Command Palette
Search for a command to run...
PyVision-RL: Forging Open Agentic Vision Models via RL
PyVision-RL: Forging Open Agentic Vision Models via RL
Shitian Zhao Shaoheng Lin Ming Li Haoquan Zhang Wenshuo Peng Kaipeng Zhang Chen Wei
Abstract
Reinforcement learning for agentic multimodal models often suffers from interaction collapse, where models learn to reduce tool usage and multi-turn reasoning, limiting the benefits of agentic behavior. We introduce PyVision-RL, a reinforcement learning framework for open-weight multimodal models that stabilizes training and sustains interaction. Our approach combines an oversampling-filtering-ranking rollout strategy with an accumulative tool reward to prevent collapse and encourage multi-turn tool use. Using a unified training pipeline, we develop PyVision-Image and PyVision-Video for image and video understanding. For video reasoning, PyVision-Video employs on-demand context construction, selectively sampling task-relevant frames during reasoning to significantly reduce visual token usage. Experiments show strong performance and improved efficiency, demonstrating that sustained interaction and on-demand visual processing are critical for scalable multimodal agents.
One-sentence Summary
Shitian Zhao, Shaoheng Lin, and colleagues from multiple institutions propose PyVision-RL, a reinforcement learning framework that prevents interaction collapse in multimodal agents via oversampling-filtering-ranking and accumulative tool rewards, enabling efficient video reasoning through on-demand frame sampling, with open-sourced code and models.
Key Contributions
- PyVision-RL introduces a reinforcement learning framework for open-weight multimodal models that combats interaction collapse by combining an oversampling-filtering-ranking rollout strategy with an accumulative tool reward to sustain multi-turn tool usage during training.
- The framework unifies training for image and video understanding, with PyVision-Video uniquely employing on-demand context construction to selectively sample task-relevant video frames, reducing visual token usage by up to 90% compared to uniform sampling methods.
- Empirical results show PyVision-Image and PyVision-Video achieve state-of-the-art performance on multimodal benchmarks, including +6.9% over DeepEyes-v2 on V* and +2.2% over VITAL on VSI-Bench, while maintaining high efficiency through dynamic tooling and sparse visual token consumption.
Introduction
The authors leverage reinforcement learning to build open-weight multimodal agents that actively reason and interact with images and videos using Python as a dynamic tool. Prior approaches either rely on rigid, predefined toolsets or suffer from interaction collapse during RL training, where models abandon tool use and multi-turn reasoning. PyVision-RL addresses this with two key innovations: an oversampling-filtering-ranking rollout strategy to stabilize training, and an accumulative tool reward that explicitly encourages sustained interaction. For video tasks, it introduces on-demand context construction, letting the model fetch only relevant frames via code—cutting visual token usage by 90% compared to uniform sampling while improving accuracy. The resulting models, PyVision-Image and PyVision-Video, set new benchmarks in agentic visual reasoning while demonstrating that scalable, efficient multimodal agents are achievable with the right training incentives.
Dataset

