Command Palette
Search for a command to run...
Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets
Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets
Hanna Yukhymenko Anton Alexandrov Martin Vechev
Abstract
The reliability of multilingual Large Language Model (LLM) evaluation is currently compromised by the inconsistent quality of translated benchmarks. Existing resources often suffer from semantic drift and context loss, which can lead to misleading performance metrics. In this work, we present a fully automated framework designed to address these challenges by enabling scalable, high-quality translation of datasets and benchmarks. We demonstrate that adapting test-time compute scaling strategies, specifically Universal Self-Improvement (USI) and our proposed multi-round ranking method, T-RANK, allows for significantly higher quality outputs compared to traditional pipelines. Our framework ensures that benchmarks preserve their original task structure and linguistic nuances during localization. We apply this approach to translate popular benchmarks and datasets into eight Eastern and Southern European languages (Ukrainian, Bulgarian, Slovak, Romanian, Lithuanian, Estonian, Turkish, Greek). Evaluations using both reference-based metrics and LLM-as-a-judge show that our translations surpass existing resources, resulting in more accurate downstream model assessment. We release both the framework and the improved benchmarks to facilitate robust and reproducible multilingual AI development.
One-sentence Summary
Hanna Yukhymenko, Anton Alexandrov, and Martin Vechev from INSAIT and ETH Zurich propose T-RANK, a multi-round ranking method within an automated framework that preserves linguistic nuance in translating benchmarks into eight European languages, outperforming prior tools for more reliable multilingual LLM evaluation.
Key Contributions
- We identify and analyze critical flaws in existing multilingual benchmarks, showing that separate translation of questions and answers causes semantic drift and context loss, particularly in morphologically complex Eastern and Southern European languages.
- We introduce a fully automated translation framework incorporating test-time scaling methods—especially our novel T-RANK ranking approach and Universal Self-Improvement—to preserve task structure and linguistic nuance, outperforming traditional pipelines across eight target languages.
- We release high-quality translated benchmarks for Ukrainian, Bulgarian, Slovak, Romanian, Lithuanian, Estonian, Turkish, and Greek, validated by reference metrics and LLM-as-a-judge evaluations, enabling more reliable and reproducible multilingual LLM assessment.
Introduction
The authors leverage large language models to address the poor quality of translated multilingual benchmarks, which often suffer from semantic drift and structural misalignment due to reliance on outdated tools or simplistic methods. Prior work fails to preserve task integrity during translation—especially for languages with complex grammar like those in Eastern and Southern Europe—and lacks scalable, configurable pipelines. Their main contribution is a fully automated framework that integrates advanced test-time scaling techniques, including Universal Self-Improvement and their novel T-RANK method, to produce high-fidelity translations while preserving benchmark structure. They release translated versions of key benchmarks into eight target languages, enabling more accurate and reproducible multilingual model evaluation.
Dataset
-
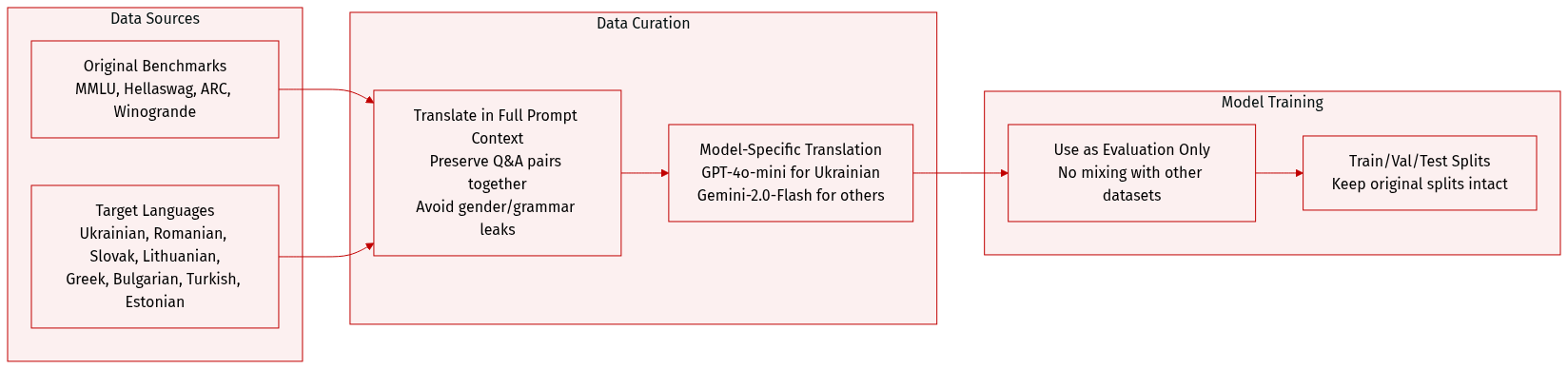
The authors use a custom translation framework to adapt major English benchmarks—MMLU, Hellaswag, ARC, and Winogrande—into eight Eastern and Southern European languages: Ukrainian, Romanian, Slovak, Lithuanian, Greek, Bulgarian, Turkish, and Estonian, chosen for their complex grammar and mid-resource status.
