Command Palette
Search for a command to run...
DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning
DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning
Abstract
Reinforcement learning with verifiers (RLVR) is a central paradigm for improving large language model (LLM) reasoning, yet existing methods often suffer from limited exploration. Policies tend to collapse onto a few reasoning patterns and prematurely stop deep exploration, while conventional entropy regularization introduces only local stochasticity and fails to induce meaningful path-level diversity, leading to weak and unstable learning signals in group-based policy optimization. We propose DSDR, a Dual-Scale Diversity Regularization reinforcement learning framework that decomposes diversity in LLM reasoning into global and coupling components. Globally, DSDR promotes diversity among correct reasoning trajectories to explore distinct solution modes. Locally, it applies a length-invariant, token-level entropy regularization restricted to correct trajectories, preventing entropy collapse within each mode while preserving correctness. The two scales are coupled through a global-to-local allocation mechanism that emphasizes local regularization for more distinctive correct trajectories. We provide theoretical support showing that DSDR preserves optimal correctness under bounded regularization, sustains informative learning signals in group-based optimization, and yields a principled global-to-local coupling rule. Experiments on multiple reasoning benchmarks demonstrate consistent improvements in accuracy and pass@k, highlighting the importance of dual-scale diversity for deep exploration in RLVR. Code is available at https://github.com/SUSTechBruce/DSDR.
One-sentence Summary
Zhongwei Wan, Yun Shen, and colleagues from multiple institutions propose DSDR, a dual-scale diversity regularization method enhancing exploration in LLM reasoning by balancing local and global diversity, outperforming prior techniques in complex reasoning tasks without requiring architectural changes.
Key Contributions
- DSDR introduces a dual-scale exploration framework for LLM reasoning that separates global diversity (across distinct correct solution paths) from local diversity (within each path), addressing the collapse into homogeneous reasoning patterns that plagues existing RLVR methods.
- The method couples these scales via a global-to-local allocation mechanism that applies length-invariant, correctness-restricted token-level entropy only to more distinctive correct trajectories, preserving solution quality while preventing intra-mode entropy collapse.
- Theoretical analysis confirms DSDR maintains optimal correctness and sustains informative learning signals in group-based RLVR, with empirical validation across reasoning benchmarks showing consistent gains in accuracy and pass@k.
Introduction
The authors leverage reinforcement learning with verifiers (RLVR) to enhance LLM reasoning but observe that existing methods suffer from poor exploration, collapsing into a few homogeneous reasoning patterns that hurt pass@k performance and generalization. Prior entropy-based or diversity-focused techniques either inject only local randomness or treat global and local diversity in isolation, failing to sustain meaningful, correctness-aligned exploration across scales. Their main contribution is DSDR, a dual-scale framework that jointly optimizes global diversity among correct trajectories and local token-level entropy regularization—restricted to correct paths and allocated adaptively based on trajectory distinctiveness—thereby preserving correctness while strengthening learning signals and enabling deeper, more stable exploration.
Method
The authors leverage a dual-scale diversity regularization framework, DSDR, built atop Group Relative Policy Optimization (GRPO), to enhance exploration and prevent collapse in reinforcement learning with verifiable rewards (RLVR) for reasoning tasks. The core innovation lies in coupling global trajectory-level diversity with local token-level entropy regularization, ensuring that exploration is both broad across distinct solution modes and fine-grained within high-value paths.
The overall training protocol follows a group-based sampling scheme: for each problem input, the policy model generates a group of candidate rollouts, which are then evaluated by a verifier to yield binary rewards. DSDR augments this process with two complementary diversity signals. At the global scale, it computes a bounded diversity score for each rollout by combining semantic dissimilarity—derived from frozen text embeddings—and formula-level uniqueness, which captures distinct symbolic manipulations. This global diversity score is then used to shape rewards exclusively for correct rollouts, preventing reward hacking and preserving the correctness objective while introducing controlled dispersion among valid solutions. This mechanism ensures that even when all sampled trajectories are correct, the group-relative advantages remain non-degenerate, maintaining a meaningful learning signal.
Refer to the framework diagram, which illustrates how global diversity scores are computed from multiple rollout trajectories and then fed into a global-to-local coupling module. This module allocates local regularization strength via a diversity-weighted softmax over correct rollouts. The temperature parameter in the softmax controls the concentration of exploration: higher values focus regularization on the most globally distinctive correct solutions, while lower values distribute it more uniformly. This coupling ensures that local entropy expansion is applied where it is most beneficial—around trajectories that are already rare within the group—thereby populating underexplored regions of the correct solution manifold.
