Command Palette
Search for a command to run...
ManCAR: Manifold-Constrained Latent Reasoning with Adaptive Test-Time Computation for Sequential Recommendation
ManCAR: Manifold-Constrained Latent Reasoning with Adaptive Test-Time Computation for Sequential Recommendation
Kun Yang Yuxuan Zhu Yazhe Chen Siyao Zheng Bangyang Hong Kangle Wu Yabo Ni Anxiang Zeng Cong Fu Hui Li
Abstract
Sequential recommendation increasingly employs latent multi-step reasoning to enhance test-time computation. Despite empirical gains, existing approaches largely drive intermediate reasoning states via target-dominant objectives without imposing explicit feasibility constraints. This results in latent drift, where reasoning trajectories deviate into implausible regions. We argue that effective recommendation reasoning should instead be viewed as navigation on a collaborative manifold rather than free-form latent refinement. To this end, we propose ManCAR (Manifold-Constrained Adaptive Reasoning), a principled framework that grounds reasoning within the topology of a global interaction graph. ManCAR constructs a local intent prior from the collaborative neighborhood of a user's recent actions, represented as a distribution over the item simplex. During training, the model progressively aligns its latent predictive distribution with this prior, forcing the reasoning trajectory to remain within the valid manifold. At test time, reasoning proceeds adaptively until the predictive distribution stabilizes, avoiding over-refinement. We provide a variational interpretation of ManCAR to theoretically validate its drift-prevention and adaptive test-time stopping mechanisms. Experiments on seven benchmarks demonstrate that ManCAR consistently outperforms state-of-the-art baselines, achieving up to a 46.88% relative improvement w.r.t. NDCG@10. Our code is available at https://github.com/FuCongResearchSquad/ManCAR.
One-sentence Summary
Researchers from institutions including Tsinghua University and Alibaba propose ManCAR, a manifold-constrained reasoning framework that grounds sequential recommendation in collaborative graph topology, preventing latent drift via adaptive test-time refinement and outperforming baselines by up to 46.88% in NDCG@10.
Key Contributions
- ManCAR introduces a manifold-constrained reasoning framework for sequential recommendation, using collaborative neighborhoods from an interaction graph to define feasible regions on the item probability simplex, thereby preventing latent drift during multi-step latent refinement.
- The method incorporates a variational interpretation that theoretically validates its drift-prevention mechanism and enables adaptive test-time stopping via convergence of the predictive distribution, avoiding unnecessary over-refinement.
- Evaluated on seven benchmarks, ManCAR consistently outperforms state-of-the-art baselines, achieving up to a 46.88% relative gain in NDCG@10, demonstrating both effectiveness and efficiency in real-world recommendation scenarios.
Introduction
The authors leverage latent multi-step reasoning to enhance sequential recommendation, treating it as a process of navigating a collaborative manifold defined by user-item interaction graphs rather than unconstrained latent refinement. Prior methods suffer from latent drift—where reasoning trajectories wander into implausible regions—because they optimize only for target alignment without enforcing feasibility constraints. ManCAR addresses this by grounding reasoning within a manifold derived from a user’s collaborative neighborhood, using a variational framework to align latent states with a graph-induced prior and adaptively stopping computation when predictions stabilize. This approach prevents drift, improves generalization, and achieves up to 46.88% relative gains in NDCG@10 across seven benchmarks.
Dataset

- The authors use seven sub-category datasets from the Amazon 2023 Reviews corpus: CDs & Vinyl, Video & Games, Office Products, Arts Crafts & Sewing, Grocery & Gourmet Food, Musical Instruments, and Toys & Games.
- Each dataset treats ratings above 3 as positive feedback. Users with fewer than 10 interactions are filtered from CDs; fewer than 5 from all others.
- The official absolute-timestamp split is adopted, and each user’s interaction history is truncated to a maximum length of 50 items.
