Command Palette
Search for a command to run...
From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models
From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models
Hongrui Jia Chaoya Jiang Shikun Zhang Wei Ye
Abstract
As Large Multimodal Models (LMMs) scale up and reinforcement learning (RL) methods mature, LMMs have made notable progress in complex reasoning and decision making. Yet training still relies on static data and fixed recipes, making it difficult to diagnose capability blind spots or provide dynamic, targeted reinforcement. Motivated by findings that test driven error exposure and feedback based correction outperform repetitive practice, we propose Diagnostic-driven Progressive Evolution (DPE), a spiral loop where diagnosis steers data generation and reinforcement, and each iteration re-diagnoses the updated model to drive the next round of targeted improvement. DPE has two key components. First, multiple agents annotate and quality control massive unlabeled multimodal data, using tools such as web search and image editing to produce diverse, realistic samples. Second, DPE attributes failures to specific weaknesses, dynamically adjusts the data mixture, and guides agents to generate weakness focused data for targeted reinforcement. Experiments on Qwen3-VL-8B-Instruct and Qwen2.5-VL-7B-Instruct show stable, continual gains across eleven benchmarks, indicating DPE as a scalable paradigm for continual LMM training under open task distributions. Our code, models, and data are publicly available at https://github.com/hongruijia/DPE.
One-sentence Summary
Hongrui Jia and Chaoya Jiang et al. propose Diagnostic-driven Progressive Evolution (DPE), a self-improving loop that diagnoses LMM weaknesses and generates targeted multimodal data for reinforcement, outperforming static training across eleven benchmarks and enabling scalable, continual LMM evolution under open-ended tasks.
Key Contributions
- DPE introduces a diagnostic-driven training loop for Large Multimodal Models that identifies capability blind spots and dynamically generates targeted, weakness-focused data using multi-agent tool-augmented annotation, overcoming limitations of static datasets and heuristic-based evolution.
- Applied to Qwen3-VL-8B-Instruct and Qwen2.5-VL-7B-Instruct, DPE achieves stable, continual improvements across eleven multimodal reasoning benchmarks using only 1000 training examples per iteration, demonstrating efficiency and scalability under open task distributions.
- Systematic analysis confirms that DPE’s diagnosis mechanism enhances training stability and mitigates long-tail performance degradation, offering a principled approach to continual model improvement without relying on expensive human annotations or fixed data recipes.
Introduction
The authors leverage diagnostic feedback to address key limitations in training Large Multimodal Models (LMMs), where prior self-evolution methods rely on heuristic signals and static visual data, leading to unstable training and poor long-tail performance. Existing frameworks lack interpretable failure attribution and struggle to generate diverse, targeted multimodal samples, causing models to plateau or regress on complex tasks like math or OCR. Their main contribution is Diagnostic-driven Progressive Evolution (DPE), a closed-loop training paradigm that diagnoses model weaknesses, dynamically generates tailored multimodal data using multi-agent tool use, and reinforces improvements iteratively—resulting in stable, broad gains across benchmarks with minimal data.
Method
The authors leverage Diagnostic-driven Progressive Evolution (DPE), a closed-loop training framework designed to enhance large multimodal models (LMMs) under conditions of scarce supervision and long-tail coverage gaps. Unlike prior self-evolution methods that rely on static image sets and heuristic signals, DPE iteratively executes diagnosis, targeted generation, and reinforcement-based updating. Each iteration explicitly controls both the category composition and question emphasis of the training data, aligning resources with the model’s current capability blind spots to mitigate instability and diminishing returns on long-tail skills.
At iteration k, the policy is denoted as πθ(k). The framework constructs a training set T(k) and updates parameters to θ(k+1) via reinforcement learning with verifiable rewards:
θ(k+1)=ARL(θ(k);T(k)),T(k)=Agen(R(k)),R(k)=Adiag(πθ(k)),where Adiag, Agen, and ARL represent the diagnosis, generation, and RL-update operators, respectively, and R(k) is a structured diagnostic report.
