Command Palette
Search for a command to run...
A Very Big Video Reasoning Suite
A Very Big Video Reasoning Suite
Abstract
Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
One-sentence Summary
Researchers from Berkeley, NTU, Northeastern, UCSD, and others introduce VBVR, a massive video reasoning dataset and benchmark enabling scalable, interpretable evaluation; it reveals emergent generalization in video models, advancing spatiotemporal reasoning beyond prior small-scale efforts.
Key Contributions
- To address the lack of large-scale training data for video reasoning, the authors introduce VBVR, a dataset with over one million video clips across 200 curated tasks, organized by a five-part cognitive taxonomy spanning perception, transformation, spatiality, abstraction, and knowledge.
- They propose VBVR-Bench, a verifiable evaluation framework using rule-based, human-aligned scorers to enable reproducible and interpretable assessment of video reasoning, moving beyond unreliable model-based judging.
- Using the VBVR suite, they conduct one of the first large-scale scaling studies in video reasoning and observe early signs of emergent generalization to unseen tasks, establishing a foundation for future research in generalizable video reasoning.
Introduction
The authors leverage a principled cognitive architecture—spanning perception, transformation, spatiality, abstraction, and knowledge—to build VBVR, a massive video reasoning dataset with over 2 million samples across 200 tasks, addressing the critical lack of large-scale training data for spatiotemporal reasoning. Prior work in video generation and reasoning has focused on visual fidelity or narrow zero-shot evaluations, lacking standardized training splits and reproducible evaluation frameworks that support scaling studies. Their main contribution is VBVR-Bench, a rule-based, human-aligned evaluation system that enables interpretable diagnosis of reasoning capabilities, alongside empirical evidence that scaling video models on VBVR yields emergent generalization to unseen tasks—laying groundwork for next-generation generalizable video reasoning systems.
Dataset

The authors use VBVR-Dataset — a large-scale, synthetic video reasoning benchmark — to train and evaluate models on 200 cognitively grounded tasks, with 150 publicly released and 50 held back for future leaderboard use. Here’s how the data is composed, processed, and applied:
-
Dataset Composition & Sources
- Built from 150 approved task designs (selected from 500+ proposals) via a peer-reviewed process grounded in cognitive science principles.
- Tasks are implemented as parameterized generators (VBVR-DataFactory), hosted in GitHub repos with standardized naming (e.g., G-15_grid_avoid_obstacles_data-generator).
- Generators are contributed by both commercial teams (G-type) and open-source developers (O-type).
-
Key Subset Details
- Training Set: 100 tasks × 10,000 samples = 1M total. Each task generates diverse, non-trivial samples via constrained random sampling across parameter spaces (e.g., grid size, obstacle layout).
- Test Set: 150 tasks × 50 samples = 7,500 total. Includes 50 overlapping tasks with training set for in-distribution evaluation and 100 unique tasks for out-of-distribution generalization.
- Filtering Rules: All tasks must pass six criteria: information sufficiency, deterministic solvability, video dependency, visual clarity, parametric diversity (≥10k samples), and technical feasibility (PIL-based rendering). Rejected tasks include multi-step logic chains or physics requiring precise numerical solutions.
- Validation: Every sample is auto-validated for solvability (e.g., A* search), visual clarity (no occlusion, legible text), and parameter bounds. Failed samples trigger retries; persistent failures are logged.
-
Data Usage in the Paper
- Training uses 1M samples across 100 tasks. Test evaluation uses 7,500 samples across 150 tasks.
- The model VBVR-Wan is trained on the 1M training samples, showing improved reasoning performance with explicit supervision.
- Evaluation involves generating 4,500 videos (500 test prompts × 9 models) and scoring them via human annotators using three 1–5 scales: Task Completion, Reasoning Logic, Visual Quality.
-
Processing & Infrastructure
- Rendering: All visuals are 512×512, 24-bit RGB, 24 fps, H.264-encoded.
