Command Palette
Search for a command to run...
dLLM: Simple Diffusion Language Modeling
dLLM: Simple Diffusion Language Modeling
Zhanhui Zhou Lingjie Chen Hanghang Tong Dawn Song
Abstract
Although diffusion language models (DLMs) are evolving quickly, many recent models converge on a set of shared components. These components, however, are distributed across ad-hoc research codebases or lack transparent implementations, making them difficult to reproduce or extend. As the field accelerates, there is a clear need for a unified framework that standardizes these common components while remaining flexible enough to support new methods and architectures. To address this gap, we introduce dLLM, an open-source framework that unifies the core components of diffusion language modeling -- training, inference, and evaluation -- and makes them easy to customize for new designs. With dLLM, users can reproduce, finetune, deploy, and evaluate open-source large DLMs such as LLaDA and Dream through a standardized pipeline. The framework also provides minimal, reproducible recipes for building small DLMs from scratch with accessible compute, including converting any BERT-style encoder or autoregressive LM into a DLM. We also release the checkpoints of these small DLMs to make DLMs more accessible and accelerate future research.
One-sentence Summary
Researchers from UC Berkeley and UIUC introduce dLLM, a unified open-source framework that standardizes training, inference, and evaluation of diffusion language models, enabling easy reproduction, customization, and deployment of models like LLaDA and Dream while lowering entry barriers via lightweight recipes and released checkpoints.
Key Contributions
- dLLM introduces a unified, open-source framework that standardizes training, inference, and evaluation for diffusion language models, enabling reproducible development and easy customization across architectures like LLaDA and Dream.
- The framework provides minimal, end-to-end recipes to convert existing BERT-style encoders or autoregressive LMs into DLMs using accessible compute, along with released checkpoints to lower entry barriers for new researchers.
- dLLM supports plug-and-play inference algorithms and unified evaluation interfaces, facilitating fair comparisons and accelerated iteration across models without requiring architectural changes or extensive compute resources.
Introduction
The authors leverage the growing momentum in diffusion language modeling (DLMs), which offer advantages like iterative refinement and efficient decoding, but face fragmentation due to scattered, non-reproducible codebases. Prior work lacks standardized pipelines for training, inference, and evaluation, making it hard to reproduce or compare models—even though many share similar components. Their main contribution is dLLM, an open-source framework that unifies these three core stages into a modular, extensible pipeline, enabling users to reproduce, finetune, and evaluate models like LLaDA and Dream, while also providing lightweight recipes to convert existing BERT or autoregressive LMs into DLMs using minimal compute.
Method
The authors leverage a modular training and inference framework designed to unify discrete diffusion language modeling (DLM) workflows. At the core of this architecture is a flexible trainer interface that supports both Masked Diffusion (MDLM) and Block Diffusion (BD3LM) objectives, enabling seamless transitions between pretraining, supervised fine-tuning (SFT), and adaptation from autoregressive LMs. The training pipeline is built atop the HuggingFace ecosystem, integrating accelerate for distributed training and peft for parameter-efficient tuning, while custom trainers such as MDLMTrainer serve as lightweight wrappers around the standard transformers Trainer. This design allows users to switch between training paradigms—such as swapping MDLMTrainer for BD3LMTrainer or adapting an autoregressive model to MDLM—with minimal code changes, such as toggling arguments like right_shift_logits or wrapping the data collator with PrependBOSWrapper.
For inference, the framework introduces a unified Sampler abstraction that decouples model architecture from decoding strategy. This enables plug-and-play substitution of samplers—for instance, replacing the standard MDLMSampler with the accelerated MDLMFastdLLMSampler—without modifying the underlying model. As shown in the figure below, this interface supports both vanilla and optimized inference paths while preserving compatibility with existing model implementations.

To enhance interpretability, the framework includes a TerminalVisualizer that tracks and displays the token decoding order during inference. Unlike autoregressive models that decode strictly left-to-right, DLMs decode tokens in arbitrary order, making the decoding trajectory a critical diagnostic feature. The visualizer renders the progressive unmasking of tokens, as illustrated in the figure below, which shows the evolution of a generated response from fully masked to fully decoded, along with real-time metrics such as masks decoded and elapsed time.