As shown in the figure below, the local regularization component operates at the token level, encouraging controlled entropy along positive trajectories. It uses a time-averaged conditional entropy objective, re-expressed via importance sampling to remain differentiable and computable from the same rollouts used for policy update. This formulation avoids length bias and restricts entropy promotion to correct paths only, ensuring that exploration refines rather than corrupts valid reasoning. The final DSDR objective combines the GRPO policy loss, computed with augmented rewards, and the local entropy regularizer, weighted by the coupling coefficients derived from global diversity.
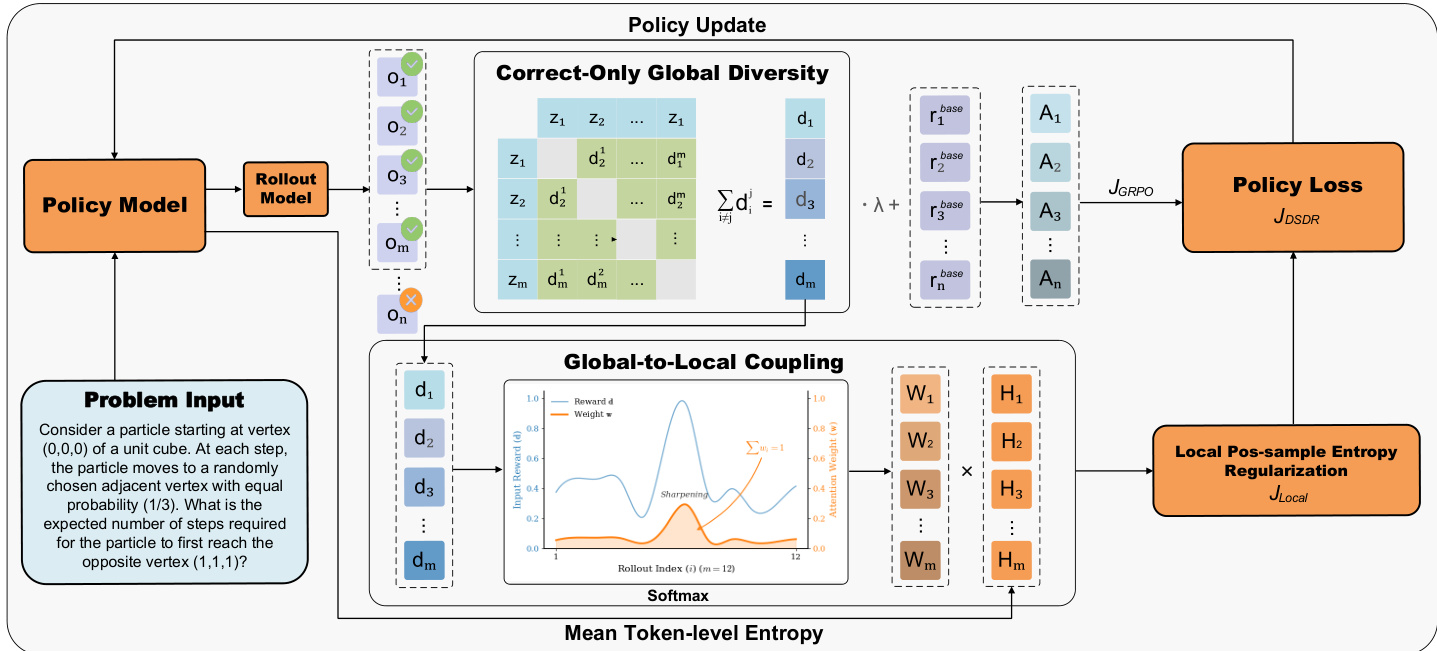
The architecture’s dual-scale design is further visualized in the solution space comparison: while baseline exploration tends to collapse into a single correct mode, DSDR’s coupled regularization expands probability mass around multiple distinct correct trajectories, as indicated by the green arrows and broader basins in the right-hand plot. This structured exploration enables the model to discover diverse reasoning paths without sacrificing correctness, addressing a key limitation of standard RLVR methods.

