Command Palette
Search for a command to run...
OmniGAIA: Towards Native Omni-Modal AI Agents
OmniGAIA: Towards Native Omni-Modal AI Agents
Abstract
Human intelligence naturally intertwines omni-modal perception -- spanning vision, audio, and language -- with complex reasoning and tool usage to interact with the world. However, current multi-modal LLMs are primarily confined to bi-modal interactions (e.g., vision-language), lacking the unified cognitive capabilities required for general AI assistants. To bridge this gap, we introduce OmniGAIA, a comprehensive benchmark designed to evaluate omni-modal agents on tasks necessitating deep reasoning and multi-turn tool execution across video, audio, and image modalities. Constructed via a novel omni-modal event graph approach, OmniGAIA synthesizes complex, multi-hop queries derived from real-world data that require cross-modal reasoning and external tool integration. Furthermore, we propose OmniAtlas, a native omni-modal foundation agent under tool-integrated reasoning paradigm with active omni-modal perception. Trained on trajectories synthesized via a hindsight-guided tree exploration strategy and OmniDPO for fine-grained error correction, OmniAtlas effectively enhances the tool-use capabilities of existing open-source models. This work marks a step towards next-generation native omni-modal AI assistants for real-world scenarios.
One-sentence Summary
Researchers from Renmin University of China, Xiaohongshu Inc., and collaborators introduce OmniGAIA, a benchmark for native omni-modal agents requiring multi-hop reasoning and multi-turn tool use over video/audio and image/audio inputs, alongside OmniAtlas, a foundation agent with active perception and tool-integrated reasoning trained via hindsight-guided exploration and OmniDPO, significantly boosting open-source model performance on real-world agentic tasks.
Key Contributions
