Command Palette
Search for a command to run...
Imagination Helps Visual Reasoning, But Not Yet in Latent Space
Imagination Helps Visual Reasoning, But Not Yet in Latent Space
You Li Chi Chen Yanghao Li Fanhu Zeng Kaiyu Huang Jinan Xu Maosong Sun
Abstract
Latent visual reasoning aims to mimic human's imagination process by meditating through hidden states of Multimodal Large Language Models. While recognized as a promising paradigm for visual reasoning, the underlying mechanisms driving its effectiveness remain unclear. Motivated to demystify the true source of its efficacy, we investigate the validity of latent reasoning using Causal Mediation Analysis. We model the process as a causal chain: the input as the treatment, the latent tokens as the mediator, and the final answer as the outcome. Our findings uncover two critical disconnections: (a) Input-Latent Disconnect: dramatic perturbations on the input result in negligible changes to the latent tokens, suggesting that latent tokens do not effectively attend to the input sequence. (b) Latent-Answer Disconnect: perturbations on the latent tokens yield minimal impact on the final answer, indicating the limited causal effect latent tokens imposing on the outcome. Furthermore, extensive probing analysis reveals that latent tokens encode limited visual information and exhibit high similarity. Consequently, we challenge the necessity of latent reasoning and propose a straightforward alternative named CapImagine, which teaches the model to explicitly imagine using text. Experiments on vision-centric benchmarks show that CapImagine significantly outperforms complex latent-space baselines, highlighting the superior potential of visual reasoning through explicit imagination.
One-sentence Summary
Researchers from Tsinghua University and Alibaba propose CapImagine, a text-based explicit imagination method that outperforms latent reasoning in vision tasks by bypassing ineffective hidden state mediation, revealing latent tokens’ weak causal links and limited visual encoding, thus redefining efficient visual reasoning.
Key Contributions
- Using Causal Mediation Analysis, the study reveals that latent tokens in multimodal models show minimal causal influence—both from input to latent states and from latent states to final answers—indicating they neither attend meaningfully to inputs nor drive reasoning outcomes.
- The authors propose CapImagine, a text-based imagination method that replaces latent-space reasoning by training models to simulate visual operations via textual descriptions, offering a more interpretable and causally grounded alternative.
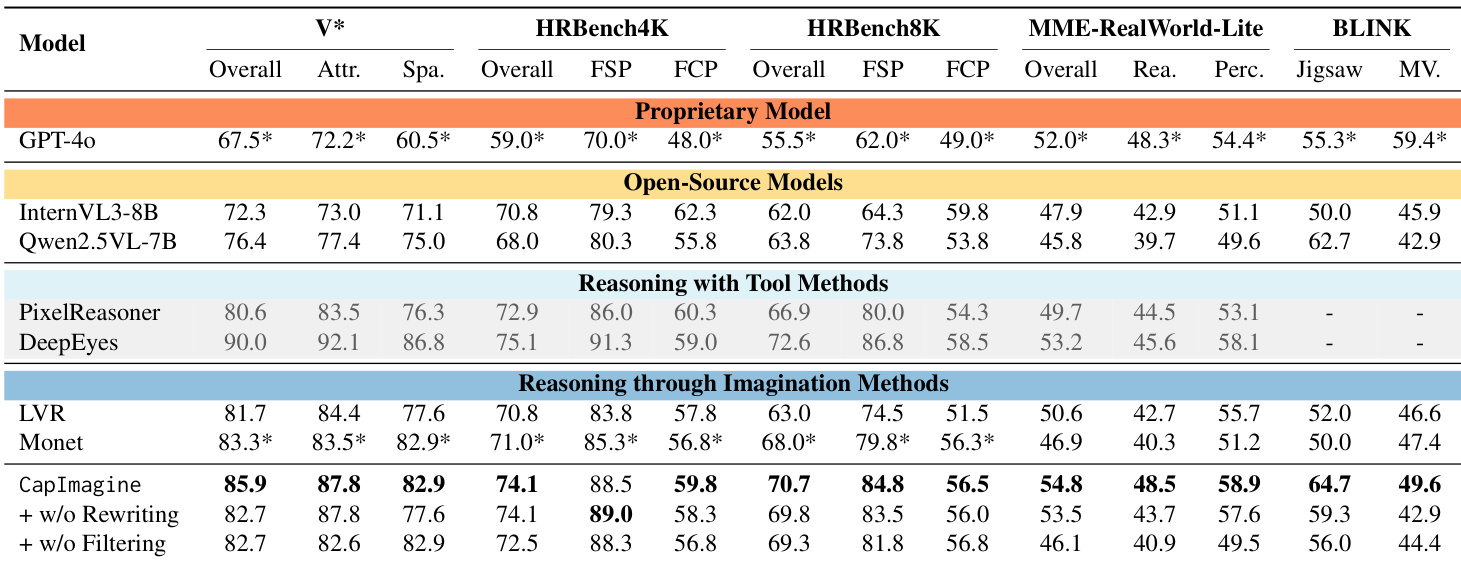
- CapImagine achieves significant performance gains over latent-space baselines, improving by 4.0% on HR-Bench-8K and 4.9% on MME-RealWorld-Lite, demonstrating the effectiveness of explicit textual imagination for visual reasoning.
Introduction