- Storage: Samples stored in private, encrypted AWS S3 buckets with hierarchical structure (by generator/task). Each sample includes: first_frame.png, prompt.txt, final_frame.png or goal.txt, and ground_truth.mp4.
- Generation: Scaled via AWS Lambda (up to 990 concurrent workers) with SQS queuing, CloudWatch monitoring, and DLQ for failed jobs. Typical run: 2–4 hours, $800–1200 cost.
- Reproducibility: Each sample records the generator’s git commit hash. Version-controlled, modular code enables independent updates.
- Diversity Enforcement: Stratified sampling, constraint satisfaction, duplicate detection (via hash), and visual randomization (colors, positions, styles).
Method
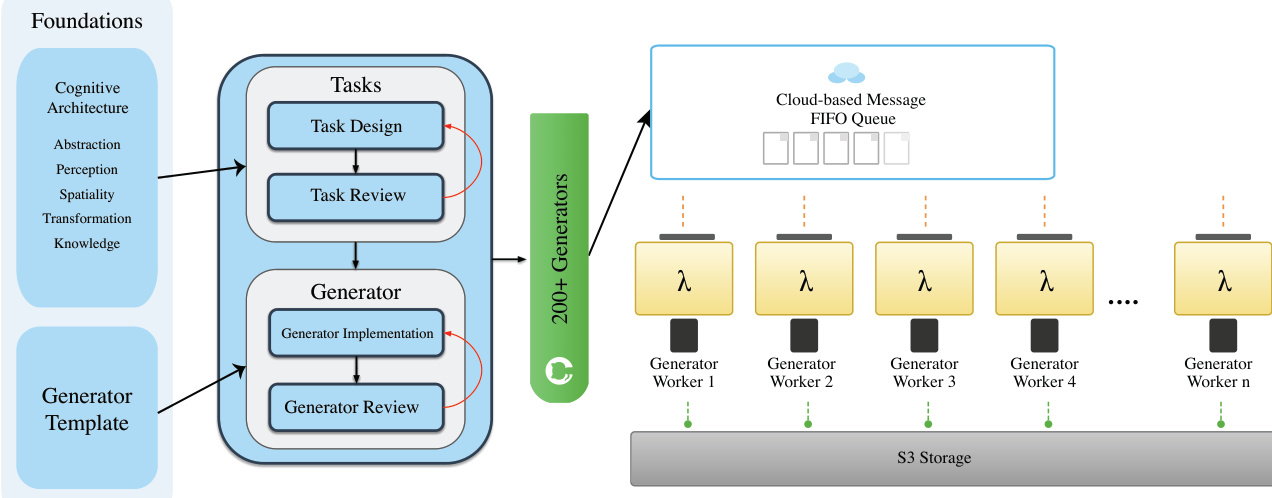
The authors leverage a structured, three-stage pipeline for data curation, beginning with task design and approval, followed by task-specific generator implementation, and culminating in large-scale distributed generation with integrated quality control. This pipeline ensures that each stage produces well-defined, reproducible outputs suitable for downstream model training and evaluation. The design is grounded in cognitive principles—drawing from domains such as abstraction, spatial reasoning, and transformation—while maintaining flexibility to prioritize task meaningfulness over rigid taxonomic constraints.
At the core of the system is a standardized generator architecture. All task generators inherit from a BaseGenerator abstract class, which enforces uniform interfaces and output formats. Each generator implements four required methods: initialization with a seed and parameters, sample generation, sample validation, and standardized output saving. This template ensures consistency across the 200+ generators, facilitates integration with the VBVR-DataFactory for batch processing, and embeds quality assurance through validation hooks that check for critical conditions such as object occlusion and solution feasibility.
Refer to the framework diagram, which illustrates how task design flows into generator implementation, with both stages subject to peer and specialized review. The validated generators are then deployed across a distributed infrastructure, where they are orchestrated via a cloud-based FIFO message queue. Each generator worker, represented as a Lambda function, pulls tasks from the queue, executes the generation, and stores outputs in S3 storage. This architecture enables scalable, fault-tolerant, and reproducible data production under fixed random seeds.
