Command Palette
Search for a command to run...
From Perception to Action: An Interactive Benchmark for Vision Reasoning
From Perception to Action: An Interactive Benchmark for Vision Reasoning
Abstract
Understanding the physical structure is essential for real-world applications such as embodied agents, interactive design, and long-horizon manipulation. Yet, prevailing Vision-Language Model (VLM) evaluations still center on structure-agnostic, single-turn setups (e.g., VQA), which fail to assess agents' ability to reason about how geometry, contact, and support relations jointly constrain what actions are possible in a dynamic environment. To address this gap, we introduce the Causal Hierarchy of Actions and Interactions (CHAIN) benchmark, an interactive 3D, physics-driven testbed designed to evaluate whether models can understand, plan, and execute structured action sequences grounded in physical constraints. CHAIN shifts evaluation from passive perception to active problem solving, spanning tasks such as interlocking mechanical puzzles and 3D stacking and packing. We conduct a comprehensive study of state-of-the-art VLMs and diffusion-based models under unified interactive settings. Our results show that top-performing models still struggle to internalize physical structure and causal constraints, often failing to produce reliable long-horizon plans and cannot robustly translate perceived structure into effective actions. The project is available at https://social-ai-studio.github.io/CHAIN/.
One-sentence Summary
Researchers from multiple institutions introduce CHAIN, a physics-driven 3D benchmark evaluating VLMs’ ability to plan and execute structured actions under physical constraints, revealing current models’ failure to robustly translate structure into reliable long-horizon plans for interactive tasks like mechanical puzzles.
Key Contributions
- We introduce CHAIN, an interactive 3D physics-driven benchmark that evaluates models on multi-step physical reasoning tasks such as interlocking puzzles and 3D stacking, moving beyond static VQA to assess how agents plan and adapt actions under geometric, contact, and support constraints.
- Our unified evaluation of state-of-the-art VLMs and diffusion models reveals persistent shortcomings: models fail to reliably translate perceived physical structure into feasible long-horizon action sequences, especially as constraints tighten across interaction steps.
- CHAIN provides 109 reproducible levels with graded difficulty and standardized metrics, exposing critical gaps in current models’ ability to reason about hidden 3D constraints and maintain stable, physically grounded plans over extended interactions.
Introduction
The authors leverage interactive 3D physics environments to evaluate how well vision-language and diffusion models can reason about physical structure—geometry, contact, and support—to plan and execute multi-step actions, which matters for real-world applications like robotic manipulation and embodied AI. Prior benchmarks focus on static, single-turn tasks like VQA, failing to test whether models can adapt plans as constraints evolve or anticipate how early actions limit future options; diffusion models are similarly evaluated in simplified 2D settings that ignore 3D physical complexity. Their main contribution is CHAIN, an open-source benchmark with 109 levels that force models to iteratively perceive, act, and revise plans under realistic physical constraints, revealing that even top models struggle to translate structural understanding into reliable long-horizon action sequences.
Dataset
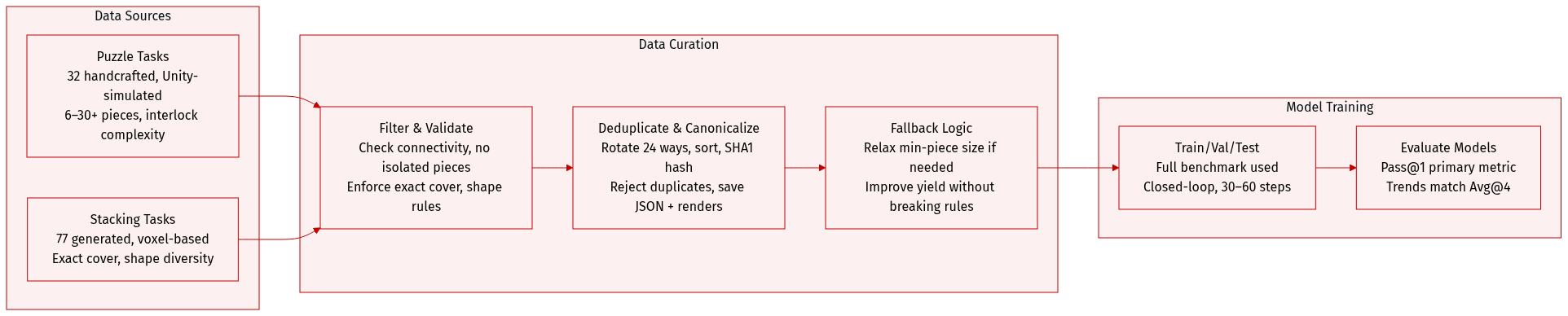
The authors use the CHAIN benchmark, which comprises two core task families: Puzzle and Stacking, designed to evaluate long-horizon reasoning and physically grounded manipulation.