- The datasets are used for training and evaluation with Recall@K and NDCG@K (K=5,10) to measure retrieval coverage and ranking quality.
- No mixture ratios are applied; each subset is evaluated independently.
- No cropping or image-based processing is involved — all data is textual interaction sequences.
- Metadata includes user-item interactions, timestamps, and ratings; no additional metadata is constructed beyond filtering and truncation.
Method
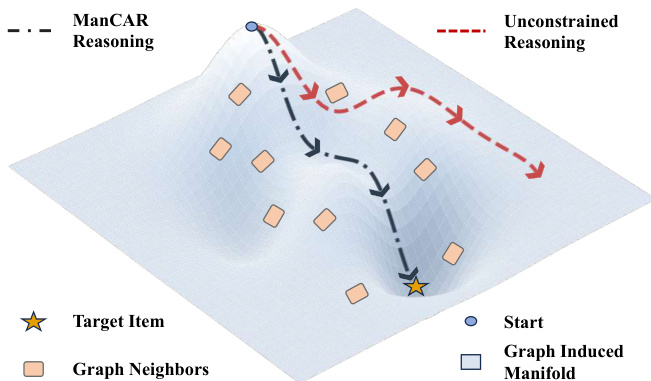
The authors leverage a geometrically grounded framework called ManCAR to constrain latent reasoning trajectories within a collaborative manifold derived from the user’s recent interaction history and a global item interaction graph. The core insight is that unconstrained latent reasoning in high-dimensional spaces leads to drift, whereas user intent is inherently localized within a sparse, graph-defined neighborhood of collaboratively plausible items. ManCAR operationalizes this by treating latent reasoning as approximate inference over an intent variable, regularized by a graph-conditioned teacher prior that enforces local smoothness and feasibility.
As shown in the figure below, the reasoning trajectory in ManCAR (dashed black path) is confined to a low-dimensional region—the graph-induced manifold—defined by the k-hop neighborhood of recent items. This contrasts sharply with unconstrained reasoning (dashed red path), which wanders freely across the latent space and risks diverging from plausible intent. The manifold is instantiated via a finite candidate set C(k)=C(In,G,k), which includes the most recent items In and their k-hop neighbors on the global item graph G. Each latent reasoning state is projected onto the item probability simplex, but only distributions concentrating mass on C(k) are considered valid, thereby restricting the reasoning space to a structured subregion.
The training objective is derived from a variational perspective. The model introduces a discrete latent intent variable c∈C(k), and the conditional likelihood of the next item i∗ is factorized as pθ(i∗∣H)=∑c∈C(k)pθ(c∣H)pθ(i∗∣c,H). A graph-conditioned teacher prior q(c∣In,G) is constructed independently of model parameters and encodes prior knowledge about plausible intents reachable from recent interactions. The authors derive an ELBO-like objective:
logpθ(i∗∣H)≥Eq(c∣In,G)[logpθ(i∗∣c,H)]−DKL(q(c∣In,G)∥pθ(c∣H)).The first term encourages accurate prediction conditioned on graph-feasible intents, while the KL term regularizes the model’s inferred intent distribution to align with the teacher prior. This regularization explicitly limits the freedom of latent refinement and mitigates drift.
Refer to the framework diagram for the full implementation. The SeqRec model, typically a Transformer-based encoder, processes the user’s interaction history H to produce an initial latent state r1=hT−1. At each reasoning step t′, the model refines the latent state via a shared reasoning module and projects it onto the item space using the item embedding matrix E to produce logits zt′=rt′⊤E. The resulting distribution pθ(t′)(i∣H) is used for both target prediction and intent modeling.