The authors sample additional frames from the video at specific indices (650, 750, 850, 950, 1050) to provide context between frames 600 and 1200. These frames are extracted as NumPy arrays from the video clip and used to enrich the temporal context for downstream processing. No dataset composition, source, or model training details are provided in the given text.
Method
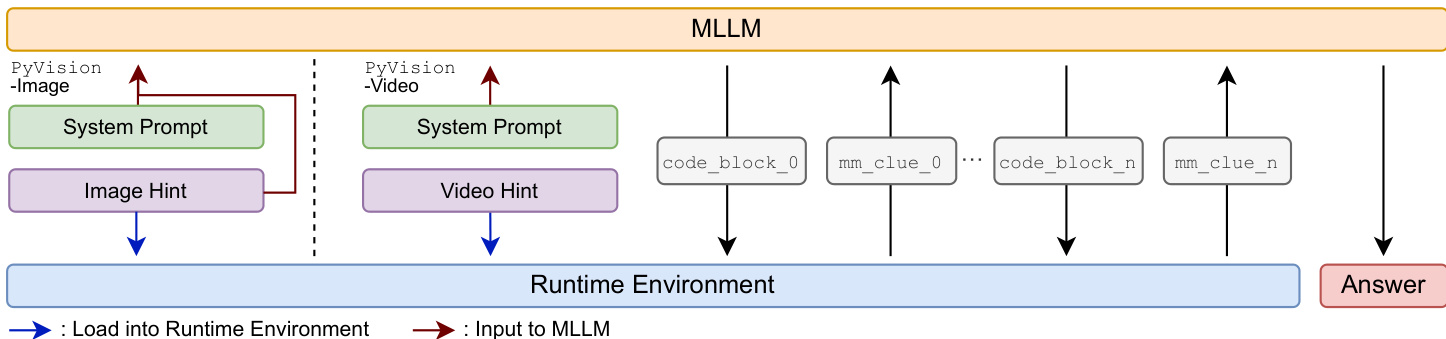
The authors leverage PyVision-RL, an agentic reinforcement learning framework designed to train open-weight multimodal large language models (MLLMs) with dynamic tool use. The core innovation lies in treating Python as a primitive tool, enabling the model to interleave natural language reasoning with executable code. This interaction is governed by a structured protocol: the MLLM generates reasoning text and code blocks wrapped in <code>...</code> tags, which are executed in a runtime environment. The environment returns execution results, termed multimodal clues (mm_clue_i), wrapped in <interpreter>...</interpreter> tags. This loop continues until the model produces a final answer enclosed in <answer>...</answer>, with all intermediate outputs appended to the context for continuity.
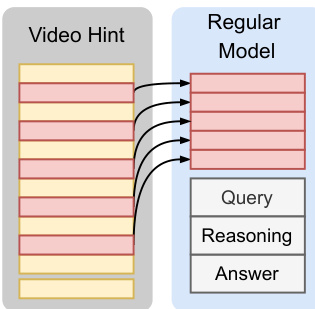
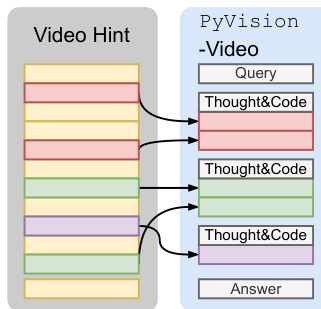
Refer to the framework diagram, which illustrates the bidirectional interaction between the MLLM and the runtime environment. For image tasks, the image is injected into both the MLLM context and the Python runtime, allowing the agent to reference and manipulate the image during reasoning. For video tasks, PyVision-Video employs an on-demand context construction strategy: the full video is loaded only into the Python runtime, and the agent dynamically samples and plots frames via Python code based on the query or heuristic strategies. This contrasts with uniform frame sampling and reduces visual token usage while improving performance.
To sustain multi-turn tool usage during RL training and prevent interaction collapse, the authors introduce an accumulative tool reward. The final reward combines answer accuracy Racc∈{0,1} with a tool usage bonus proportional to the number of tool calls ntc, given by 0.1⋅ntc. This bonus is added only if the answer is correct, ensuring that tool usage is incentivized without rewarding unproductive or incorrect calls. The final RL objective is:
R=Racc+accumulative tool reward0.1⋅ntc⋅1{Racc=1}Training stability is further enhanced through an oversampling-filtering-ranking framework for rollout generation. The authors first oversample rollouts, then apply online filtering to remove groups with zero reward variance and rollouts with broken agent-environment interactions (e.g., timeouts or runtime failures). Among the remaining candidates, rollout groups are ranked by group-level reward standard deviation, which serves as a proxy for sample difficulty. The top-ranked groups are retained for training, prioritizing moderately difficult rollouts that provide informative learning signals. This strategy, termed Standard Deviation Sorting, reduces the prevalence of correct samples with negative advantages and improves training efficiency.
The base RL algorithm is GRPO, but the authors remove the standard deviation normalization term in the intra-group advantage computation to improve stability. The advantage for each token is computed as:
Ai,t=R(x,yi)−mean({R(x,yi)}i=1G)where R(x,yi) denotes the rollout-level reward. Models are initialized with supervised fine-tuning (SFT) using synthetic data generated with GPT-4.1, covering diverse domains such as multimodal reasoning, medical reasoning, chart understanding, and visual question answering. For PyVision-Video, a dedicated SFT dataset of 44K samples is curated to teach on-demand context construction. RL training then specializes agentic behavior using task-specific datasets, with both PyVision-Image and PyVision-Video trained for 700 steps on 8 H100 GPUs using consistent hyperparameters.
Experiment
- PyVision-Image excels across visual search, multimodal math reasoning, and agentic tasks, outperforming static-tool and Python-interpreter baselines, demonstrating that dynamic tooling enhances both perception and complex reasoning.
- PyVision-Video achieves strong spatial reasoning on VSI-Bench while drastically reducing visual token usage via on-demand frame selection, offering superior efficiency without sacrificing accuracy.
- Ablation studies confirm that increasing max turn budget and adding accumulative tool reward yield larger gains in later training stages, enabling sustained multi-turn reasoning.
- Standard deviation sorting stabilizes training by prioritizing informative, moderately difficult samples and reducing suppression of correct trajectories with fewer tool calls.
- Removing standard deviation normalization in advantage estimation improves training stability by lowering variance in advantage signals.
- Training dynamics show consistent improvement in tool usage, response length, and validation performance, indicating effective RL optimization for long-horizon, agentic behavior.
PyVision-Image outperforms both static toolset and dynamic tooling baselines across visual search, multimodal reasoning, and agentic reasoning benchmarks, achieving state-of-the-art results on several tasks. The model’s gains are particularly pronounced in visual search and multimodal math tasks, indicating that its dynamic tooling and RL-driven training effectively enhance both perception and complex reasoning. Results confirm that dynamic tool invocation and extended interaction horizons contribute meaningfully to performance beyond what static or limited-turn approaches can achieve.

The authors use ablation experiments to evaluate how training components—accumulative tool reward, standard deviation ranking, removal of standard deviation normalization, and max turn budget—affect PyVision-Image’s performance across visual search and multimodal reasoning tasks. Results show that increasing the max turn budget and incorporating the accumulative tool reward yield larger performance gains in later training stages, while removing standard deviation normalization and applying standard deviation ranking consistently improve stability and final performance. Overall, the combination of all four components delivers the strongest results, particularly at 600 training steps, where it outperforms all ablated variants across most benchmarks.

PyVision-Video outperforms prior models on VSI-Bench across multiple spatial reasoning categories, achieving the highest average score of 44.0 and demonstrating strong performance in object counting, absolute distance estimation, and approximate ordering. The model’s dynamic frame selection strategy enables efficient use of visual tokens while maintaining competitive accuracy, particularly evident in its superior results on relational direction and object size tasks. These gains reflect the effectiveness of agentic, on-demand video processing for complex spatial reasoning.
