Command Palette
Search for a command to run...
ARLArena: A Unified Framework for Stable Agentic Reinforcement Learning
ARLArena: A Unified Framework for Stable Agentic Reinforcement Learning
Abstract
Agentic reinforcement learning (ARL) has rapidly gained attention as a promising paradigm for training agents to solve complex, multi-step interactive tasks. Despite encouraging early results, ARL remains highly unstable, often leading to training collapse. This instability limits scalability to larger environments and longer interaction horizons, and constrains systematic exploration of algorithmic design choices. In this paper, we first propose ARLArena, a stable training recipe and systematic analysis framework that examines training stability in a controlled and reproducible setting. ARLArena first constructs a clean and standardized testbed. Then, we decompose policy gradient into four core design dimensions and assess the performance and stability of each dimension. Through this fine-grained analysis, we distill a unified perspective on ARL and propose SAMPO, a stable agentic policy optimization method designed to mitigate the dominant sources of instability in ARL. Empirically, SAMPO achieves consistently stable training and strong performance across diverse agentic tasks. Overall, this study provides a unifying policy gradient perspective for ARL and offers practical guidance for building stable and reproducible LLM-based agent training pipelines.
One-sentence Summary
Researchers from UCLA and UW–Madison introduce ARLArena, a systematic framework diagnosing instability in agentic RL, and propose SAMPO—a stable policy optimizer combining sequence-level clipping, fine-grained advantage design, and dynamic filtering—to enable reproducible, high-performance training across multi-turn tasks like ALFWorld and WebShop.
Key Contributions
- ARLArena introduces a standardized testbed and diagnostic framework that isolates and analyzes four core policy gradient design dimensions, enabling reproducible evaluation of stability in agentic reinforcement learning across multi-turn tasks like ALFWorld and Sokoban.
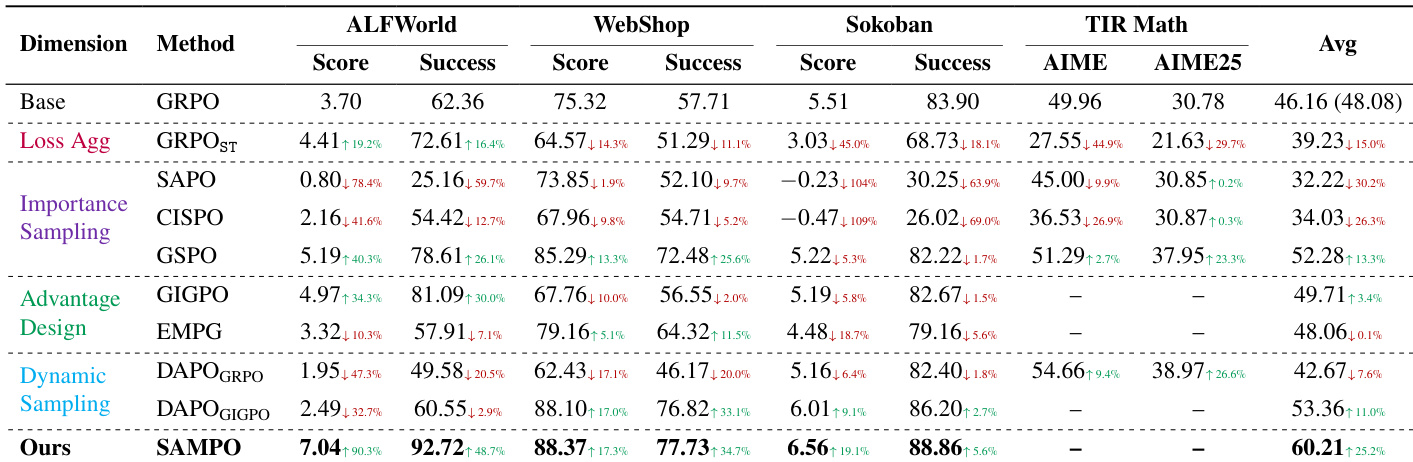
- Through systematic decomposition, the study identifies key stability drivers: sequence-level clipping over tolerant clipping, environment-aware advantage design, and dynamic sampling—culminating in SAMPO, a novel policy optimization method that mitigates training collapse.