The authors leverage causal mediation analysis to probe whether latent visual reasoning in multimodal LLMs actually functions as intended—by encoding and propagating visual semantics through hidden states. They find that latent tokens show minimal sensitivity to input changes and exert negligible causal influence on final answers, indicating a breakdown in both input-to-latent and latent-to-output pathways. Prior latent-space methods, while empirically strong, lack interpretability and fail to encode meaningful visual information. In response, the authors introduce CapImagine, a text-based alternative that converts visual manipulations into explicit textual descriptions during training. This approach not only restores causal fidelity but also outperforms latent-space baselines across multiple vision-centric benchmarks, suggesting that explicit textual imagination is more effective than hidden-state reasoning for visual tasks.
Dataset

-
The authors use Monet-SFT-125K as the base dataset and enhance it through two forms of image rewriting: for Visual-CoT and Zebra-CoT subsets (focused on zoomed regions), they feed the original question and highlighted image region to Qwen3-VL-4B to generate concise captions that refocus visual semantics; for Refocus and CogCoM subsets (involving image manipulations like marking or drawing), they input both original and manipulated images to Qwen3-VL-4B, prompting it to describe visual differences and verbalize key information revealed by the manipulations.
-
To ensure smooth integration of rewritten text into reasoning chains, they use an MLLM to globally refine the reasoning trajectories, correcting inconsistencies and improving fluency so that new textual descriptions align logically with the original reasoning process.
-
Despite Monet-SFT-125K’s prior filtering, the Visual-CoT subset (94.88% of the dataset) contains low-quality instances—many with answer-reasoning misalignment or ambiguous/unanswerable questions—so the authors apply automated quality filtering via MLLM to assess reasoning correctness and question clarity, retaining only 17k high-quality instances after manual validation.
-
To ensure fair comparison with Monet, they conduct ablation studies in Section 5.3 to account for the reduced dataset size, maintaining a controlled training setting throughout experiments.
Method
The authors leverage a novel paradigm called Latent Visual Reasoning, wherein the final hidden states of a transformer-based multimodal language model (MLLM) are treated as latent tokens to mediate visual question answering. This approach enables the model to dynamically alternate between generating standard text tokens and latent tokens during decoding, effectively decoupling perceptual reasoning from linguistic output. The overall framework operates under the abstracted causal flow X→Z→Y, where X represents the joint input of images and question, Z denotes the latent reasoning tokens, and Y is the final answer.