The diagnostic mechanism initiates each iteration by performing explicit failure attribution and capability decomposition. It maps multimodal reasoning into a 12-dimensional capability space C={c1,c2,…,cK}, including categories such as geometry images, medical images, statistical charts, and natural scenes. From a diagnostic pool Ddiag, the system samples N=200 instances {(In,qn,an,cn)}n=1N, and the model generates responses y^n∼πθ(k)(⋅∣In,qn). Diagnostic agents score each response using a function v(⋅) that evaluates both reasoning steps and final results, producing a scalar correctness signal zn. For each category c, the system computes counts and accuracy:
Nc=n=1∑NI[cn=c],Accc=Nc1n=1∑NI[cn=c]⋅zn.Beyond accuracy, agents analyze the error set Ec={n∣cn=c, zn=0} to summarize recurring failure patterns Fc, such as OCR misalignments or chart legend mismatches. These patterns are injected into the generation phase as executable prompts. The system then derives a category proportion vector α(k) by assigning unnormalized weights α~c based on segmented accuracy ranges and normalizing:
αc(k)=∑c′=1Cα~c′α~c.The final diagnostic report R(k) includes α(k), {Fc(k)}, and {Hc(k)}, where Hc(k) provides actionable generation instructions such as enforcing stricter answer formats or longer reasoning chains.
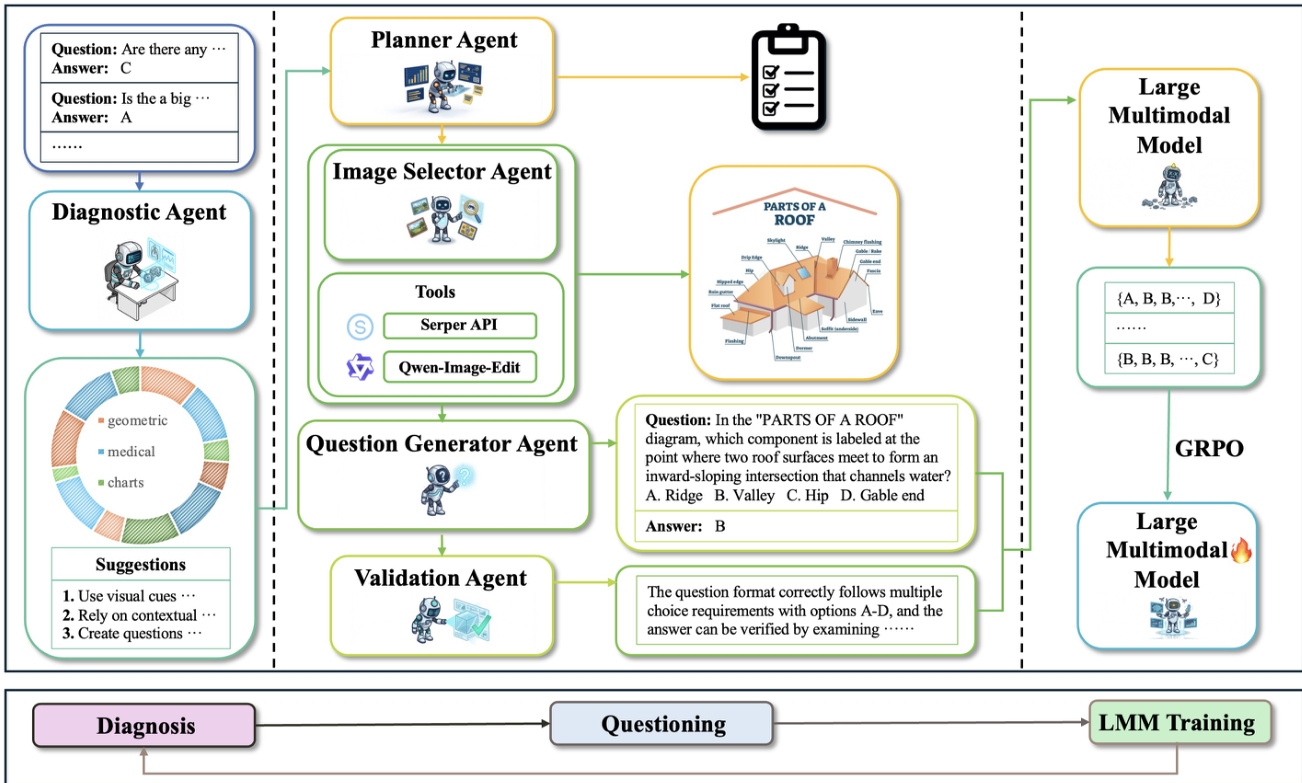
The Multiple Agents Questioner System translates R(k) into a training dataset T(k)={(Ij,qj,aj,cj)}j=1M with controllable distribution and verifiable answers. Given a target budget M, the system enforces a hard category quota constraint: for each category c, mc=⌊M⋅αc(k)⌋, and the final dataset must satisfy:
(I,q,a,c)∈T(k)∑I[c=c′]=mc′,∀c′∈{1,…,C}.The system comprises four agents: Planner, Image Selector, Question Generator, and Validation. The Planner Agent outputs a plan for each sample j:
planj=(cj, reqjI, reqjQ, dirj),where cj is the target category, reqjI specifies image requirements, reqjQ specifies question requirements, and dirj targets weaknesses derived from Fcj(k) and Hcj(k). The Image Selector Agent retrieves or composes images Ij from an external pool Pext using a pipeline ϕ(⋅) that includes search, filtering, and editing capabilities. The Question Generator Agent produces (qj,aj) given Ij and planning instructions:
(qj,aj)=ψ(Ij, reqiQ, Hci(k)).The Validation Agent gates sample quality using four checks: category consistency, solvability, answer verifiability, and format compliance. The final acceptance condition is:
g(si)=gcat⋅gsol⋅gver⋅gfmt.If g(sj)=1, the sample is added to T(k) and the quota state is updated; otherwise, it is discarded and regenerated.
Training proceeds via GRPO. For each prompt x, the old policy πθold generates G trajectories yi=(oi,1,…,oi,∣yi∣)∼πθold(⋅∣x). Each trajectory receives a scalar reward ri=r(x,yi). GRPO optimizes the clipped surrogate objective:
JGRPO(θ)=Ex∼D,{yi}∼πθold[G1∑i=1G∣yi∣1∑t=1∣yi∣min(ρi,tAi,t,clip(ρi,t,1−ε,1+ε)Ai,t)−βKL(πθ∥πinit)]where ρi,t=πθold(oi,t∣x,σi,<t)πθ(oi,t∣x,σi,<t), ε is the clipping threshold, β>0 controls KL regularization, and πinit is a reference policy. A key innovation is the group-normalized advantage:
A^i=std(r1,…,rG)ri−mean(r1,…,rG).From a maximum-entropy perspective, the optimal policy satisfies π∗(y∣x)∝πinit(y∣x)exp(r(x,y)/β), and the KL divergence admits a lower bound:
KL(πinit∥π∗)≥2β2p(x)(1−p(x)),where p(x) is the pass rate under πinit. This bound is maximized near p=0.5, explaining why DPE retains only moderately difficult samples to improve learning efficiency.
At iteration k, DPE generates and validates T(k), applies difficulty-aware filtering to obtain Ttrain(k), and performs GRPO to update the model: θ(k+1)=ARL(θ(k);Ttrain(k)). The system then repeats the diagnostic round, progressively strengthening weak capabilities and expanding visual coverage through external image sources.
Experiment
- DPE outperforms VisPlay in capability enhancement, training stability, and cross-model transferability, particularly excelling in STEM, OCR, and hallucination mitigation through a closed-loop diagnostic mechanism.