- SAMPO demonstrates consistent training stability and achieves a 25.2% average performance gain over GRPO across diverse agentic benchmarks, validating its robustness and effectiveness in long-horizon, interactive LLM agent training.
Introduction
The authors leverage agentic reinforcement learning (ARL) to train large language models for complex, multi-step interactive tasks like web navigation and tool use, where long-horizon decision-making and planning are critical. Prior ARL methods suffer from severe training instability—caused by compounding errors, sparse rewards, and non-stationary dynamics—which limits scalability and reproducibility. To address this, they introduce ARLArena, a standardized testbed and four-dimensional policy gradient analysis framework that isolates and evaluates key design choices. Their main contribution is SAMPO, a stable policy optimization method combining sequence-level clipping, environment-aware advantage design, and dynamic sampling, which consistently improves training stability and performance across diverse agentic environments.
Dataset
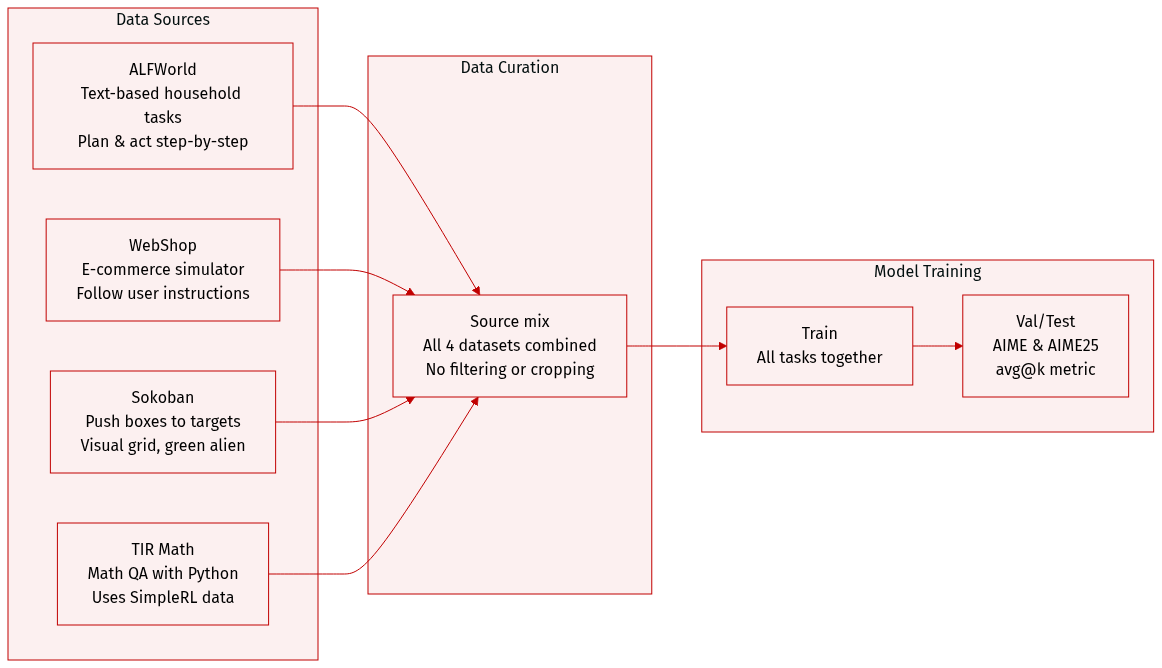
The authors use a multi-task dataset composed of four distinct environments, each designed to evaluate different reasoning and decision-making capabilities:
-
ALFWorld (Shridhar et al., 2020): A text-based interactive environment simulating household tasks. Agents must reason through sequential decisions to complete goals. No size or filtering details are specified; used for training and evaluation of planning and language understanding.
-
WebShop (Yao et al., 2022): A large-scale e-commerce simulator where agents interpret user instructions and navigate product selection and purchase workflows. No explicit size or filtering rules are given; used to test instruction-following and sequential decision-making in realistic settings.
-
Sokoban (Schrader, 2018): A classic 2D grid-based puzzle where agents push boxes onto target tiles. State is visually represented; actions are discrete movements. Visual elements include a green alien character (agent), yellow crates (boxes), and red-outlined black tiles (targets). No size or filtering details provided; used to evaluate spatial reasoning and planning.
