Command Palette
Search for a command to run...
TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for Robotics
TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for Robotics
Shirui Chen Cole Harrison Ying-Chun Lee Angela Jin Yang Zhongzheng Ren Lillian J. Ratliff Jiafei Duan Dieter Fox Ranjay Krishna
Abstract
While Vision-Language-Action (VLA) models have seen rapid progress in pretraining, their advancement in Reinforcement Learning (RL) remains hampered by low sample efficiency and sparse rewards in real-world settings. Developing generalizable process reward models is essential for providing the fine-grained feedback necessary to bridge this gap, yet existing temporal value functions often fail to generalize beyond their training domains. We introduce TOPReward, a novel, probabilistically grounded temporal value function that leverages the latent world knowledge of pretrained video Vision-Language Models (VLMs) to estimate robotic task progress. Unlike prior methods that prompt VLMs to directly output progress values, which are prone to numerical misrepresentation, TOPReward extracts task progress directly from the VLM's internal token logits. In zero-shot evaluations across 130+ distinct real-world tasks and multiple robot platforms (e.g., Franka, YAM, SO-100/101), TOPReward achieves 0.947 mean Value-Order Correlation (VOC) on Qwen3-VL, dramatically outperforming the state-of-the-art GVL baseline which achieves near-zero correlation on the same open-source model. We further demonstrate that TOPReward serves as a versatile tool for downstream applications, including success detection and reward-aligned behavior cloning.
One-sentence Summary
Researchers from UW and NVIDIA propose TOPReward, a probabilistic temporal value function using pretrained VLM token logits to estimate robotic task progress, overcoming prior numerical misrepresentation issues and achieving 0.947 VOC across 130+ real-world tasks, enabling zero-shot reward modeling and behavior cloning.
Key Contributions
- TOPReward introduces a zero-shot, probabilistically grounded method to estimate robotic task progress by extracting internal token logits from pretrained video VLMs, bypassing unreliable text-based numerical outputs and enabling generalization across real-world tasks without fine-tuning.
- Evaluated on ManiRewardBench—a diverse benchmark of 130+ real-world tasks across Franka, YAM, and SO-100/101 platforms—TOPReward achieves 0.947 mean Value-Order Correlation on Qwen3-VL, vastly outperforming GVL which shows near-zero correlation on the same open-source model.
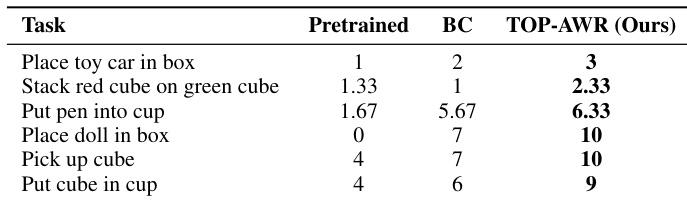
- TOPReward enables downstream RL and imitation learning applications, including success detection and advantage-weighted behavior cloning, improving real-world task success rates (e.g., 10/10 vs. 7/10 baseline) without requiring task-specific demonstrations or additional training.
Introduction
The authors leverage pretrained video Vision-Language Models (VLMs) to generate zero-shot reward signals for robotics, addressing the critical bottleneck of sparse, hand-crafted rewards in real-world reinforcement learning. Prior methods either require costly task-specific fine-tuning or fail to generalize across robot platforms and open-source models, especially when relying on autoregressive text generation for progress estimation—which suffers from numerical instability. TOPReward’s key innovation is bypassing text output entirely: it extracts task progress directly from the VLM’s internal token logits by posing a binary completion query and measuring the model’s confidence in the “yes” token over time. This yields a dense, well-calibrated progress signal that generalizes across 130+ real-world tasks and multiple robot embodiments, enabling applications like success detection and reward-aligned behavior cloning without any additional training.