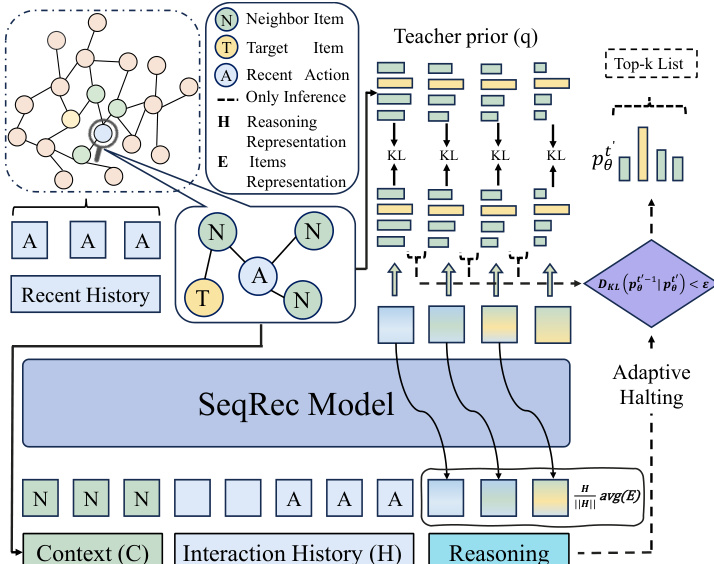
The main prediction loss at step t′ is approximated by injecting the candidate set C(k) as auxiliary context, yielding Lmain(t′)=−logpθ(t′)(i∗∣H,C(k)). The regularization loss is the KL divergence between the teacher prior and the induced intent distribution: Lreg(t′)=DKL(q(c∣In,G)∥pθ(t′)(c∣H)). The overall objective sums these losses across all reasoning steps, weighted by a regularization coefficient λ.
To guide reasoning progressively, the teacher prior is scheduled to sharpen over time. Using the Rank-Based Distribution Mass Assignment (RDMA) strategy, the teacher distribution is defined as qt′(c)∝exp(−rank(c)/γt′), where γt′=γbase⋅(T′−t′+1) decreases linearly, transitioning from a diffuse prior to a sharply peaked distribution centered on the target. This scheduling ensures bounded teacher drift and enables adaptive test-time termination: reasoning halts when the KL divergence between consecutive student distributions falls below a threshold ϵ, indicating convergence.