-
TIR Math (Xue et al., 2025): Focuses on mathematical QA with Python as a tool for symbolic and intermediate reasoning. Training data adapted from SimpleRL (Zeng et al., 2025); evaluated on AIME and AIME25 benchmarks using avg@k metric (Yu et al., 2025b). Used to test mathematical reasoning and tool integration.
The paper does not specify training split ratios, data mixture proportions, or preprocessing steps such as cropping or metadata construction for these datasets. Visual elements in Sokoban are described for interpretability but no image cropping or transformation is mentioned.
Method
The authors leverage a structured, multi-part framework to design and evaluate policy optimization methods for agentic reinforcement learning with large language models. The overall architecture is organized into four conceptual parts: testbed construction, policy gradient dimension analysis, empirical findings, and a unified algorithmic synthesis.
Refer to the framework diagram, which illustrates the flow from testbed initialization through gradient dimension decomposition to the final SAMPO algorithm. The process begins with Part 1, where the testbed is stabilized through behavior cloning, format penalty enforcement, auxiliary KL regularization, and hyperparameter tuning. Behavior cloning initializes the policy using supervised trajectories from a pretrained model, ensuring the agent starts within a valid behavioral manifold. Format penalties enforce structured output with explicit and tags, reducing invalid rollouts. Auxiliary KL loss constrains policy drift from a reference model, preserving pretrained knowledge while allowing exploration. Finally, task-specific hyperparameter grids are searched to ensure fair evaluation across methods.
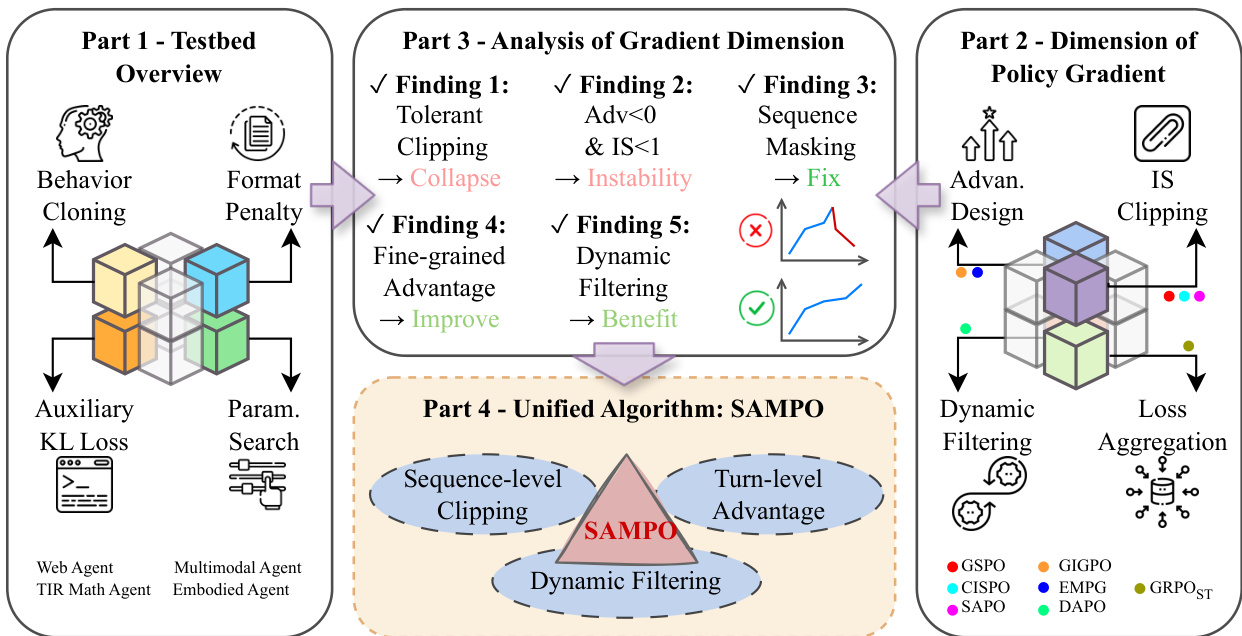
Part 2 decomposes the policy gradient into four orthogonal design dimensions: loss aggregation, importance sampling (IS) clipping, advantage design, and dynamic trajectory filtering. Each dimension is explored independently to isolate its impact on training stability and performance. Loss aggregation schemes include token-mean and sequence-mean variants, which differ in how they weight tokens across trajectories. IS clipping methods range from token-level hard clipping (GRPO) to sequence-level clipping (GSPO), with variants like CISPO and SAPO introducing stop-gradient or soft-attenuation mechanisms. Advantage design incorporates hierarchical credit assignment (GiGPO) or entropy-modulated signals (EMPG) to handle sparse rewards in long-horizon settings. Dynamic filtering removes degenerate trajectories with identical rewards and resamples to increase gradient informativeness.