Dataset
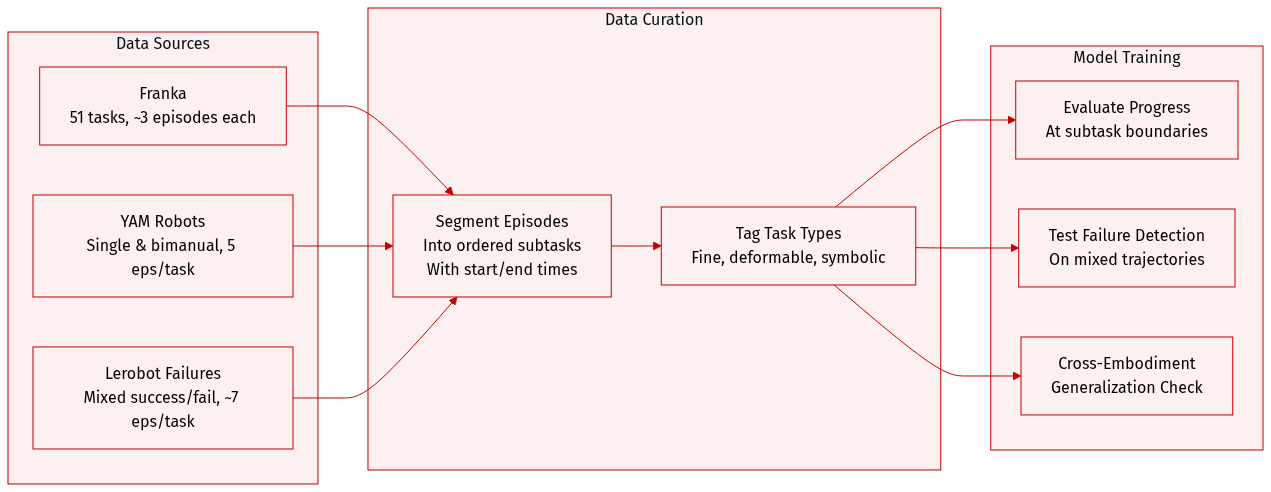
The authors use ManiRewardBench, a benchmark designed to evaluate reward models on real-world robotic manipulation, covering 130 diverse tasks across four robot platforms: Franka, SO-100/101, single-arm YAM, and bimanual YAM. The dataset supports evaluation of progress sensitivity, completion detection, and cross-embodiment robustness.
Key subsets and their details:
- Franka dataset: 51 instruction-based tasks (e.g., rotation, cleaning, pick-and-place), mostly 3 episodes per task.
- Bimanual YAM dataset: 5 episodes per task, covering fold, stack, build, and open tasks.
- Single-arm YAM dataset: 5 episodes per task, focused on put, remove, and stack actions.
- Lerobot Bimanual: Successful demos (push, put, remove, stack), 5–10 episodes per task.
- Lerobot Failure: Mixed successful and failed trajectories, ~7 episodes per task, used to test success detection.
- Failure trajectories subset: 23 tasks with 156 total episodes, including both successful and failed attempts.
Processing and annotation:
- Each episode is manually segmented into ordered, non-overlapping subtasks (e.g., “grab object,” “place object”) with precise start and end timestamps.
- Subtask annotations enable stage-aware evaluation, allowing models to be tested on fine-grained progress understanding rather than binary success/failure.
- Tasks span fine manipulation (e.g., rotating objects by exact angles), deformable object handling (e.g., folding towels), and symbolic tasks (e.g., pressing keyboard keys in sequence).
Usage in the paper:
- The benchmark is used to evaluate reward models’ ability to detect progress, handle failures, and generalize across robot embodiments.
- The underlying data is restricted to prevent leakage; access is granted only through a controlled evaluation protocol.
- No training split or mixture ratios are specified — the dataset is used exclusively for evaluation.
Method
The authors leverage a vision-language model (VLM) to derive a temporally dense reward signal by interpreting the model’s internal token probabilities as a proxy for task completion likelihood. The core mechanism, termed TOPReward, operates by conditioning the VLM on a trajectory-instruction pair and querying the log probability of the token “True” as a scalar reward. This approach avoids reliance on instruction-following or numerical generation capabilities, instead grounding reward computation in the VLM’s pretrained next-token prediction objective.
Refer to the framework diagram: the system ingests a sequence of video frames up to time t, encoded as video tokens, and combines them with a fixed textual prompt that frames the task as a binary judgment. The prompt structure is: “video The above video shows a robot manipulation trajectory that completes the following task: {INSTRUCTION}. Decide whether the above statement is True or not. The answer is: {a}”. The VLM then computes rt=logpθ(a=True∣c(τ1:t,u)), where c(τ1:t,u) represents the video-conditioned textual context. As the trajectory unfolds, accumulating visual evidence increases the likelihood of “True”, resulting in a monotonically increasing reward signal over time.