-
For Ukrainian, all benchmarks were translated using GPT-4o-mini-2024-07-18; for other target languages, Gemini-2.0-Flash was used. Translation was performed within full prompt context to preserve semantic coherence and avoid answer leakage from gendered or context-dependent grammar.
-
The dataset includes full training, validation, and test splits from the original benchmarks, with no filtering applied beyond standard benchmark splits. Translation quality was evaluated against prior efforts like MuBench and Global-MMLU, which relied on less context-aware methods or partial human review.
-
No cropping or metadata construction is mentioned. The focus is on prompt-level translation fidelity, ensuring questions and answer options are translated together to maintain task integrity and avoid unintended linguistic bias.
-
The authors do not mix this dataset with others for training; it is used purely for evaluation. Translation models and methods are detailed in Appendix A.2, with quality metrics and comparisons provided in Appendix A.3.
Method
The authors leverage a modular, LLM-driven translation framework designed to adapt to both dataset and benchmark formats, with distinct prompt strategies and data handling to preserve structural integrity—particularly critical in benchmarks where question-answer relationships must remain coherent. The framework supports four configurable translation methods, each optimized for different trade-offs between cost, quality, and linguistic nuance.
The first method, Self-Check (SC), employs zero-shot translation followed by an optional self-evaluation phase. In this phase, a separate LLM instance—without access to prior context—assesses the translation against the original text and corrects detected discrepancies. This approach is economical for high-resource languages but risks hallucinated errors due to the model’s tendency to overcorrect. A few-shot variant can be enabled to guide the model toward language-specific translation pitfalls.
Best-of-N sampling (BoN) draws from test-time compute scaling principles, generating N diverse translations at elevated temperature (0.7) and prompting the LLM to score each on a 1–10 scale based on predefined criteria. The highest-scoring candidate is selected. While language-agnostic and cost-efficient, BoN suffers from LLM limitations in numerical scoring and positional bias, often favoring earlier candidates even when errors are evident.
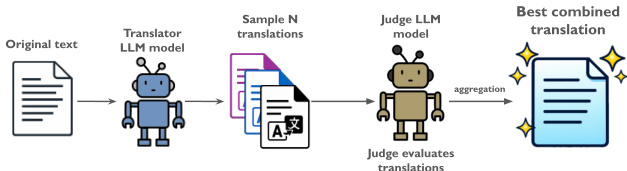
Universal Self-Improvement (USI) builds on self-consistency and fusion paradigms, recognizing that consensus does not guarantee optimality. As shown in the figure below, the method samples N translations, then instructs a judge LLM to synthesize a superior version by extracting the best features from all candidates according to specified evaluation criteria. This fusion step is executed once per entry, requiring only N+1 model calls, and effectively addresses language-specific nuances. The workflow emphasizes selective aggregation rather than blind merging, reducing error propagation.
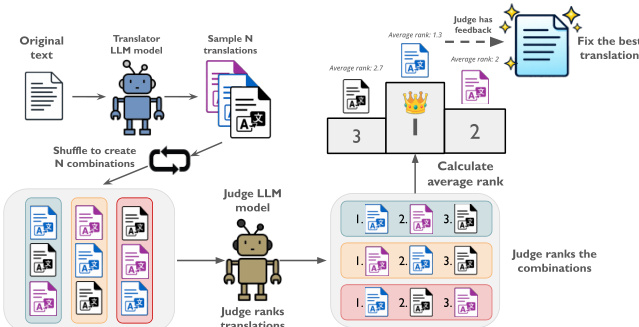
Translation Ranking (T-RANK) refines prior ranking-based approaches by introducing a multi-round positional shuffling mechanism to mitigate LLM evaluation biases. As illustrated in the figure below, N translations are sampled and then presented across N rounds, each time in a different order, ensuring every candidate occupies every position exactly once. A judge LLM ranks the candidates per round based on quality, domain consistency, and fidelity to the original intent. The average rank determines the top candidate, which is then optionally refined in a final correction phase where all candidates are presented again to the judge. This method requires 2N+1 model calls and significantly reduces positional bias while enabling deeper error detection through comparative reasoning.