- OmniGAIA introduces the first benchmark for native omni-modal agents, requiring multi-hop reasoning and multi-turn tool use across video, image, and audio modalities, with 360 real-world tasks and open-form answers to evaluate true agentic capabilities beyond perception.
- The benchmark is built via a novel omni-modal event graph pipeline that mines, expands, and fuzzifies cross-modal signals from real data to synthesize challenging yet solvable tasks, enabling systematic evaluation of tool-integrated reasoning.
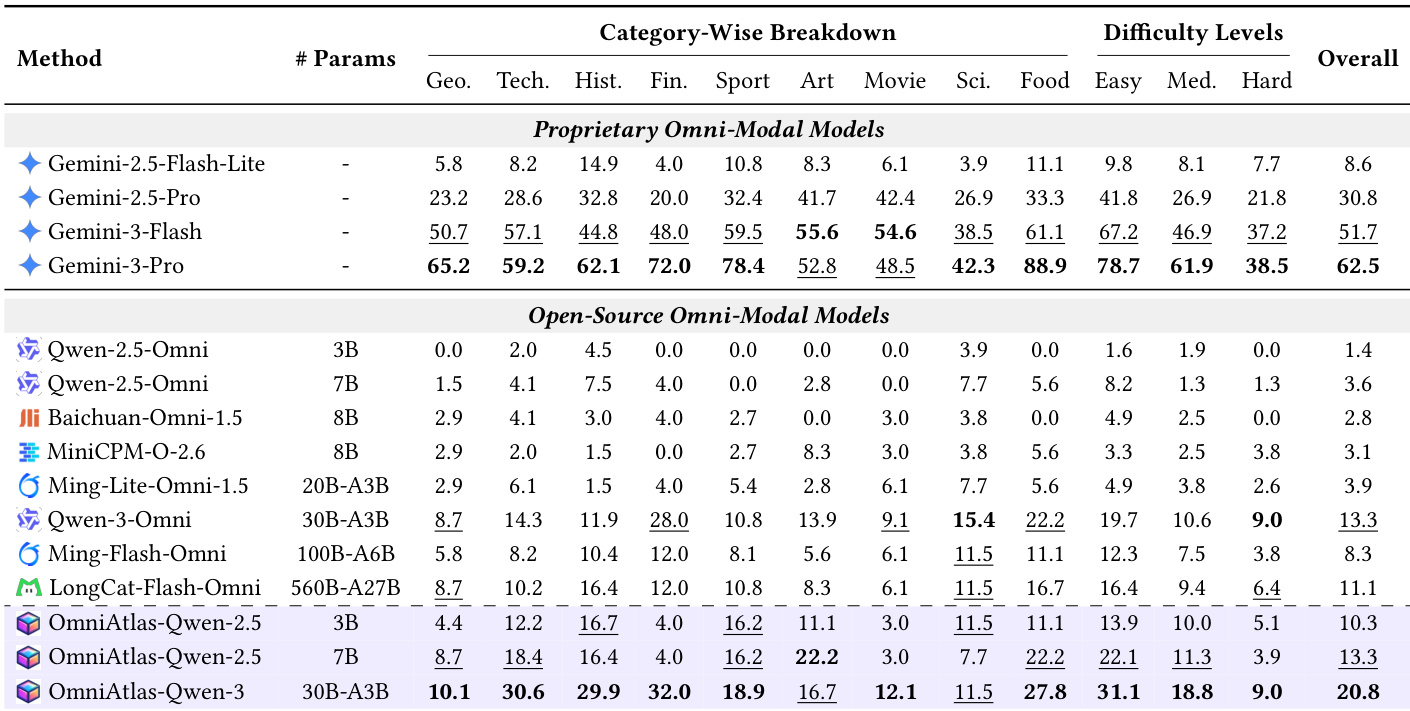
- OmniAtlas, a native omni-modal agent with active perception and tool-integrated reasoning, is trained via hindsight-guided trajectory synthesis and OmniDPO, improving open-source models like Qwen3-Omni from 13.3 to 20.8 Pass@1 on OmniGAIA.
Introduction
The authors leverage the growing capability of omni-modal foundation models to unify vision, audio, and language, but identify a critical gap: most existing systems focus on perception rather than agentic reasoning and tool use. Prior benchmarks are largely bi-modal and perception-centric, failing to evaluate multi-hop reasoning or multi-turn tool integration over real-world multimedia inputs. To address this, they introduce OmniGAIA—a benchmark with 360 tasks across video-with-audio and image+audio settings that demand cross-modal reasoning and verifiable tool use—and OmniAtlas, a native omni-modal agent trained with a novel trajectory synthesis and fine-tuning pipeline that significantly boosts open-source model performance on these complex tasks.
Dataset
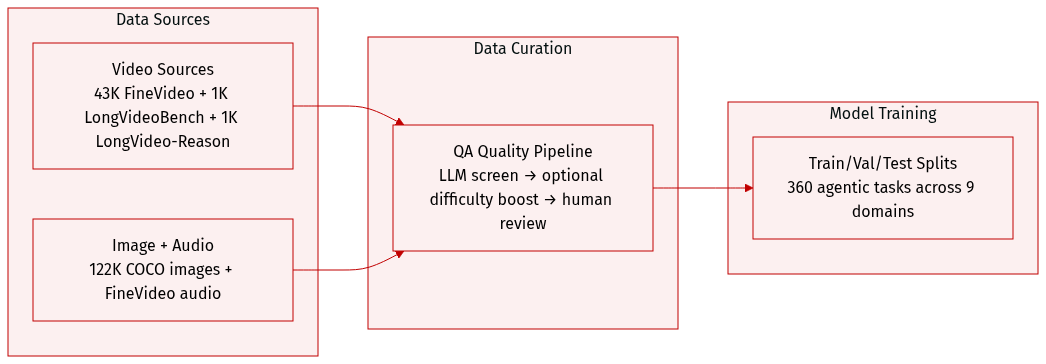
- The authors construct OmniGAIA to mirror real-world omni-modal interactions, combining two settings: video with audio, and image + audio pairs.
- For video data, they aggregate 43K clips from FineVideo (avg. 4 min), plus ~1K each from LongVideoBench and LongVideo-Reason (avg. 10 min) to test long-context reasoning.
- For image + audio, they pair COCO 2017’s 122K annotated images with audio tracks from FineVideo, creating diverse acoustic-visual scenes.