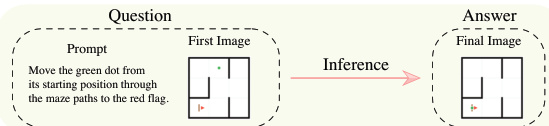
Each generator produces a deterministic four-component output: an initial state image (first_frame.png), a textual prompt (prompt.txt), a target state image (final_frame.png), and a complete solution trajectory video (ground_truth.mp4). The first two components serve as model inputs, while the latter two provide verifiable supervision—enabling models to learn not only the correct outcome but also the reasoning path to reach it. For example, in a grid navigation task, the generator may specify grid dimensions, obstacle placements, and start/end positions, then algorithmically compute the shortest path that visits all required blocks before reaching the goal.
As shown in the figure below, the inference process for a model involves receiving the prompt and first frame, then generating the final frame as output. The evaluation engine then compares this output against the ground truth trajectory and final state to assess task completion, logical consistency, and visual fidelity.
Task diversity is achieved through structured parameter spaces that vary object count, spatial configuration, structural complexity, and difficulty level. Generators employ stratified sampling to ensure balanced coverage across these dimensions. Before deployment, each generator undergoes code review to verify scalability, visual quality, edge-case handling, and reproducibility. Only generators that satisfy these criteria are admitted to large-scale production, ensuring high-quality, diverse, and cognitively meaningful reasoning tasks.
Experiment
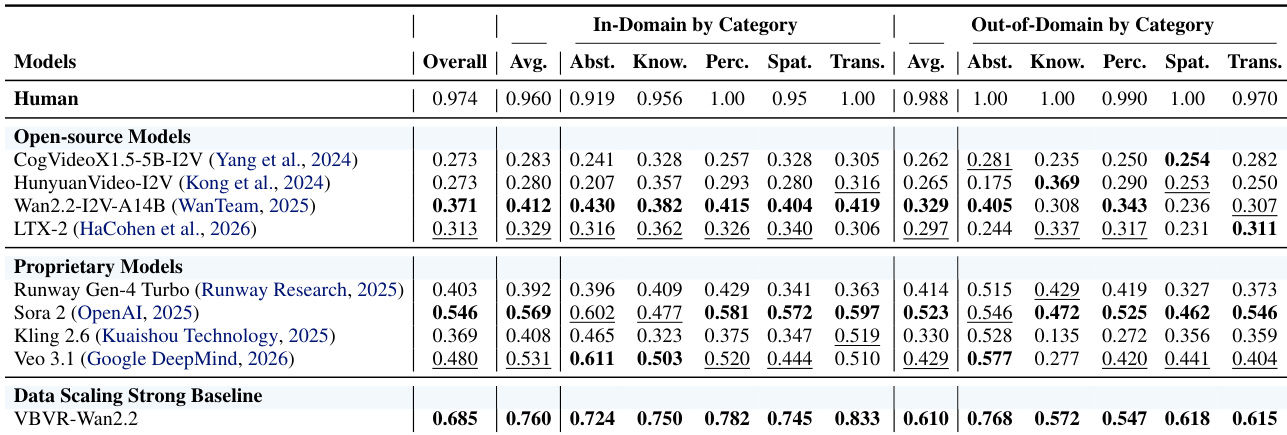
- Introduced VBVR-Bench, a deterministic, rule-based evaluation toolkit with 100 tasks split into in-domain and out-of-domain sets to test generalization and reasoning primitives beyond memorization.
- Validated strong alignment between automated scores and human preferences, confirming the benchmark’s interpretability and diagnostic value for model capabilities.
- Found proprietary models (Sora 2, Veo 3.1) outperform open-source baselines, but fine-tuning Wan2.2 on VBVR-Dataset yields VBVR-Wan2.2, achieving state-of-the-art performance and closing much of the gap.