- DPE achieves state-of-the-art results with parameter efficiency, surpassing larger models like Qwen2.5-VL-72B and GPT-4o in complex visual math and grounding tasks, highlighting the value of data quality over scale.
- Ablation studies confirm DPE’s diagnostic module is essential for sustained improvement, preventing performance oscillation and guiding data generation toward true capability gaps.
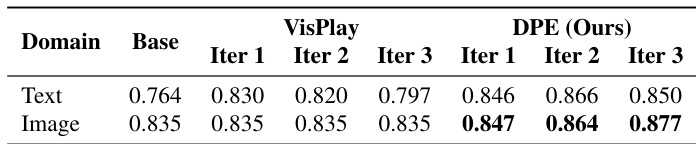
- DPE’s image retrieval and editing tools significantly expand visual diversity, preventing early plateaus and improving performance on OCR and math reasoning by covering long-tail visual patterns.
- Generated data from DPE shows higher and more stable text and image diversity across iterations, avoiding template collapse and maintaining broad semantic and visual coverage.
- Quality evaluations reveal DPE consistently produces high-quality, solvable, and visually grounded questions, while VisPlay’s output degrades over time, especially in correctness and structure.
- Case studies illustrate DPE’s ability to generate complete, well-structured, and semantically grounded questions, unlike VisPlay’s incomplete or unanswerable examples.
The authors use a diagnostic-guided data evolution framework to iteratively improve vision-language models under low-data conditions, achieving consistent gains across diverse benchmarks including STEM, OCR, and hallucination mitigation. Results show that their method sustains stable performance growth across iterations while outperforming self-evolving baselines and larger state-of-the-art models, particularly in complex reasoning and grounding tasks. The approach proves effective across model scales and relies on targeted data generation rather than volume, with diagnostic feedback ensuring continuous alignment with model weaknesses.
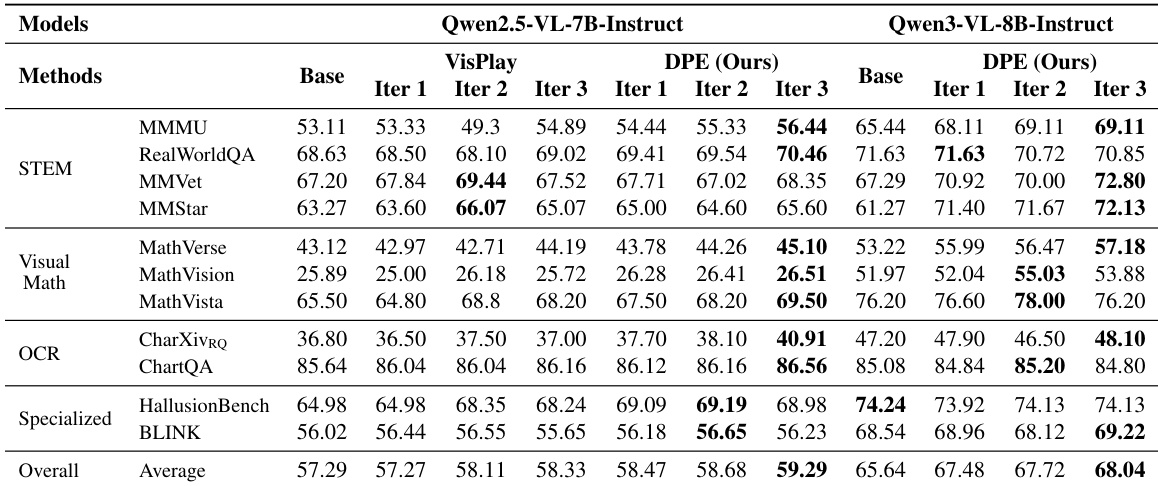
The authors use a multi-agent system to generate training data iteratively, with DPE consistently producing higher-quality questions than VisPlay across all iterations, particularly in solvability and correctness. Results show DPE maintains stable, near-ceiling quality scores while VisPlay’s quality degrades over time, indicating DPE’s diagnostic guidance effectively sustains data reliability. This quality advantage directly supports more stable and effective model evolution compared to self-evolving baselines.