-
Dataset Composition & Sources:
- Puzzle: 32 handcrafted interlocking mechanical tasks (10 easy, 12 medium, 10 hard), modeled in Unity to enforce precise kinematic and contact constraints. Inspired by Kongming locks, burr puzzles, and similar designs.
- Stacking: 77 programmatically generated 3D spatial packing tasks (10 easy, 20 medium, 47 hard), created via algorithmic voxel-based generation with rule-based validation for exact volume coverage.
-
Key Subset Details:
- Puzzle: Difficulty scales with piece count and interlock complexity. Easy tasks involve 6 pieces; hard tasks exceed 30. Success requires exact final configuration matching.
- Stacking: Difficulty determined by container size, object count, and shape diversity. Generated under constraints including exact cover, 6-neighbor connectivity, piece size bounds, no 2x3 flat faces, and no isolated pieces. Hard mode enforces unique piece shapes and higher solver effort thresholds.
-
How Data Is Used:
- Training split and mixture ratios are not specified; evaluation is performed on the full benchmark.
- Models are evaluated under closed-loop interaction with step limits (30–60 steps per instance). Primary metric is Pass@1 due to high interaction cost, though trends align with multi-sample metrics (Avg@4).
-
Processing & Metadata:
- Stacking tasks are generated via staged sampling: Easy uses axis-aligned cuboids; Mid grows planar-connected pieces; Hard grows free-form connected pieces with shape uniqueness.
- Physical feasibility checks include no isolated pieces and (optionally) linear disassembly sequences via greedy translation along six axes.
- Strong deduplication via canonicalization: each piece is normalized, rotated into 24 orientations, and lexicographically sorted to form a multiset signature (SHA1 hashed).
- Each accepted puzzle is stored with a JSON manifest (pieces, solution, assembly order, stats) and rendered 3D visualizations.
- Generation includes fallback logic: if strict min-piece size (e.g., 4) fails, relaxes to min-piece=3 to improve yield.
Method
The authors leverage a structured three-phase pipeline to construct an interactive benchmark that emphasizes multi-step reasoning, physical controllability, and fine-grained evaluation of agent behavior. The framework is designed to move beyond static question-answering paradigms by embedding agents in dynamic, physics-aware environments where success depends on sequential planning and causal understanding.
Refer to the framework diagram, which illustrates the end-to-end construction process. The pipeline begins with sourcing candidate puzzles from external repositories such as Puzzlemaster, followed by a rigorous filtering stage that applies three criteria: chain dependency, feasibility, and human difficulty assessment. Chain dependency ensures that puzzles require ordered, causally linked actions; feasibility guarantees that the puzzle can be simulated with stable state transitions and a controllable action space; and human difficulty check assigns tiered labels (easy, medium, hard) based on expert solve times. For stacking tasks, which are algorithmically generated rather than curated, the same human evaluation protocol is applied to maintain consistency in difficulty calibration.
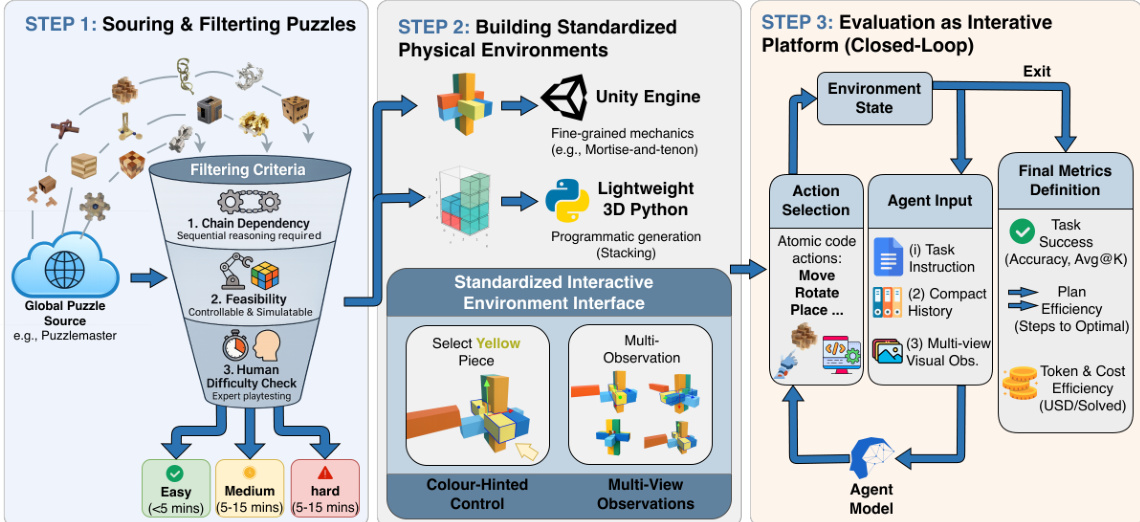
In the second phase, the authors build standardized physical environments using two complementary toolchains: Unity for puzzles requiring fine-grained mechanical interactions (e.g., Kongming and Lu Ban locks), and a lightweight 3D Python engine for stacking tasks with simpler dynamics. To ensure uniform interaction, they implement a color-hinted control scheme where each object is assigned a unique color, and agents select pieces by color rather than through an additional controller. This avoids confounding variables introduced by vision-language-action (VLA) interfaces. Multi-view observations are provided to mitigate occlusion and support spatial reasoning.