- Each QA pair undergoes a three-stage quality pipeline: LLM screening (using DeepSeek-V3.2 and Gemini-3-Pro) to filter for naturalness, omni-modal necessity, and answer uniqueness; optional difficulty expansion via added evidence or computation; and final human review by three CS grad students to validate correctness and solvability.
- OmniGAIA contains 360 agentic tasks across 9 domains, designed to stress long-horizon perception, multi-step reasoning, and tool use (mainly web search, occasionally code). Tasks require grounding in minutes-long media and often involve multi-hop planning.
Method
The authors leverage a multi-stage, agent-driven pipeline to construct complex, multi-hop omni-modal tasks. The framework begins with data collection from diverse video, audio, and image sources, followed by fine-grained information extraction, event graph construction, agentic expansion, and finally, QA generation via controlled fuzzification. Each stage is designed to progressively enrich the semantic and logical structure of the task, ensuring that generated questions demand cross-modal reasoning and tool use.
In the first stage, raw media inputs—spanning long videos, audio clips, and images—are processed to extract structured, time-aware signals. For videos, the authors split content into 60-second clips to preserve temporal granularity, generating both clip-level and full-video descriptions that capture scenes, events, and ambient sounds. Audio is analyzed via timestamped ASR, speaker diarization, and acoustic event detection, with global summaries and environmental tags (e.g., “stadium,” “indoor”) appended. Images undergo OCR, object and face recognition, and holistic captioning. These outputs are structured into JSON reports adhering to a “certainty-first” principle to minimize hallucination and support downstream graph construction.
Refer to the framework diagram, which illustrates how these extracted signals are structured into an initial event graph. The authors employ DeepSeek-V3.2 as a reasoning agent to build this graph, which explicitly encodes entities, events, and their cross-modal relations. The graph topology is designed to reflect real-world complexity—branching, cascading, and mixed structures—enabling the synthesis of logically consistent, multi-hop tasks. This graph serves as the backbone for the subsequent agentic expansion phase.
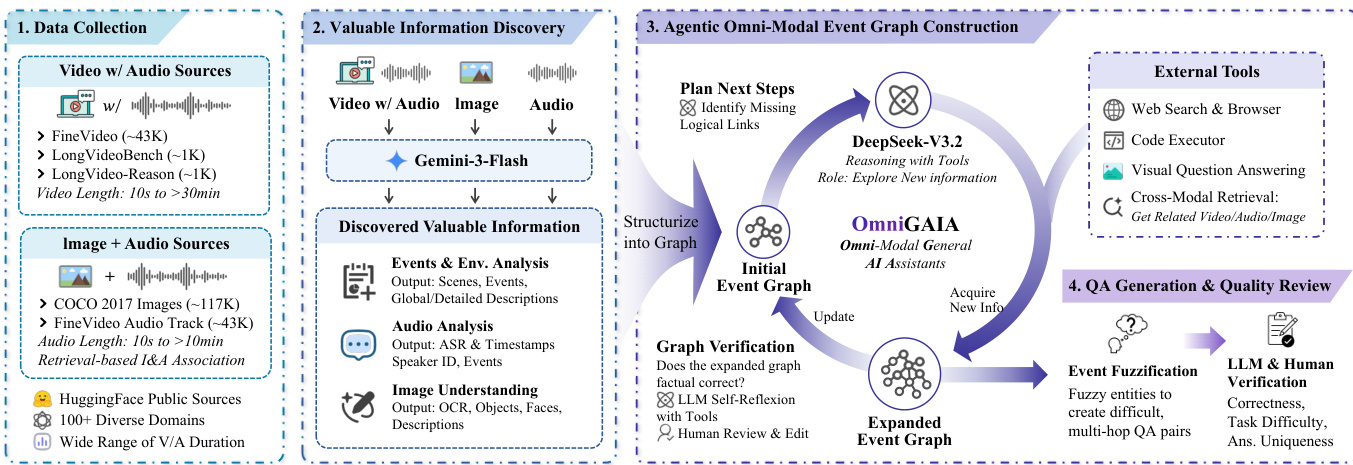
The agentic expansion phase introduces a tool-integrated reasoning paradigm. The DeepSeek-V3.2 agent, acting as an exploration agent, autonomously invokes a suite of external and cross-modal tools to discover missing evidence and expand the graph. These tools include web search and browsing for time-sensitive knowledge, code execution for numerical reasoning, visual question answering for external image analysis, and cross-modal retrieval to link related video, audio, or image content. The agent also supports active omni-modal perception, allowing it to request specific video segments, audio windows, or cropped image regions on demand—avoiding blanket downsampling and preserving fidelity for critical details.