Part 3 synthesizes empirical findings from ablation studies across these dimensions. Key insights include: (1) training collapse is driven by negative-advantage sequences with low IS ratios, which can be mitigated via sequence masking; (2) sequence-level clipping is more effective than token-level clipping for long-horizon stability; (3) fine-grained advantage estimation improves credit assignment; and (4) dynamic filtering enhances gradient quality by removing uninformative samples.
Part 4 integrates these findings into SAMPO, a unified policy optimization paradigm. SAMPO combines three core components: sequence-level clipping, turn-level advantage estimation, and dynamic trajectory filtering. The loss function is formulated as:
L(θ)=∑i=1NTi1∑i=1N∑t=0Ti−1min(si(θ)Ai′,clip(si(θ),1±ε)Ai′),s.t.0<∣{y∣is_equivalent(a,y)}∣<G.Here, si(θ) is the geometric mean of token-level importance ratios over trajectory i, ensuring sequence-level coherence. The advantage Ai′ combines trajectory-level and step-level signals: Ai′=Ai+ω⋅Astep(y^i,k), where ω controls the contribution of fine-grained credit. The constraint ensures only trajectories with mixed success outcomes are retained, promoting informative gradient updates. This integrated design enables stable, scalable training across diverse agentic tasks.
Experiment
- GSPO with sequence-level clipping delivers the most stable and highest-performing training, outperforming other IS variants by 13.3% on average and preventing collapse seen in tolerant-clipping methods like CISPO and SAPO.
- Tolerant clipping (CISPO, SAPO) enables rapid early gains but causes training collapse due to exploding gradients and KL divergence, primarily driven by negative-advantage tokens with low importance ratios.
- Sequence masking (SAPO_SM, CISPO_SM) effectively stabilizes tolerant-clipping methods by filtering harmful samples, restoring performance to GSPO levels.
- GIGPO, which integrates fine-grained environmental advantage signals, improves performance over GRPO by 16.4% on ALFWorld and enhances reward sparsity handling.
- Dynamic filtering boosts performance only when paired with GIGPO, as its diverse advantage signals preserve format learning; it harms GRPO by removing critical format-correction signals.
- Sequence-mean loss aggregation degrades performance on variable-length tasks like math, highlighting the importance of token-level weighting.
- Off-policy staleness negatively impacts performance; lower staleness (smaller rollout batches) yields higher success rates in both ALFWorld and TIR Math.