To standardize evaluation, the authors provide structured prompts for judge LLMs, as exemplified in the figure below. These prompts require the model to analyze two translations against a checklist, articulate comparative reasoning, and output a JSON-formatted verdict specifying which translation is superior or if they are equal. This structured output ensures reproducibility and enables automated aggregation of quality signals across multiple evaluations.

Each method is configurable via prompts and parameters, allowing users to tailor the framework to specific language pairs, domain constraints, or budgetary limits. The authors emphasize that while BoN and USI offer quality improvements over baseline translation, T-RANK’s competitive ranking mechanism proves superior in detecting subtle, context-sensitive translation errors.
Experiment
- USI and T-RANK outperform baseline methods on FLORES and WMT24++ benchmarks, with COMET scores indicating strong translation quality, though neither consistently dominates the other.
- T-RANK excels in translating complex, question-based benchmarks where preserving context and avoiding answer leakage is critical, while USI performs better on shorter, simpler texts.
- LLM-as-a-judge evaluations (using Gemini-2.5-Flash) confirm superior translation quality of both methods over existing benchmarks across Ukrainian, Romanian, and Lithuanian.
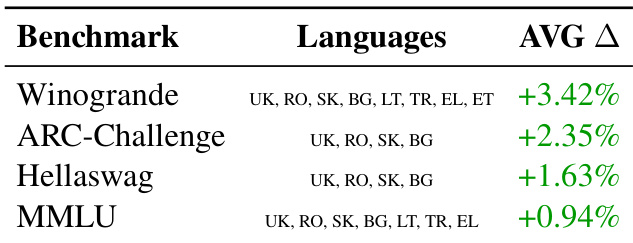
- Mid-sized models (Gemma 3, Qwen 3, Llama 3.1) achieve higher scores on translated benchmarks, validating improved evaluation reliability—especially on Winogrande, where contextual integrity is vital.
- Reference-free COMET evaluations further support quality gains, particularly on longer, complex texts in MMLU and FLORES.
- Translation errors in existing benchmarks—such as gender-based answer leakage or broken cohesion—are systematically corrected by the proposed methods.
- Performance varies by model: Gemini-2.0-Flash shows stronger T-RANK results, suggesting method suitability depends on model architecture and task complexity.
- Human-translated benchmarks (e.g., Bulgarian Winogrande) still outperform automated ones in select cases, indicating residual need for human oversight in specific language-benchmark combinations.
- The framework balances accuracy, efficiency, and scalability but has limitations, including reliance on closed-source models, lack of adaptive difficulty handling, and potential positional bias in ranking.
The authors evaluate mid-sized language models on translated benchmarks using their proposed methods versus existing translations, finding consistent performance gains for most models, particularly on Winogrande where contextual preservation is critical. While most models show improved scores on the authors’ translations, Qwen3-8B-IT underperforms on Winogrande, indicating that translation quality impacts evaluation outcomes unevenly across models and benchmarks. These results support the framework’s effectiveness in enhancing multilingual benchmark reliability, though model-specific behavior suggests translation strategies may need tailoring.
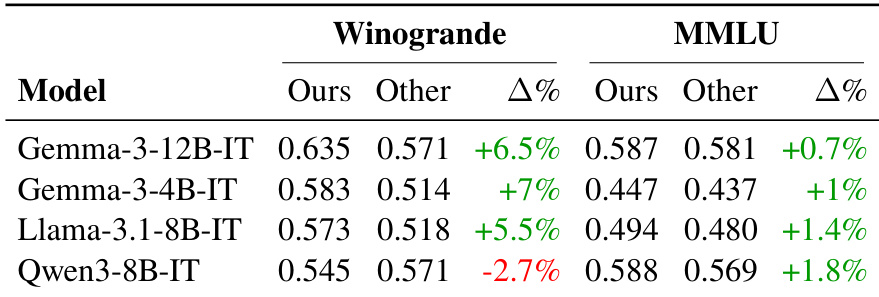
The authors evaluate mid-sized language models on translated benchmarks using their proposed methods versus existing translations, finding consistent score improvements across most benchmarks and languages. Notably, Winogrande shows the largest gains, attributed to better preservation of contextual and grammatical integrity during translation. Results confirm that enhanced translation quality directly contributes to more reliable model evaluations, though some benchmarks still benefit from professional human translation.
