollout IDs to fixed DP ranks via consistent hashing, reducing prefill overhead for multi-turn agentic workloads.
In the General RL stage, the authors decompose optimization into three dimensions: foundational correctness, emotional intelligence, and task-specific quality. A hybrid reward system integrates rule-based functions, outcome reward models (ORMs), and generative reward models (GRMs) to balance precision, efficiency, and robustness. Human-authored responses are explicitly incorporated as stylistic anchors to steer the model toward natural, human-aligned output patterns.
For slide generation, a self-improving pipeline combines supervised fine-tuning with reinforcement learning guided by a multi-level reward system. Level-1 rewards enforce valid HTML markup and suppress hallucinated images; Level-2 evaluates runtime rendering properties like element geometry; and Level-3 incorporates perceptual features such as whitespace patterns. Rejection sampling and masking-based refinement further enhance data quality and training efficiency, leading to a 92% compliance rate with 16:9 aspect ratio and significant human-evaluated gains in content, layout, and aesthetics.
Finally, to deploy GLM-5 on Chinese chip infrastructure, the authors implement mixed-precision W4A8 quantization, high-performance fusion kernels (Lightning Indexer, Sparse Flash Attention, MLAPO), and specialized inference engine optimizations including asynchronous scheduling, context management, and multi-token prediction. These co-optimizations enable single-node performance comparable to dual-GPU international clusters while reducing long-sequence deployment costs by 50%.
Experiment
- DSA training successfully adapts dense base models to sparse attention without performance loss, validating that 90% of long-context attention entries are redundant while cutting GPU costs by half.
- GLM-5 achieves state-of-the-art performance among open-source models on reasoning, coding, and agentic benchmarks, narrowing the gap with top proprietary models like Claude Opus and Gemini.
- On long-context reasoning (LongBench v2) and tool-use tasks (MCP-Atlas, Tool-Decathlon), GLM-5 matches or exceeds proprietary models, demonstrating strong agentic and multi-step planning capabilities.
- In long-horizon coding tasks, GLM-5 significantly improves over its predecessor but still trails Claude Opus due to compounding errors, highlighting the need for better context consistency and self-correction.
- Real-world evaluations show consistent gains in machine translation, multilingual dialogue, instruction following, world knowledge, and tool-calling, aligning with user-perceived quality improvements.
- The anonymous “Pony Alpha” release validated GLM-5’s frontier-level performance in coding and agentic workflows, earning community recognition and dispelling skepticism about Chinese LLM competitiveness.
The authors use a sparse attention mechanism to maintain strong long-context performance while significantly reducing computational cost. Results show that their approach preserves near-equivalent accuracy to full attention at shorter contexts and outperforms other sparse patterns at longer lengths, validating the efficiency of content-aware token selection. This enables practical deployment of models handling 128K tokens with roughly half the GPU resources.

The authors use sparse attention mechanisms to maintain long-context performance while reducing computational cost, showing that most attention entries in extended sequences are redundant. Results show that models trained with dynamic sparse attention match dense counterparts in benchmark accuracy while cutting GPU usage nearly in half. This efficiency enables practical deployment for reasoning-heavy agents handling 128K context lengths.

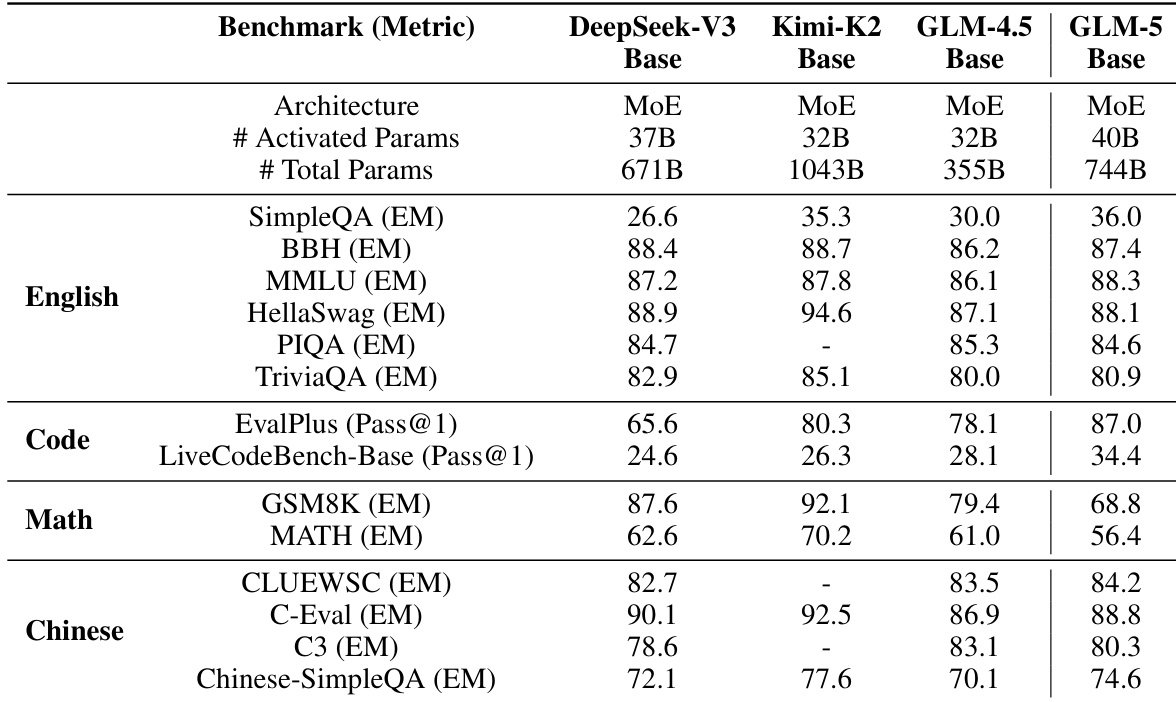
The authors evaluate GLM-5’s base model against other large open-source models across English, code, math, and Chinese benchmarks, showing consistent improvements over GLM-4.5 and competitive performance relative to DeepSeek-V3 and Kimi-K2. Results indicate GLM-5’s base model achieves higher scores in most categories, particularly in code and Chinese tasks, while maintaining a larger parameter count. These findings suggest the model’s architecture and training approach effectively enhance general capabilities without sacrificing efficiency.
The authors use DeepSeek Sparse Attention (DSA) to adapt a dense base model for long-context tasks, achieving performance comparable to the original model while reducing attention computation by 1.5-2x. Results show that DSA maintains strong accuracy across context lengths up to 128K, validating that most attention entries in long sequences are redundant. This efficiency enables cost-effective deployment for reasoning-heavy agents without sacrificing benchmark performance.

The authors use a sparse attention mechanism to maintain long-context performance while reducing computational cost, showing that most attention entries in long sequences are redundant. Results show that the adapted model matches the dense baseline’s benchmark performance despite significantly lower GPU usage. This efficiency enables practical deployment for reasoning-heavy agents handling 128K context lengths.