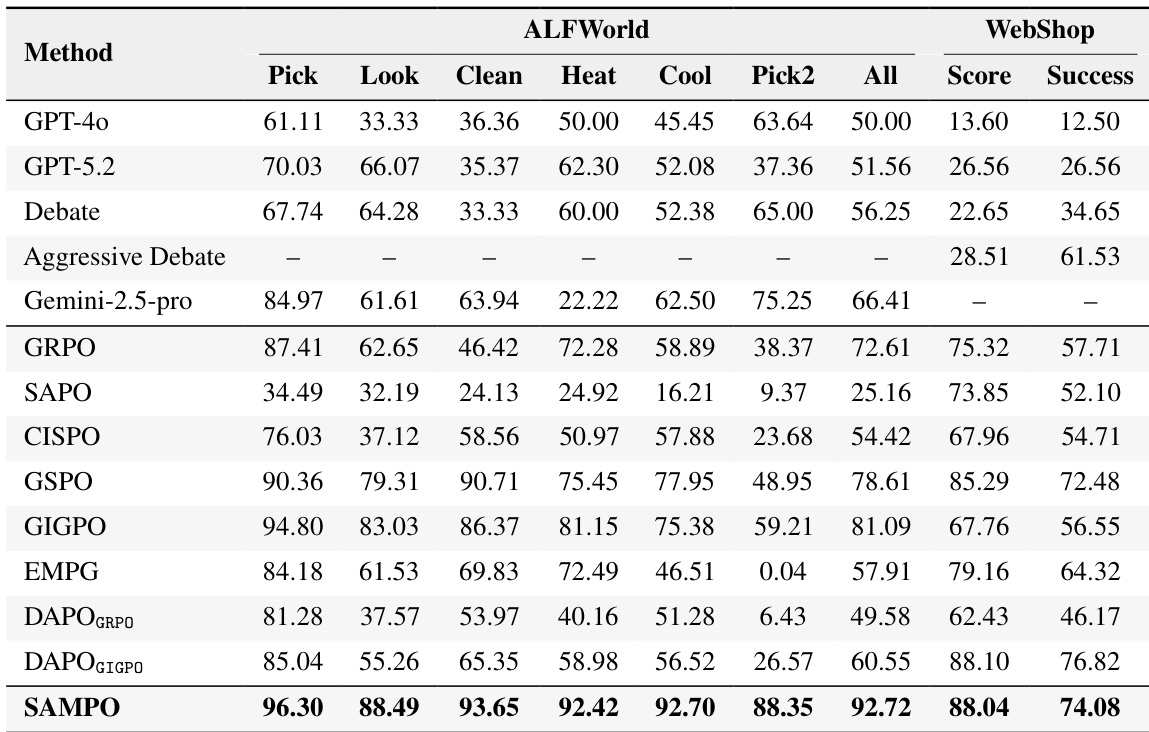
- SAMPO-trained Qwen3-4B outperforms larger closed-source models (GPT-5.2, o3, Gemini 2.5 Pro) on ALFWorld and WebShop, demonstrating that stable RL training can surpass inference-time engineering.
- Findings are scale-invariant: Qwen3-8B experiments confirm that sequence-level clipping, advantage design, and dynamic filtering benefits persist at larger scale, with SAMPO remaining optimal.
- RL training reshapes agent behavior: reduces inefficient pagination loops in WebShop and improves object interaction in ALFWorld, though residual issues like backtracking and premature purchasing remain.
The authors evaluate multiple policy optimization methods across agentic tasks and find that sequence-level clipping (GSPO) yields the most stable training and highest performance, while tolerant clipping methods (CISPO, SAPO) suffer from early collapse despite initial gains. Introducing sequence masking to these tolerant methods recovers stability and performance, bringing them close to GSPO. Their final method, SAMPO, which combines sequence-level clipping, fine-grained advantage design, and dynamic filtering, achieves the best overall results across tasks, outperforming both baseline methods and larger closed-source models.
Results show that lower off-policy staleness improves performance across both ALFWorld and math tasks, with higher success rates and accuracy under low staleness settings. Increased staleness correlates with degraded performance, indicating that policy updates benefit from fresher rollout data. This sensitivity underscores the importance of managing off-policy effects in agentic reinforcement learning.
The authors evaluate stabilization strategies for CISPO and SAPO on ALFWorld, finding that sequence masking significantly improves both methods’ success rates and scores, while increasing the KL penalty or off-policy batch size degrades performance. Results indicate that masking harmful negative-advantage sequences is more effective than regularization or batch-size adjustments for restoring training stability.
The authors evaluate multiple policy optimization strategies across agentic tasks, finding that GSPO with sequence-level clipping consistently outperforms other methods by stabilizing training and improving final success rates. Tolerant clipping variants like SAPO and CISPO show early gains but collapse due to instability from negative-advantage samples, which sequence masking effectively mitigates. Results confirm that stable ARL training depends more on careful importance sampling design than on aggressive exploration or loss aggregation choices.
The authors use a suite of agentic tasks to evaluate policy optimization methods, finding that GSPO and SAMPO consistently outperform others by stabilizing training through sequence-level clipping and refined advantage design. Results show that tolerant clipping methods like SAPO and CISPO initially improve quickly but collapse due to instability from negative-advantage samples, while sequence masking effectively restores performance. SAMPO achieves state-of-the-art success rates, surpassing both closed-source models and multi-agent systems, demonstrating that principled RL training can outperform inference-time engineering.