Experiment
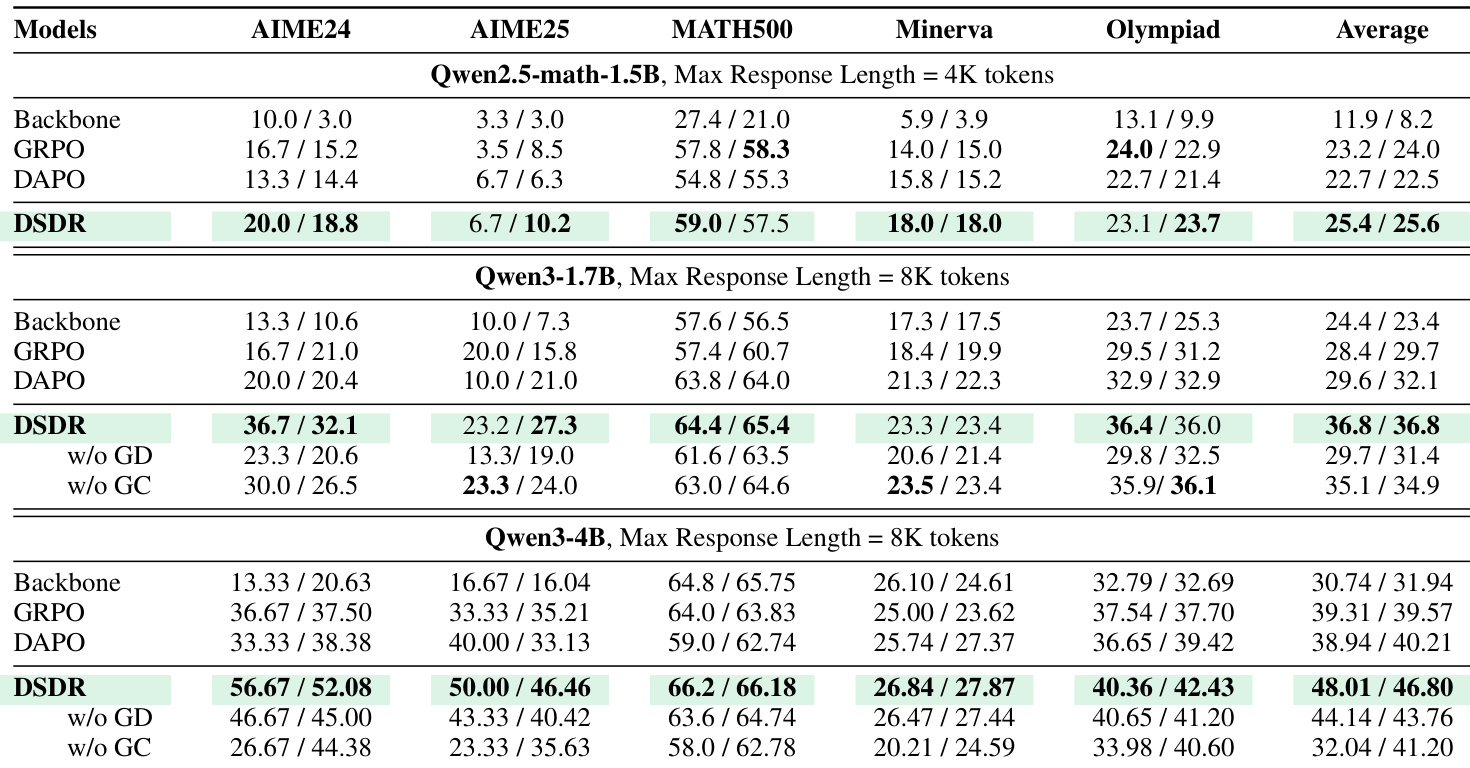
- DSDR consistently outperforms baseline methods (Backbone, GRPO, DAPO) across multiple math reasoning benchmarks and model scales, showing scalable gains in both Pass@1 and Avg@16, indicating improved solution stability and quality.
- The method excels on challenging benchmarks like AIME2024/2025 and Olympiad problems, where multiple valid reasoning paths exist, by preserving informative learning signals and mitigating reward-variance collapse.
- DSDR expands the diversity of correct reasoning trajectories rather than sharpening a single solution, leading to stronger and more reliable Pass@k performance across k values, especially on benchmarks with sparse correct solutions.
- Ablation studies confirm that both global diversity (GD) and global-to-local coupling (GC) are essential: removing either degrades performance, particularly on complex benchmarks, showing their complementary roles in promoting targeted exploration.
- Training dynamics reveal that DSDR maintains balanced exploration—higher entropy without instability—by combining correct-only global diversity with local regularization, preventing mode collapse while sustaining semantic and formula-level diversity.
- Diversity analysis shows DSDR generates responses with broader reasoning strategies without sacrificing correctness, validated by higher diversity scores and pass@32 performance compared to DAPO.
- Hyperparameter sensitivity tests indicate DSDR is stable within moderate regularization ranges, with λℓ = 0.001 and λd = 0.001 yielding optimal and consistent performance across benchmarks.
- Case studies demonstrate DSDR’s ability to produce multiple distinct correct solutions per problem, while DAPO tends toward limited or erroneous reasoning patterns, confirming DSDR’s effectiveness in controlled, correctness-preserving exploration.
The authors use DSDR to enhance mathematical reasoning in large language models by promoting diversity among correct solution trajectories. Results show consistent improvements over baseline methods across multiple benchmarks and model sizes, with gains becoming more pronounced as model capacity increases. Ablation studies confirm that both global diversity and global-to-local coupling are essential for maintaining stable exploration and preventing reward collapse.