The final phase treats the benchmark as an interactive platform under a closed-loop protocol. Each evaluation episode initializes a task instance with a predefined state, including object poses and constraints. At each step t, the agent receives: (i) a task instruction specifying the goal, (ii) a compact history of prior observations and actions, and (iii) current multi-view visual observations. Conditioned on these inputs, the agent selects an atomic action (e.g., Move, Rotate, Place) from a predefined set. The simulator executes the action, updates the environment state, and returns new observations for step t+1. The loop continues until the task is solved or a step budget is exhausted. Evaluation metrics are computed from the full trajectory, including task success, plan efficiency (steps to optimal), and token/cost efficiency (USD/solved), enabling a multidimensional assessment of agent performance.
For polycube stacking puzzles, the authors employ a sample-verify generation pipeline. Candidate partitions are sampled and validated for exact-cover solvability using Algorithm X with dancing links (DLX), which reduces the problem to a sparse matrix where each row represents a piece placement and each column represents a voxel or piece usage constraint. Structural constraints and optional linear assembly feasibility are also enforced. De-duplication is achieved by canonicalizing piece shapes under rigid rotations and hashing the resulting multiset.
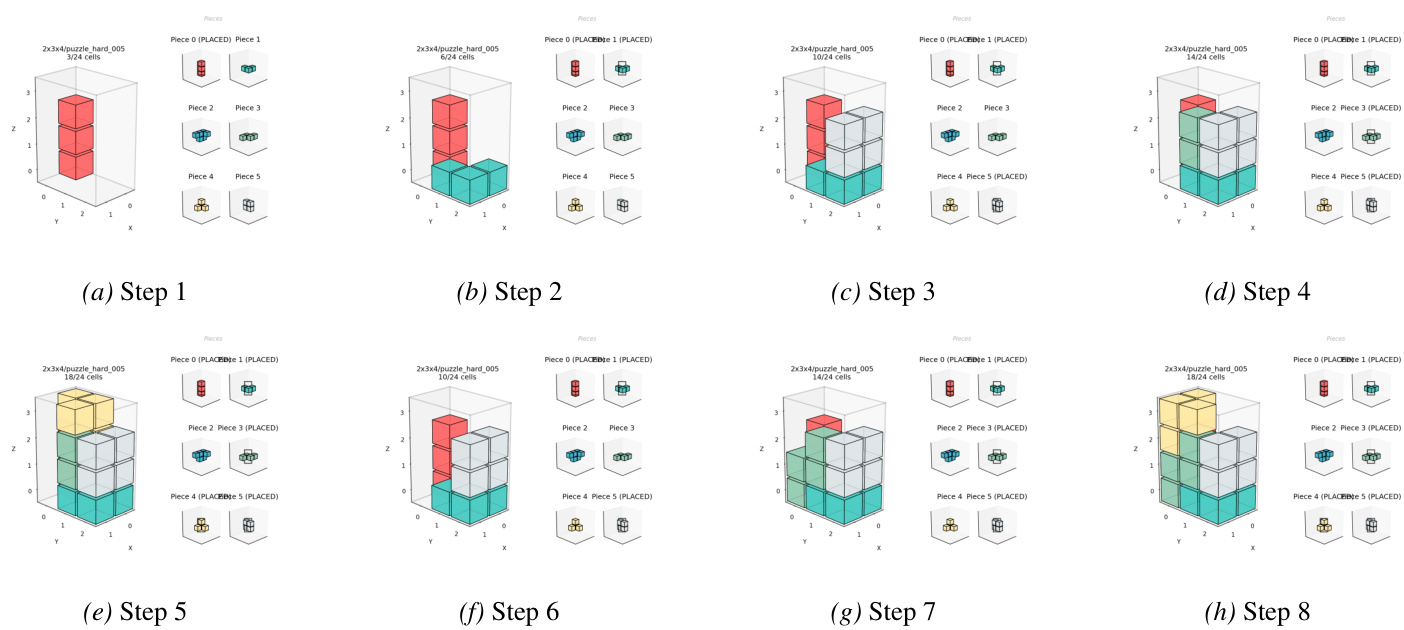
The linear assembly sequence is extracted via a greedy disassembly algorithm that iteratively identifies removable pieces along axis-aligned directions. The algorithm maintains a set of remaining pieces R and, at each iteration, tests each piece i∈R for removability in any of the six cardinal directions d∈{+x,−x,+y,−y,+z,−z}. If a piece is removable, it is appended to the removal list, removed from R, and the process repeats. If no piece can be removed, the algorithm fails. The final assembly order π is obtained by reversing the removal sequence.