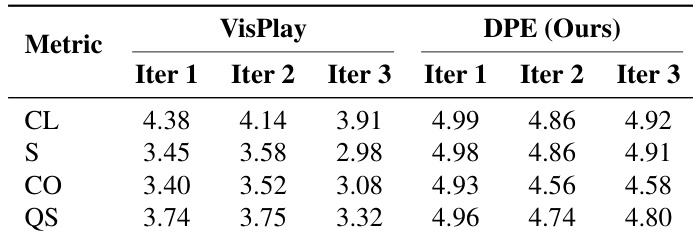
The authors use DPE to generate training data with higher and more stable text and image diversity compared to VisPlay, as measured by mean pairwise cosine distance across iterations. Results show DPE sustains diversity gains over time while VisPlay exhibits degradation, particularly in later iterations, indicating DPE’s mechanisms better prevent distribution collapse and template reversion. This enhanced diversity supports broader semantic and visual coverage, contributing to more robust model performance.
The authors use DPE to enhance Qwen3-VL-8B-Instruct under low-data conditions, achieving state-of-the-art performance across multiple benchmarks including visual math and hallucination mitigation. Results show DPE outperforms larger models like Qwen2.5-VL-72B and GPT-4o in key areas, demonstrating that targeted data generation and diagnostic feedback yield stronger gains than parameter scale alone. The method sustains stable improvements across iterations by focusing on model weaknesses and maintaining high data quality and diversity.
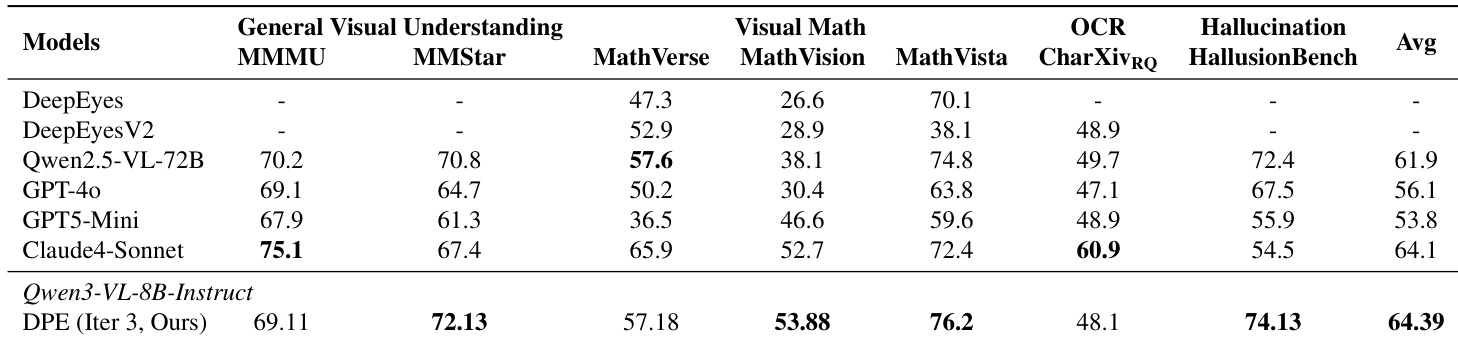
The authors use DPE to iteratively generate high-quality training data from a small seed set, achieving performance gains over static training despite using only 3K samples. Results show consistent improvements across multiple benchmarks, including MMMU, HallusionBench, MathVista, and RealWorldQA, indicating that targeted data generation based on diagnostic feedback enhances model capabilities more effectively than larger static datasets. The method demonstrates stable training dynamics and superior data efficiency, with gains sustained across iterations without performance regression.