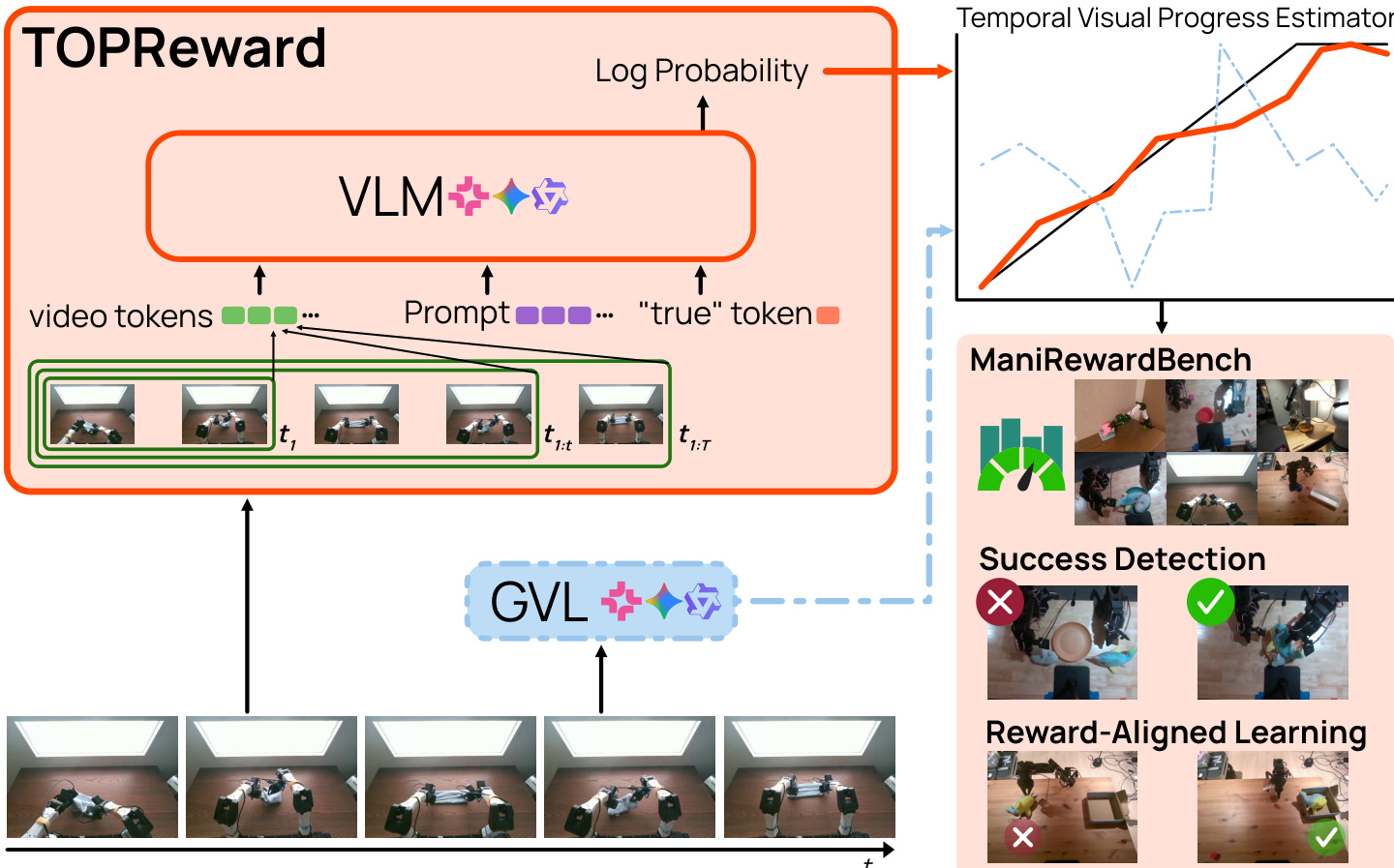
To construct a temporal progress curve, the authors sample K uniformly spaced trajectory prefixes {tk}k=1K and compute the corresponding rewards {rtk}. These rewards are then normalized via min-max scaling to produce a progress score stk∈[0,1] within each episode:
stk=maxjrtj−minjrtj+εrtk−minjrtj,where ε ensures numerical stability. This normalized score enables consistent interpretation of progress across time steps within a single trajectory.