Once the graph is expanded, the authors generate QA pairs via event fuzzification. Rather than querying graph nodes directly, they select nodes along long reasoning paths and apply fuzzy transformations—such as replacing specific entities with their types or masking key attributes. This forces models to traverse the full logical path and integrate multi-source, multi-modal evidence to derive a unique answer, thereby increasing task difficulty and reducing trivial fact lookup.
The training strategy for OmniAtlas is built on synthesized agent trajectories. The authors use Gemini-3-Flash to convert raw media into detailed textual annotations, then employ DeepSeek-V3.2 to generate tool-augmented solution trajectories via guided tree exploration. At each step, the agent samples multiple continuations, and a verifier prunes incorrect branches, retaining only successful trajectories for supervised fine-tuning. The training objective applies masked supervision, computing loss only on agent-generated tokens (reasoning and tool calls) while ignoring tool observations to prevent memorization of environment feedback.
As shown in the figure below, the authors further refine the model using OmniDPO, a fine-grained error correction method. For each failed trajectory, Gemini-3-Flash identifies the first erroneous step and generates a corrected prefix. This creates positive-negative preference pairs—denoted as τwin and τlose—which are used to optimize a masked DPO objective. This approach focuses correction on the specific module where the error occurred, whether in perception, reasoning, or tool use.
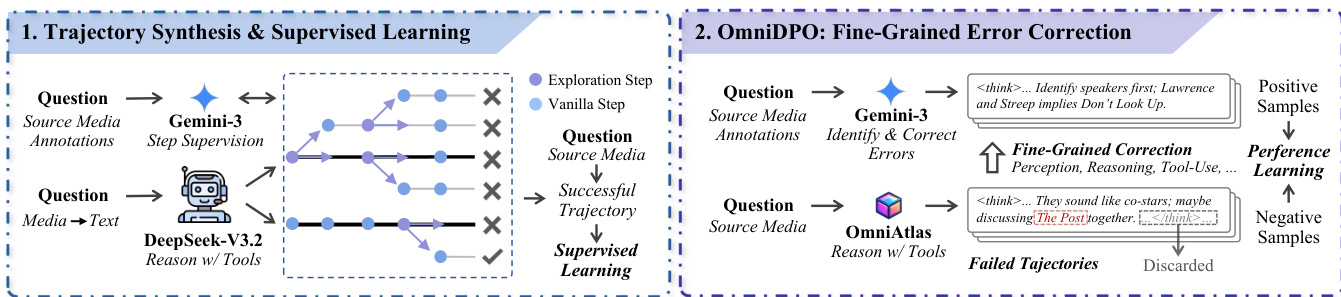
The agent’s behavior is governed by a formal trajectory definition: τ=[(st,at,ot)]t=0T, where st is the reasoning thought, at is the action (tool call or final response), and ot is the tool observation. Generation proceeds stepwise, pausing when a tool is invoked, appending the observation to the context, and resuming generation. This preserves intermediate reasoning states and supports coherent, long-horizon problem solving. The system prompt explicitly encourages “look-where-needed” behavior, enabling the agent to request specific media segments or regions only when necessary, which is critical for handling long videos and high-resolution images efficiently.