The training objective for MDLM minimizes the time-weighted negative log-likelihood of unmasked tokens, formalized as:
LMDLM=Et∼U(0,1),x0[t1i∈Mt∑−logpθ(x0i∣xt)].For BD3LM, the loss is block-wise and conditioned on previously generated blocks, expressed as:
LBD3LM=k=1∑KEt∼U(0,1),x0t1i∈mask(Bk,t)∑−logpθ(x0i∣xtBk,x<Bk).This factorization enables parallel generation within blocks while leveraging cached key-value states from prior blocks, improving both efficiency and scalability.
Experiment
- MDLM pretraining and subsequent fine-tuning (SFT or BD3LM) validate that diffusion language models can be effectively adapted for reasoning and instruction-following tasks using a unified trainer interface.
- Evaluation experiments confirm that DLM performance is highly sensitive to inference hyperparameters, necessitating a flexible, reproducible evaluation framework that closely matches official results across models and tasks.
- Finetuning open-weight DLMs (LLaDA, Dream) via MDLM SFT improves reasoning capabilities, particularly in instruct variants, though base models may regress on out-of-distribution tasks.
- BERT-style models can be converted into functional diffusion chatbots via SFT alone, achieving competitive performance on select benchmarks despite lacking architectural modifications for generation.
- Autoregressive models (e.g., Qwen3) can be efficiently converted to DLMs (MDLM or BD3LM) using SFT, yielding strong code generation results and demonstrating practicality of AR-to-diffusion conversion without continual pretraining.
- Training curves and reproduction tables confirm stable convergence and faithful replication of official evaluation scores, validating the consistency and reliability of the dLLM framework.
The authors use their unified dLLM framework to reproduce evaluation results for LLaDA-Base, showing close alignment with official scores across multiple benchmarks while enabling consistent cross-model comparisons. Results show that their implementation achieves comparable or slightly improved performance on tasks like MMLU and GSM8K, validating the fidelity of their evaluation pipeline. This reproducibility supports the use of their framework for fair and standardized assessment of diffusion language models.

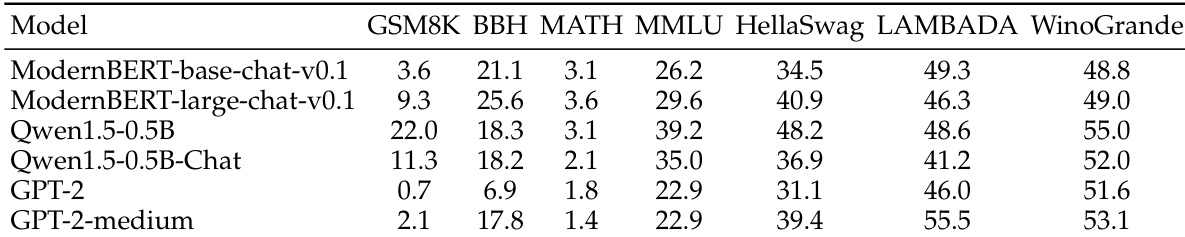
The authors evaluate ModernBERT-based chat models alongside comparable decoder-only models and find that, despite being encoder-only architectures, they outperform GPT-2 variants on most benchmarks and even surpass Qwen1.5-0.5B-Chat on BBH and MATH. Results indicate that BERT-style models can serve as viable backbones for diffusion language models without architectural modifications, though they still lag behind similarly sized autoregressive models on knowledge-intensive tasks.
The authors use a unified evaluation framework to reproduce results for LLaDA-Base, showing that their dLLM implementation closely matches or slightly exceeds official scores across multiple benchmarks. This indicates the framework reliably captures model performance while enabling consistent cross-model comparisons. The findings underscore the importance of precise inference configurations in evaluating diffusion language models.

The authors use a unified evaluation framework to reproduce results for LLaDA-Base, showing close alignment with official scores across multiple benchmarks, though slight variations appear in tasks like BBH and HellaSwag. This confirms the framework’s ability to faithfully replicate prior work while enabling consistent cross-model comparisons. The minor discrepancies highlight the sensitivity of diffusion language models to evaluation configurations, even under matched settings.

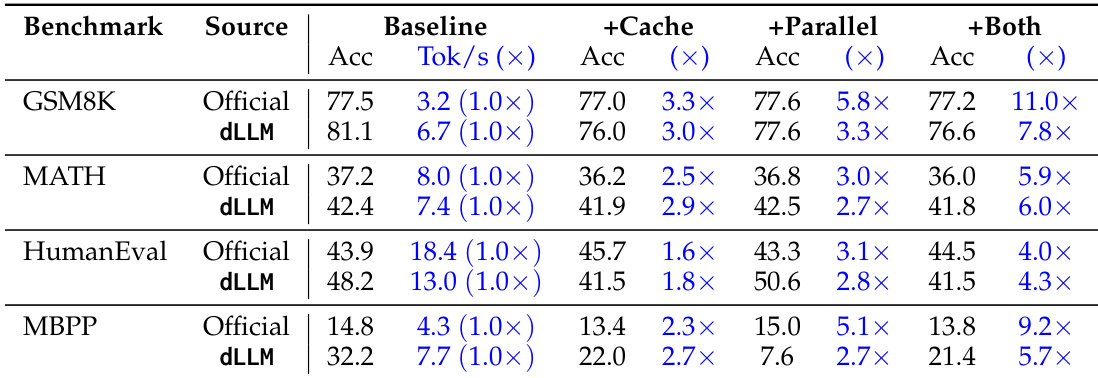
The authors use their dLLM framework to evaluate performance gains from caching and parallel decoding across multiple benchmarks, showing that combining both optimizations consistently delivers the highest speedups while maintaining accuracy close to baseline levels. Results show that parallel decoding alone provides substantial throughput improvements, and adding caching further amplifies efficiency without significant accuracy loss. These findings highlight the practical value of their unified evaluation pipeline in isolating and quantifying the impact of inference-level optimizations.