During inference, the model initiates latent mode upon emitting the special token <llatent_start> and exits upon decoding <llatent_end>. Within latent mode, the model consumes its own last hidden state as input for the next step, bypassing explicit tokenization. The decoding rule is formally defined as:
hi=M(E(x);y<i),y0=∅ yi=I(i∈IL)⋅ϕ(hi)+I(i∈/IL)⋅E(Decode(hi))where IL indexes latent token positions, ϕ(hi) is an optional projection, and E(⋅) maps hidden states to embeddings. This mechanism allows the model to internally simulate visual operations—such as drawing lines or highlighting regions—without emitting intermediate text, thereby preserving reasoning fidelity.
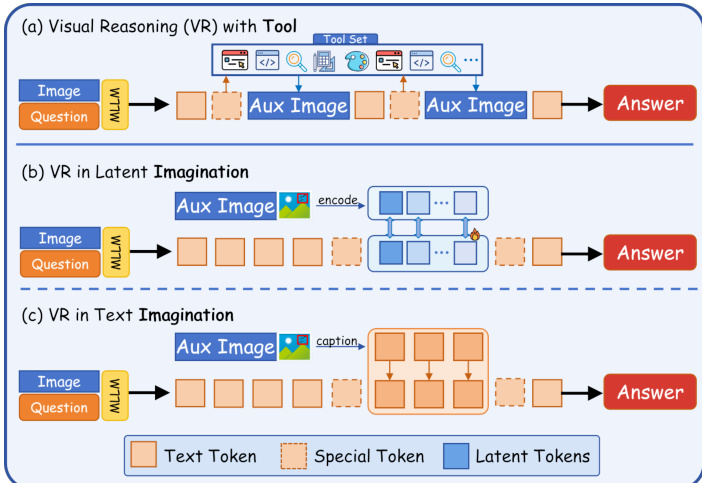
Refer to the framework diagram illustrating three distinct visual reasoning modalities: (a) VR with Tool, where external tools generate auxiliary images; (b) VR in Latent Imagination, where latent tokens encode internal visual simulations; and (c) VR in Text Imagination, where reasoning is verbalized as descriptive captions. The authors focus on the latent imagination pathway, which avoids explicit tool invocation and instead relies on the model’s internal representation space to perform visual manipulations.
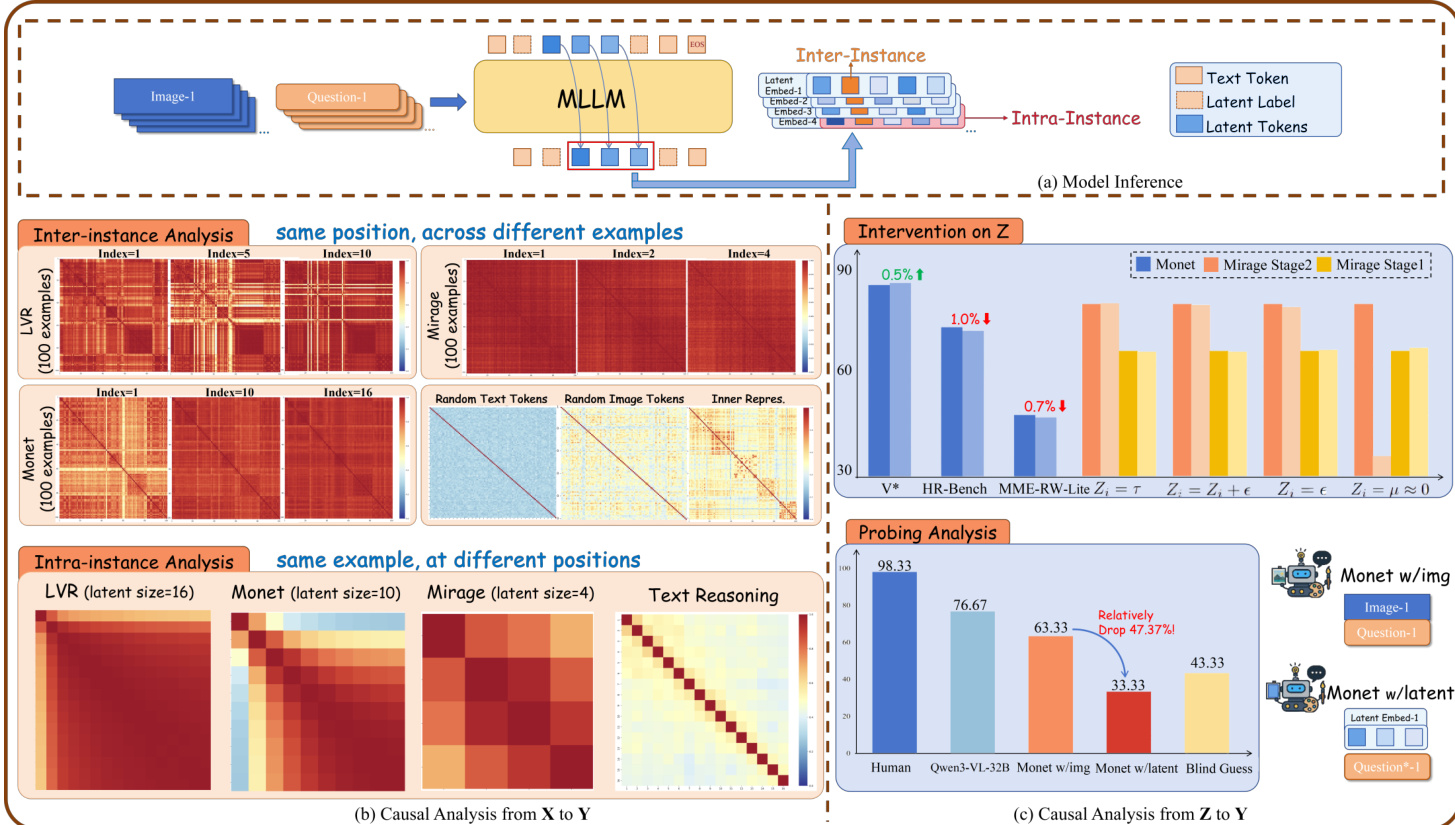
The model’s inference architecture, as shown in the figure below, integrates image and question inputs into an MLLM, which generates a sequence of text tokens, special tokens, and latent tokens. The latent tokens are processed within an