This architecture enables the evaluation of agents not only on whether they solve a task, but on how they reason through physical constraints, plan sequences of actions, and adapt to feedback — all within a reproducible, controllable, and difficulty-calibrated environment.
Experiment
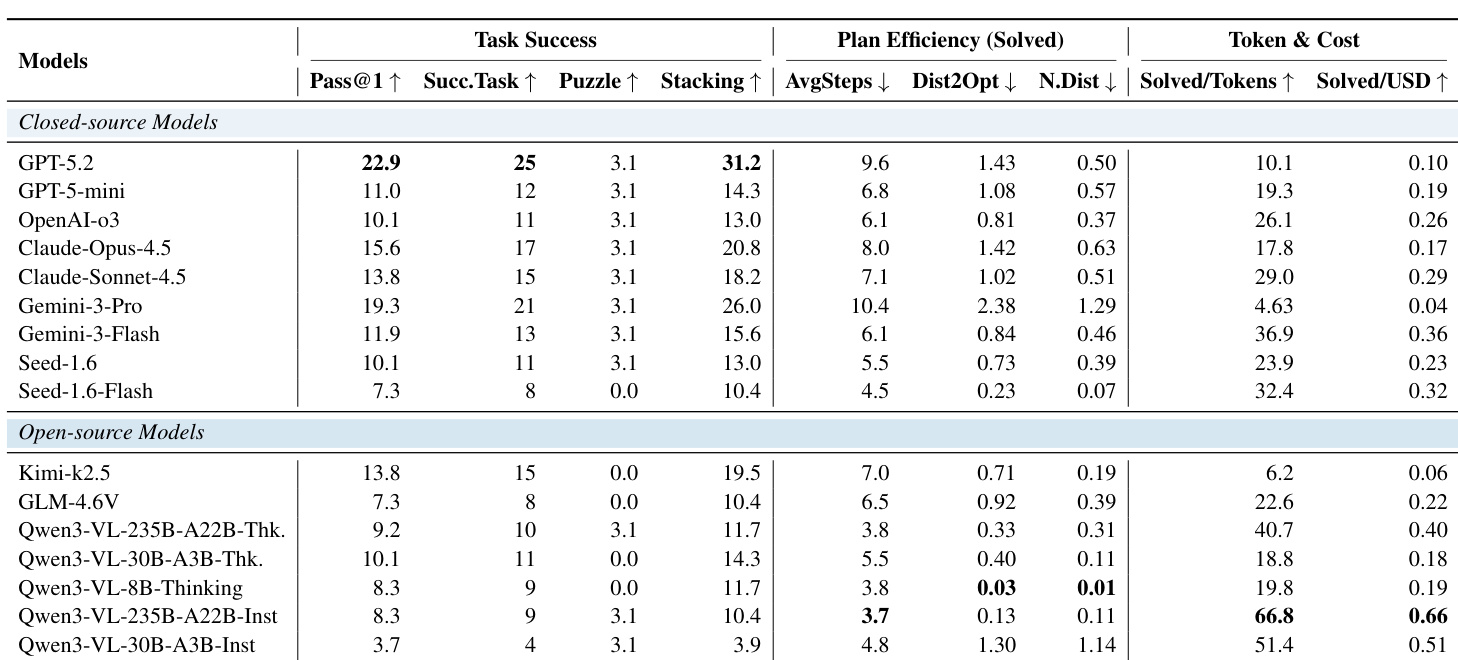
- Evaluated models across task success, plan efficiency, and cost efficiency, revealing that higher success often comes with higher resource use and cost.