Additionally, to stabilize multi-step reasoning, the authors apply latent state norm rescaling after each refinement step: h←ϕ⋅∥h∥h⋅avg(E), where avg(E) is the average norm of item embeddings and ϕ is a learnable scaling parameter. This aligns latent state norms with the embedding space, improving softmax conditioning and supporting the stepwise contraction behavior assumed in the theoretical analysis.
Experiment
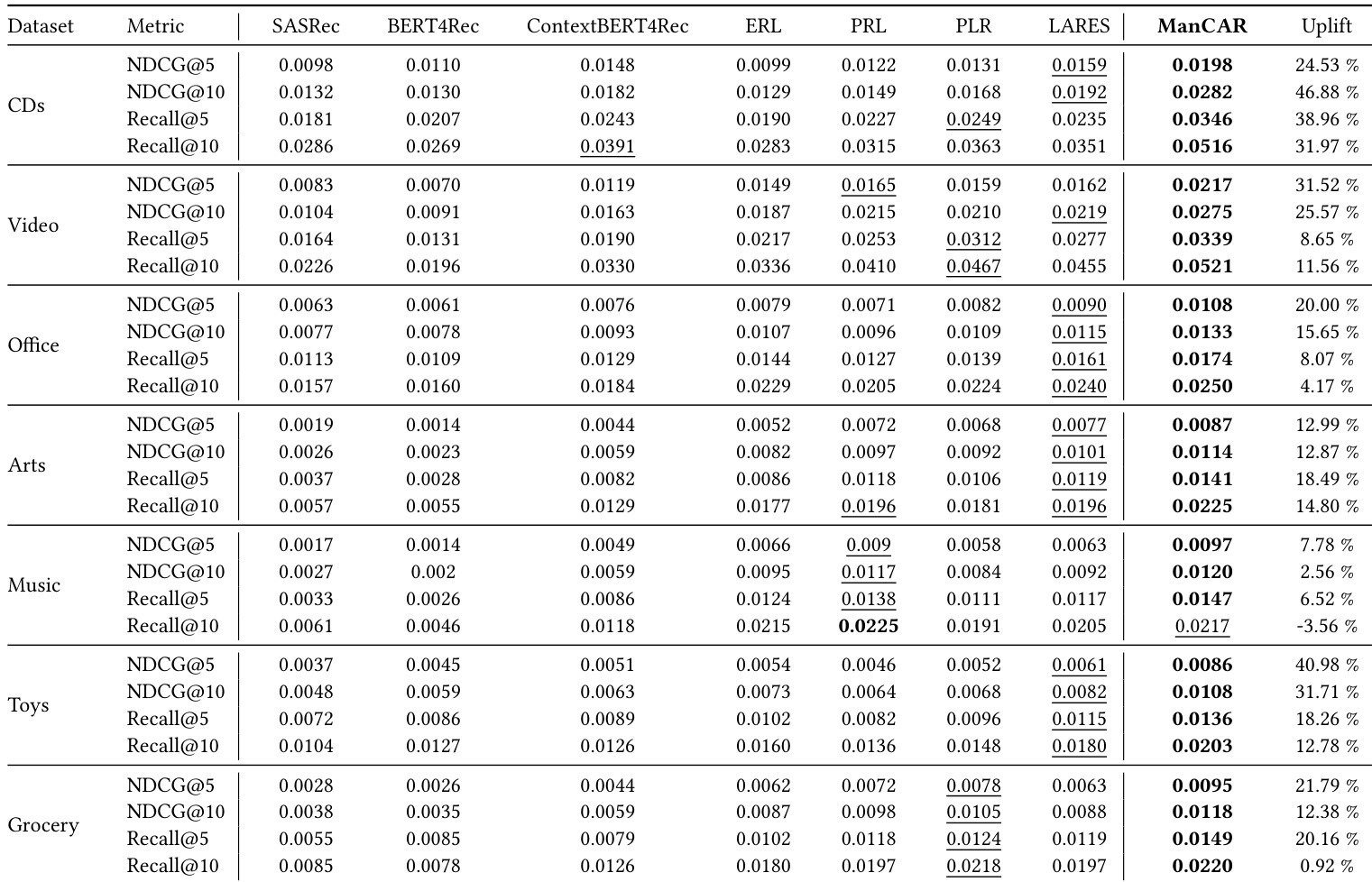
- ManCAR consistently outperforms all baselines across datasets and metrics, especially in ranking quality (NDCG), demonstrating superior intent refinement via structured multi-step reasoning.
- Graph-conditioned context enhances performance, but explicit latent reasoning (as in ManCAR) provides further gains over context-only models, showing iterative refinement resolves uncertainty more effectively.