For applications requiring per-step rewards—such as reward-aligned behavior cloning—the authors derive a dense reward signal from the progress increment:
Δtk=clip(τ⋅exp(stk−stk−1),min=0,max=δmax),where τ scales the relative weight between positive and negative progress, and δmax caps the maximum reward to prevent overemphasis on high-magnitude transitions. This formulation ensures smooth, interpretable, and actionable reward signals that align with the temporal evolution of task completion.
Experiment
- TOPReward excels in zero-shot progress estimation on large-scale robotic datasets (OXE and ManiRewardBench), outperforming GVL significantly on open-source VLMs like Qwen3-VL-8B and Molmo2-8B by leveraging logit probabilities rather than structured numerical outputs.
- It effectively detects task success in failed trajectories, where VOC-based methods fail due to rank-order insensitivity; TOPReward’s probability-based scoring achieves higher ROC-AUC, especially on open-source models.
- In real-world deployment, TOPReward improves policy learning via advantage-weighted behavior cloning, consistently surpassing standard imitation learning across six manipulation tasks.
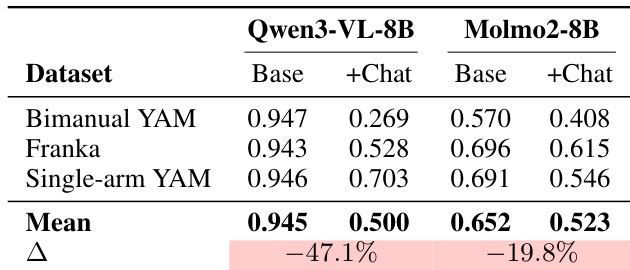
- Ablation studies reveal that enforced chat templates degrade performance, confirming sensitivity to prompt formatting, particularly for open-source models.
- Overall, TOPReward provides a robust, zero-shot progress signal by repurposing pretrained VLMs’ internal probability estimates, enabling reliable task monitoring and policy improvement without fine-tuning.
The authors use TOPReward to evaluate zero-shot progress estimation across multiple robotic datasets and find it consistently outperforms GVL on open-source models like Qwen3-VL-8B and Molmo2-8B, particularly on ManiRewardBench where it achieves near-perfect VOC scores. Results show that TOPReward’s logit-based approach better leverages pretrained video understanding capabilities compared to GVL’s text-generation method, which struggles with calibration and fails to distinguish successful from failed trajectories. On proprietary Gemini-2.5-Pro, performance reverses due to enforced chat templates, highlighting the sensitivity of logit-based methods to prompt formatting.