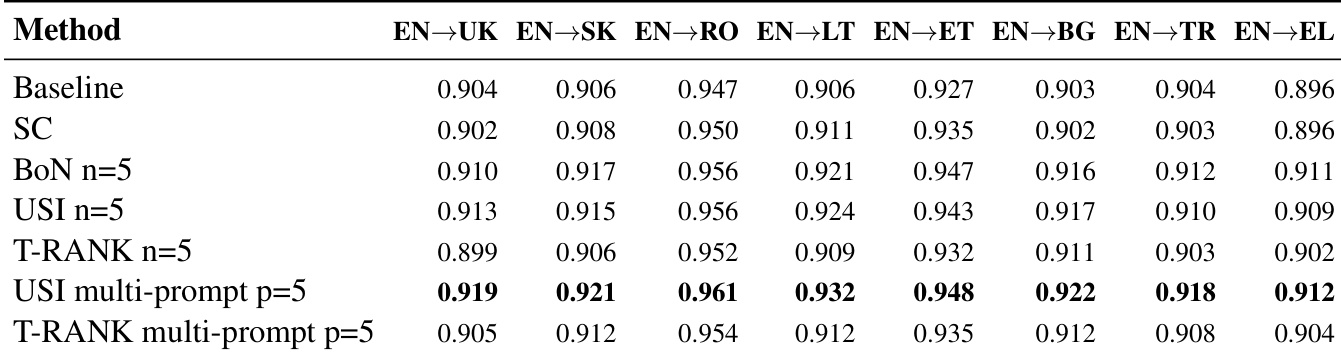
The authors use multi-prompt and candidate sampling strategies to improve machine translation quality across several European languages, with USI multi-prompt consistently achieving the highest COMET scores. Results show that combining multiple translation prompts enhances performance more reliably than increasing candidate samples alone, particularly for languages like Romanian and Estonian. While T-RANK multi-prompt also delivers strong results, USI multi-prompt demonstrates broader consistency across language pairs in this evaluation setup.
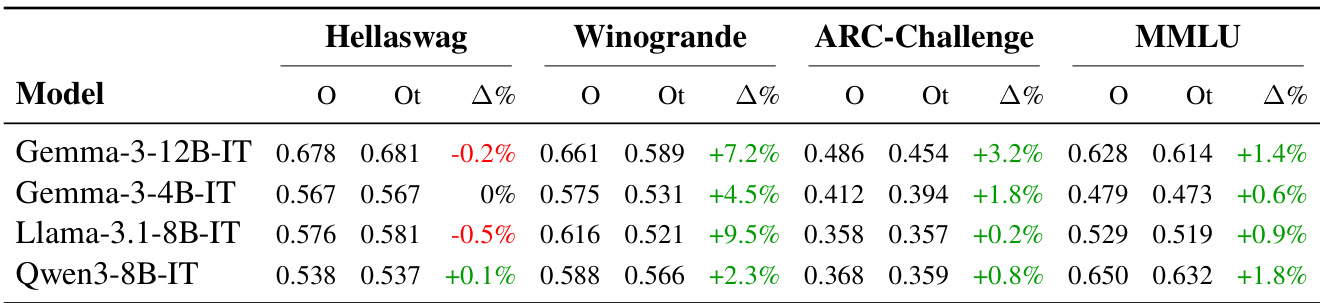
The authors evaluate mid-sized language models on translated benchmarks using their proposed methods versus existing translations, observing consistent performance gains across Winogrande and MMLU. Results show that models like Gemma-3, Llama-3.1, and Qwen-3 achieve higher scores on the improved translations, indicating enhanced translation quality contributes to more reliable model evaluations. These improvements are particularly pronounced in Winogrande, where preserving contextual and grammatical integrity is critical for accurate assessment.
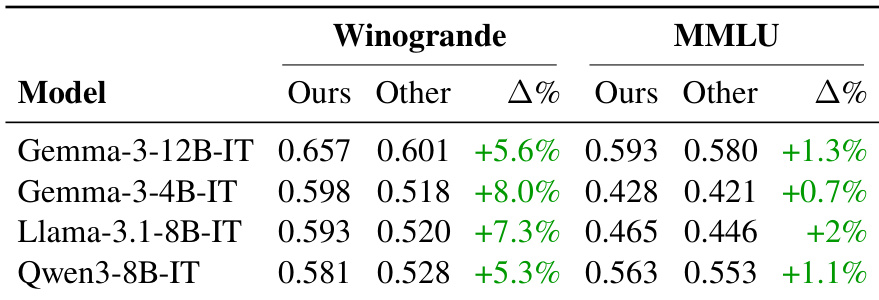
The authors use their proposed translation framework to evaluate performance across multiple benchmarks, observing consistent improvements in model evaluation scores when using their translated datasets compared to existing ones. Results show the largest gains on Winogrande, where preserving contextual and grammatical integrity during translation significantly enhances evaluation reliability. The framework demonstrates broad effectiveness across languages, though the magnitude of improvement varies by benchmark and linguistic complexity.