- Closed-source models like GPT-5.2 lead in task success but are costlier; open-source models like Kimi-k2.5 offer moderate success at lower cost.
- Puzzle tasks remain extremely challenging for all models due to difficulty in inferring hidden physical constraints and planning multi-step disassembly.
- Stacking tasks show tiered difficulty: easy levels are mostly solved, but mid and hard levels require global spatial planning and suffer from early greedy decisions leading to dead-ends.
- Interaction significantly boosts performance over one-shot solving, especially for Puzzle and complex Stacking, highlighting the need for closed-loop feedback in physical reasoning.
- World models fail catastrophically on structured physical tasks, hallucinating actions and violating constraints, indicating fundamental limitations in object permanence and physical grounding.
- Reward models provide limited gains in long-horizon planning; verifier-based checks offer more reliable improvement, suggesting selection signal quality is the key bottleneck.
- Successful stacking strategies prioritize stable base formation and incremental volume filling, while failures stem from early irreversible placements that create geometric dead-ends.
The authors evaluate a range of closed- and open-source models on an interactive physical reasoning benchmark, finding that closed-source models generally achieve higher task success but often at the cost of greater token usage and monetary expense. Plan efficiency metrics reveal that even successful executions frequently involve redundant steps, especially for complex tasks like 3D puzzles, where models struggle with structural inference and constraint satisfaction. Interaction significantly improves performance over one-shot solving, highlighting the necessity of closed-loop feedback for navigating evolving physical constraints.
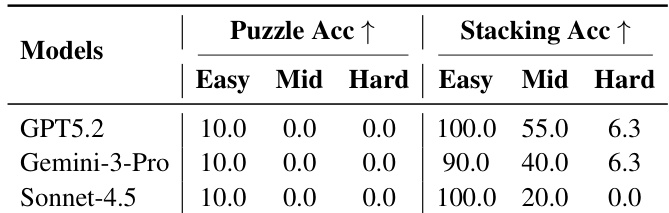
The authors evaluate several large models on structured physical reasoning tasks, finding that even top performers like GPT-5.2 and Gemini-3-Pro achieve near-perfect accuracy on easy stacking tasks but struggle significantly with mid and hard levels, where success rates drop sharply. Puzzle tasks remain consistently challenging across all difficulty tiers, with no model achieving any success beyond the easiest level, indicating fundamental limitations in handling 3D structural inference. Results highlight that task difficulty is not smoothly scalable but hinges on specific reasoning demands, such as constraint propagation and multi-step planning under partial observability.
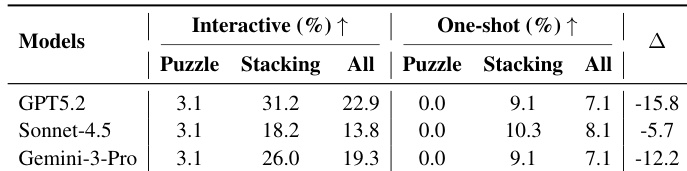
The authors evaluate multiple models on an interactive physical reasoning benchmark, finding that even top-performing models show significantly lower success rates in one-shot settings compared to interactive ones, highlighting the critical role of feedback in solving complex spatial tasks. Results indicate that interaction enables modest success on challenging 3D puzzles and substantially improves stacking performance, suggesting that closed-loop adaptation is essential for handling evolving physical constraints. Stronger models benefit more from interaction, as their ability to revise plans based on feedback translates into larger performance gaps over static, single-view approaches.
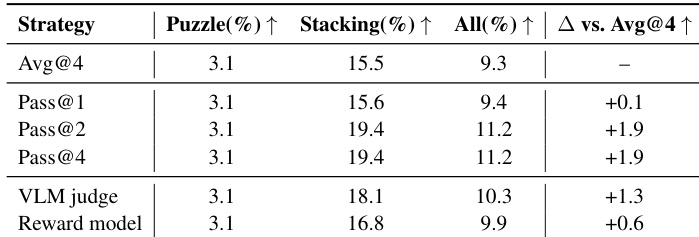
The authors evaluate different candidate selection strategies using Kimi-k2.5 and find that verifier-based judging outperforms reward model reranking, yielding a +1.3 improvement over the baseline, while reward models provide only marginal gains. Multi-sample selection (Pass@2 and Pass@4) offers consistent but diminishing returns, suggesting that selection signal quality—not sampling scale—is the key bottleneck for improving performance in long-horizon interactive planning.