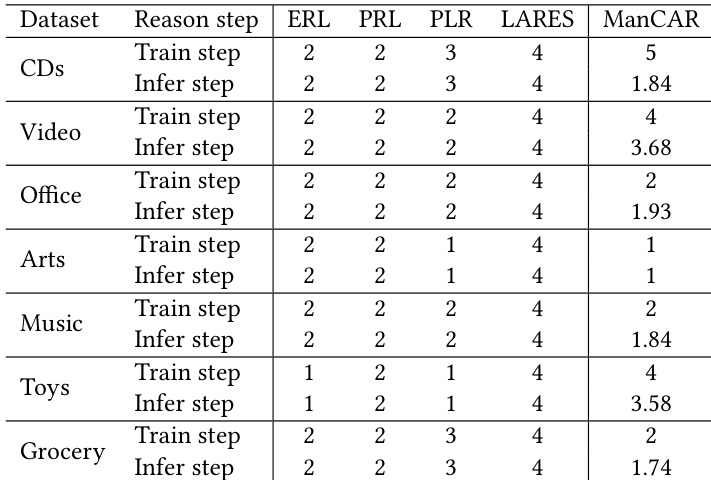
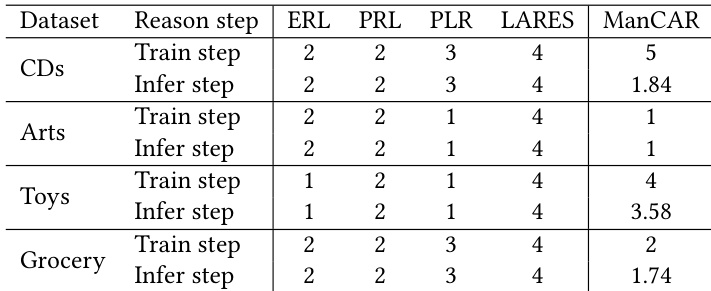
- ManCAR adapts reasoning depth dynamically at inference, using deeper steps on complex datasets and halting early on simpler ones, achieving near-oracle performance while balancing efficiency and accuracy.
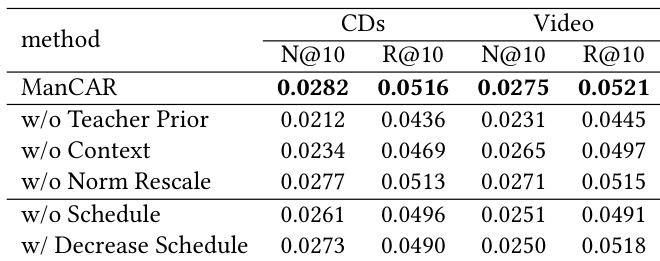
- Ablation studies confirm that graph-driven manifold constraints, context injection, latent state rescaling, and scheduled loss are critical; removing any degrades performance, with teacher-guided manifold control being most vital.
- The model is sensitive to graph neighbor count and training steps but robust to other hyperparameters, allowing reliable tuning via simple grid search.
- KL divergence analysis shows reasoning trajectories stabilize over steps, confirming convergence and consistent refinement behavior.
- Attention visualizations reveal reasoning states repeatedly anchor to graph-conditioned context, with later layers consolidating prior steps—supporting a constrained, data-driven refinement path grounded in recent interactions and graph signals.
ManCAR adapts its reasoning depth dynamically during training and inference, unlike prior methods that use fixed step counts across datasets. It employs deeper reasoning on complex datasets like CDs and Toys while stopping early on simpler ones like Arts and Grocery, achieving better performance with efficient computation. This data-aware flexibility enables ManCAR to balance expressiveness and efficiency across varying data characteristics.
The authors use ablation experiments to isolate the contribution of key components in ManCAR, showing that removing the teacher prior causes the largest performance drop, indicating its critical role in guiding stable latent reasoning. Results show that each component—context injection, norm rescaling, and loss scheduling—contributes meaningfully to performance, with their absence leading to consistent degradation across metrics. This confirms that ManCAR’s design elements work synergistically to constrain and refine the reasoning trajectory effectively.
ManCAR adapts its reasoning depth dynamically during training and inference, using more steps on complex datasets like CDs and Toys while stopping early on simpler ones like Arts and Grocery. This data-aware computation strategy allows it to outperform fixed-step baselines while maintaining efficiency. The model’s ability to adjust step count per dataset reflects its capacity to balance reasoning expressiveness with computational cost based on data characteristics.
The authors use ManCAR to outperform all baseline models across multiple datasets and metrics, with particularly strong gains in ranking quality as measured by NDCG. Results show that ManCAR’s integration of graph-conditioned context, scheduled teacher supervision, and adaptive inference enables more stable and effective multi-step reasoning compared to prior methods. The model achieves near-ceiling performance through data-aware step allocation, demonstrating that its structured refinement process adapts to dataset complexity while maintaining computational efficiency.