intra-instance context, while inter-instance analysis compares latent representations across different examples. The authors conduct causal interventions on Z—such as perturbing latent embeddings or replacing them with random values—to quantify their contribution to final answer accuracy. Probing experiments further reveal that models relying on latent tokens exhibit significant performance drops when these tokens are removed, underscoring their critical role in visual reasoning.
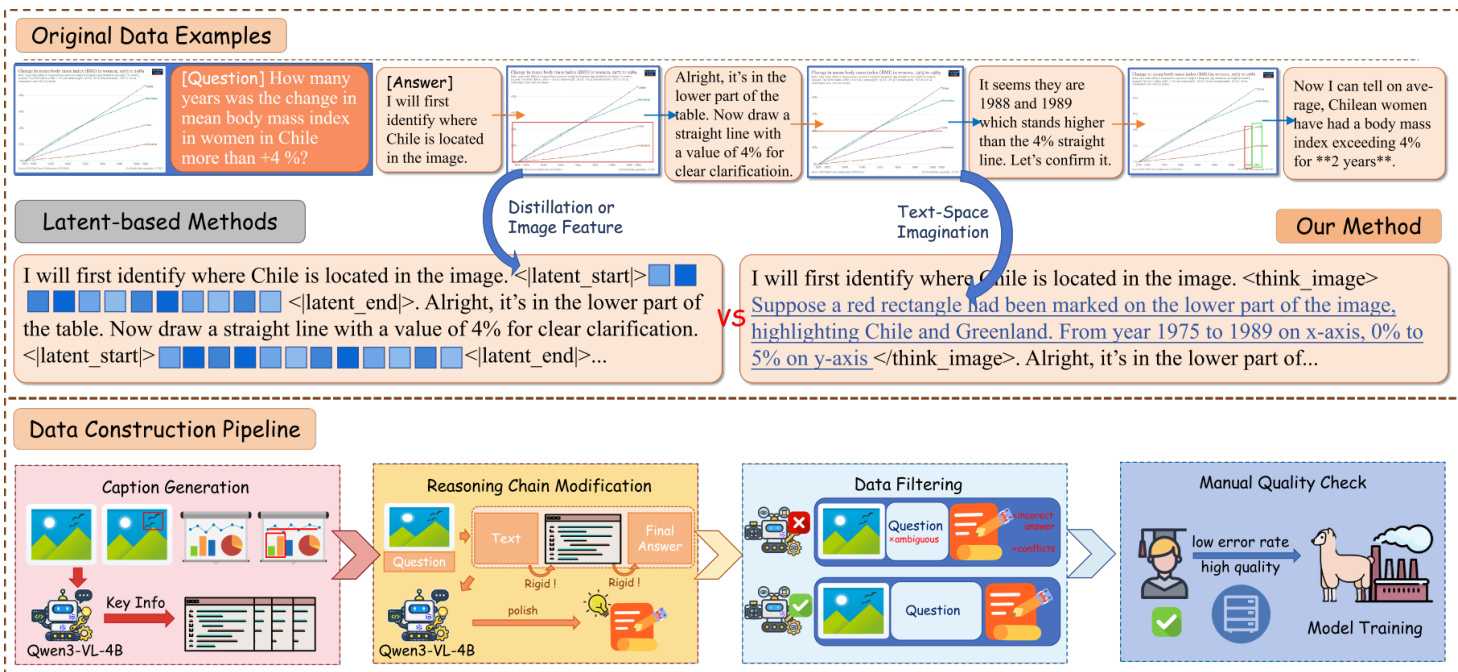
To train and evaluate this paradigm, the authors construct a dataset pipeline that begins with caption generation using Qwen3-VL-4B, followed by reasoning chain modification to insert latent token markers. Data filtering removes ambiguous or conflicting examples, and a manual quality check ensures high fidelity before model training. The resulting method enables the model to simulate visual operations—such as marking regions or drawing lines—within the latent space, as opposed to relying on external tools or verbose textual descriptions. This is contrasted with latent-based baselines that either distill image features or perform text-space imagination, both of which lack the precision of latent token mediation.
Experiment
- Latent tokens across models and tasks show high similarity, collapsing into uniform representations during reasoning, indicating minimal encoding of input or task-specific information.
- Interventions on latent tokens cause negligible changes to final answers, suggesting they exert little causal influence on model outputs.
- Probing analysis reveals latent tokens encode limited visual semantics and are insufficient for accurate answer derivation, even when trained to capture visual evidence.
- Text-driven visual imagination outperforms latent-space methods across perception and reasoning benchmarks, demonstrating stronger causal mediation and better generalization.
- Ablation studies confirm text-based imagination descriptions are critical; removing them degrades performance, while data filtering improves alignment and effectiveness.
- Text-form reasoning exhibits strong causal dependency between input and imagination tokens, with interventions on imagination content sharply degrading performance.
- Despite longer sequences, text-based reasoning achieves inference speed comparable to latent methods and faster than tool-augmented approaches, offering a favorable efficiency-performance trade-off.
- Current latent tokens behave more like soft prompts than active carriers of visual reasoning, highlighting a gap in leveraging latent space for causal, informative reasoning.
Results show that drastically altering latent tokens in Monet leads to minimal performance changes across multiple benchmarks, indicating these tokens exert limited causal influence on final answers. The model appears to rely on alternative pathways rather than the latent reasoning process, as even forced uniformity of latent states does not significantly degrade output quality.