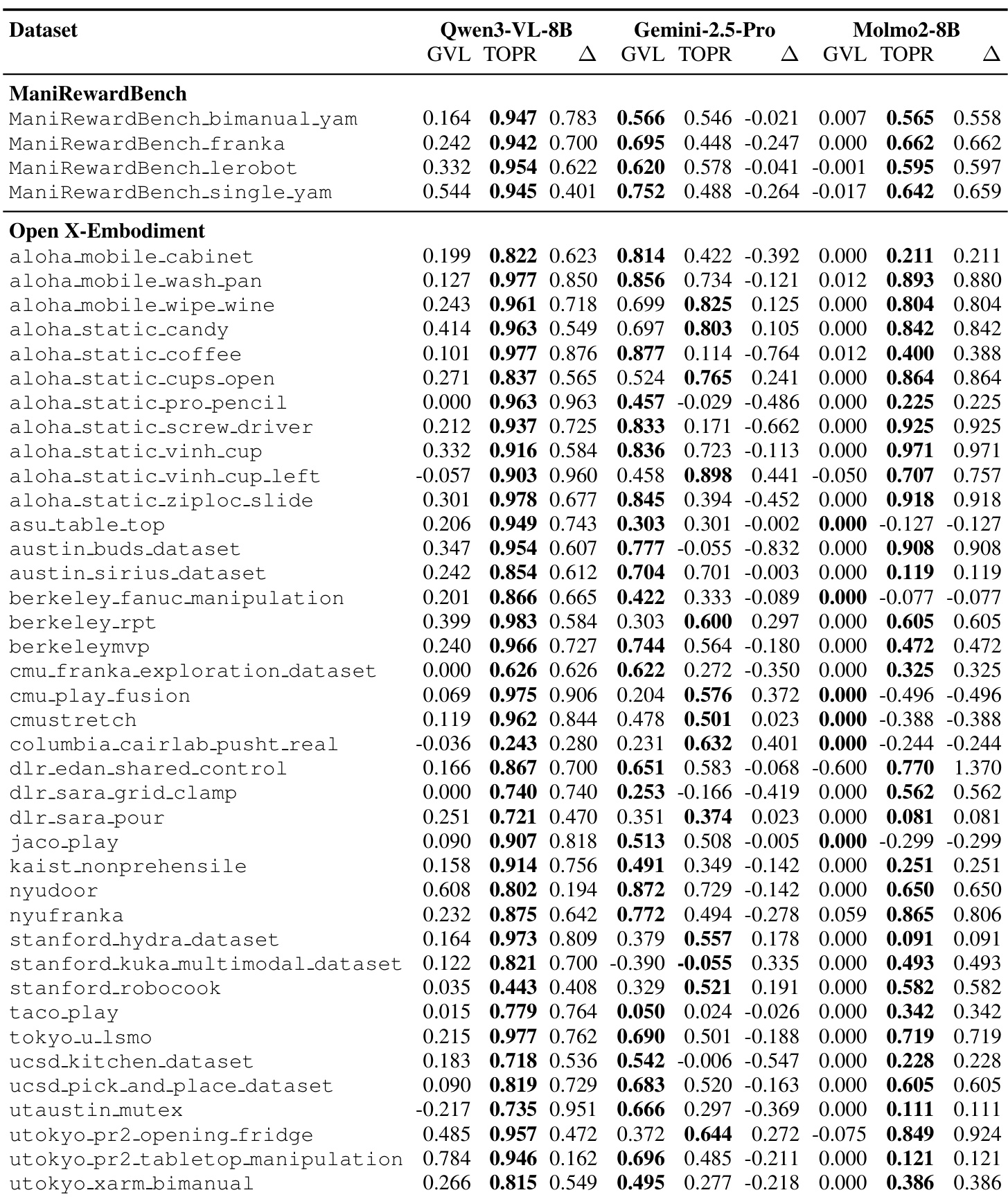
The authors use TOPReward to estimate robotic task progress by leveraging token probabilities from video-language models, achieving substantially higher Value-Order Correlation than the GVL baseline on open-source models. Results show that TOPReward consistently outperforms GVL on Qwen3-VL-8B and Molmo2-8B, while underperforming on Gemini-2.5-Pro due to enforced chat template constraints. This highlights that the logit-based approach effectively unlocks implicit progress estimation in open-source VLMs where structured numerical generation fails.

Results show that TOPReward outperforms GVL on the Qwen3-VL-8B model, achieving a higher ROC-AUC for success detection, while both methods perform comparably on Gemini-2.5-Pro. This indicates that TOPReward’s probability-based approach is more effective than VOC-based methods for identifying successful trajectories, particularly when using open-source video-language models.

The authors evaluate how chat templates affect TOPReward’s performance across different video-language models, finding that enforced chat formatting significantly degrades progress estimation accuracy. On Qwen3-VL-8B, the mean VOC drops by 47.1% when using the chat template, while Molmo2-8B sees a 19.8% decline, indicating the logit-based approach is highly sensitive to prompt structure. These results confirm that prompt engineering directly impacts the reliability of zero-shot progress signals derived from VLM token probabilities.
The authors use TOPReward to compute advantage weights for behavior cloning in real-world robotic tasks, showing consistent performance gains over standard behavior cloning across six manipulation tasks. Results indicate that TOP-AWR fine-tuning improves task completion rates, with partial success scores frequently doubling or tripling those of the baseline. This demonstrates that the progress signal derived from token probabilities effectively guides policy improvement without requiring task-specific training.