- Revealed structured capability dependencies: Knowledge strongly couples with Spatiality, while negatively correlates with Perception; Abstraction negatively correlates with Transformation and Spatiality, suggesting modular cognitive faculties.
- Demonstrated that scaling data improves both in-domain and out-of-domain performance, though gains plateau and a persistent generalization gap remains, indicating architectural limitations.
- Qualitative analysis showed VBVR-Wan2.2 excels at controllable, constraint-following execution, often surpassing Sora 2 on precise manipulation tasks, and exhibits emergent multi-step reasoning and policy consistency.
- Identified key failure modes: long-horizon identity instability, procedural unfaithfulness in step-by-step tasks, and breakdowns under complex temporal or causal constraints.
- Confirmed that VBVR training preserves core generative quality while enhancing motion and temporal consistency, supporting the principle that controllability is foundational for verifiable reasoning in video models.
The authors use VBVR-Wan2.2 to demonstrate that fine-tuning on a large reasoning-focused dataset significantly improves video generation performance across multiple dimensions, particularly in camera motion consistency and subject-background stability. Results show that while the model maintains high aesthetic and imaging quality, it achieves greater precision in motion dynamics and temporal coherence, indicating a shift toward controllable, constraint-following execution rather than generic scene generation. This suggests that targeted data scaling can enhance reasoning capabilities without sacrificing core generative quality.

The authors use VBVR-Dataset to evaluate video reasoning models through a structured benchmark with 100 diverse tasks split into in-domain and out-of-domain generalization settings. Results show that fine-tuning on this dataset significantly improves model performance, especially in spatial and perceptual reasoning, while revealing persistent gaps in long-horizon control and process faithfulness. Capability analysis further indicates that reasoning faculties such as knowledge and spatiality are positively coupled, while others like perception and abstraction show strong negative correlations, suggesting distinct underlying mechanisms in model behavior.
The authors use a controlled data scaling experiment to evaluate how increasing training data affects video reasoning performance across in-domain and out-of-domain tasks. Results show that performance improves with more data but plateaus, revealing persistent gaps in long-horizon reasoning and systematic generalization even under fixed architecture. The findings highlight that while data scaling enhances transferable reasoning, architectural innovations are needed to overcome fundamental bottlenecks in temporal consistency and constraint adherence.
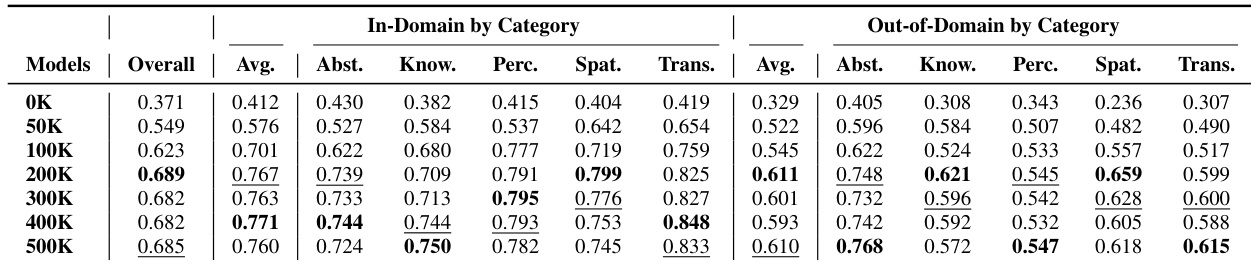
The authors use VBVR-Bench to evaluate video generation models across in-domain and out-of-domain reasoning tasks, revealing that proprietary models like Sora 2 and Veo 3.1 outperform open-source baselines, while fine-tuning Wan2.2 with VBVR-Dataset yields the highest overall score, demonstrating strong generalization. Results show that increased training data improves both in-domain and out-of-domain performance, though a persistent gap remains, highlighting limitations in long-horizon reasoning and systematic generalization. Capability analysis further reveals structured trade-offs, such as a strong negative correlation between Knowledge and Perception, suggesting distinct underlying mechanisms in model reasoning.