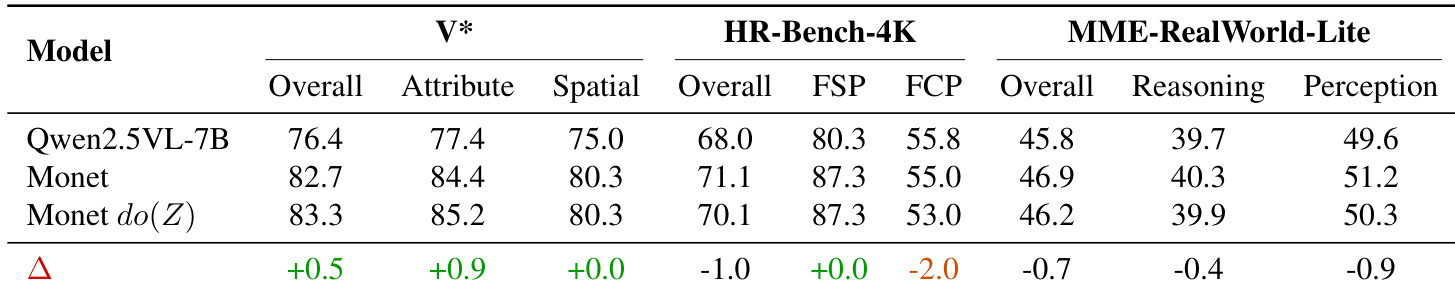
The authors use causal mediation analysis to test the impact of altering latent reasoning tokens on final answers, finding that drastic interventions cause only minimal performance changes. Results show that latent tokens exhibit high similarity across instances and tasks, progressively collapsing into uniform representations, and contribute little to answer derivation. In contrast, text-based reasoning processes demonstrate stronger causal influence and semantic diversity, suggesting latent tokens currently function more as placeholders than active reasoning carriers.
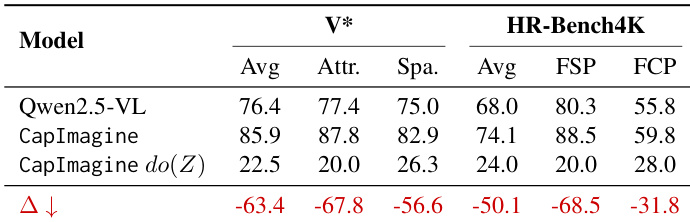
Results show that drastic interventions on latent tokens in Mirage—such as replacing them with noise or near-zero values—cause minimal performance changes in Stage 1, but trigger severe degradation in Stage 2, indicating that Stage 2 relies more critically on latent token integrity. The authors use this to argue that latent tokens generally exert limited causal influence on final outputs, except under extreme interventions that disrupt model behavior entirely.

The authors use a text-driven visual imagination approach that consistently outperforms latent-space methods like Monet and LVR across multiple benchmarks, particularly in fine-grained perception and abstract reasoning tasks. Results show that latent tokens exhibit high similarity across instances and tasks, collapse during reasoning, and exert minimal causal influence on final answers, suggesting they function more as placeholders than active reasoning carriers. In contrast, text-based imagination demonstrates strong causal dependency and significantly impacts performance, offering a more effective and efficient reasoning pathway.
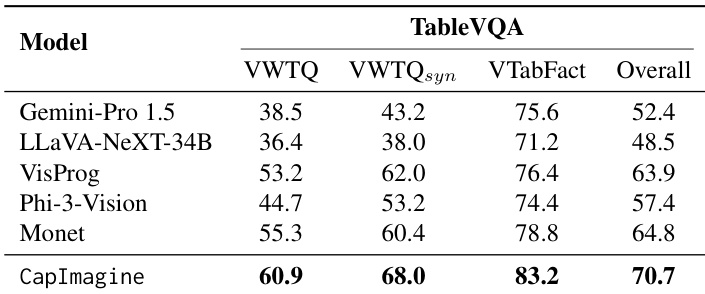
CapImagine outperforms all compared models on the TableVQA benchmark, achieving the highest scores across all subcategories and overall. The results indicate that text-driven visual imagination enhances performance in tasks requiring structured reasoning over tabular data. This suggests that explicit textual reasoning pathways can be more effective than latent-space approaches for such visual reasoning challenges.