Experiment
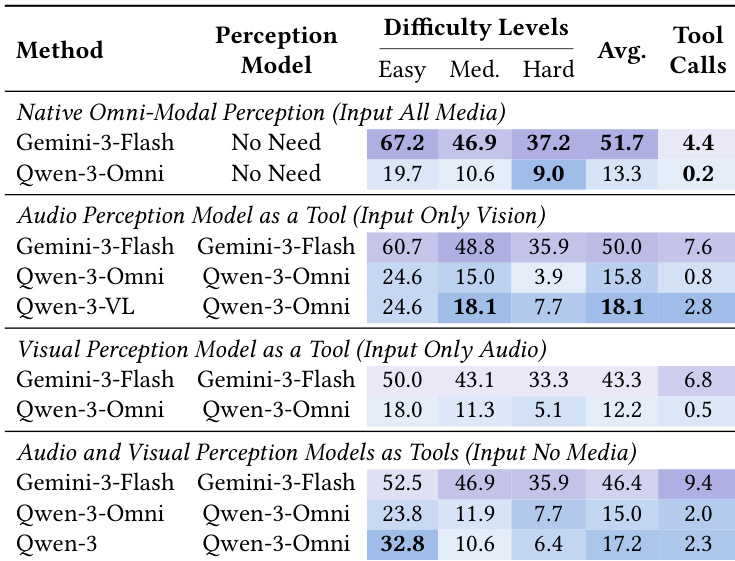
- OmniGAIA benchmark reveals a large performance gap between proprietary (Gemini-3-Pro) and open-source models, highlighting weaknesses in open-source omni-modal perception and tool-integrated reasoning.
- Scaling model size alone does not improve performance; agentic capabilities like tool-use policies are more critical than parameter count.
- OmniAtlas significantly boosts performance across model sizes, especially smaller ones, by improving tool usage and reasoning, though perception errors remain a persistent bottleneck.
- Hard tasks expose cascading failures: poor tool use leads to reasoning collapse, particularly in open-source models; even with OmniAtlas, multi-hop reasoning remains challenging.
- Tool usage is essential but not sufficient—successful agents avoid under-calling and query drift by grounding in location first, verifying facts, and computing only after validation.
- Native perception outperforms tool-based perception for strong agents, offering better accuracy and lower cost; tool-based perception can help weaker agents on easier tasks but harms performance on hard ones.
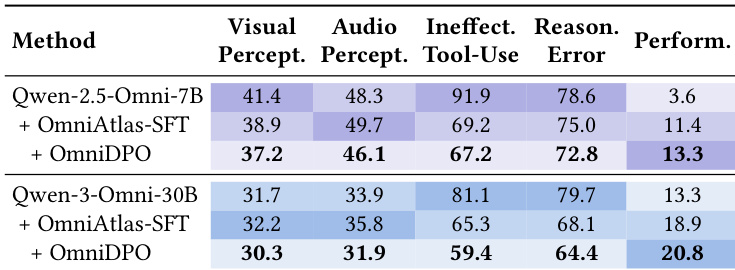
- OmniAtlas training (SFT + DPO) effectively reduces tool-use and reasoning errors, with SFT driving most gains and DPO providing further refinement.
- Case studies confirm that failure often stems from premature assumptions or confirmation bias in tool use, while success requires structured evidence acquisition and verification.
The authors evaluate a range of proprietary and open-source omni-modal models on a challenging benchmark, revealing a substantial performance gap between top proprietary systems like Gemini-3-Pro and the best open-source baselines. Their proposed OmniAtlas framework significantly improves open-source model performance across categories and difficulty levels, particularly on smaller models, by enhancing tool-use policies rather than relying on scale. Despite these gains, hard tasks requiring multi-hop reasoning remain difficult, and perception errors persist as a key bottleneck even after tool-use improvements.
The authors use OmniAtlas to fine-tune open-source omni-modal models, significantly reducing tool-use and reasoning errors while improving overall performance. Results show that combining supervised fine-tuning with direct preference optimization yields the strongest gains, particularly on smaller models. Despite these improvements, perception errors remain high, indicating that native multi-modal understanding is still a critical bottleneck.
The authors use fine-grained error analysis to reveal that ineffective tool usage and reasoning errors dominate failures across models, especially on hard tasks where open-source models show near-saturated tool misuse and cascading reasoning collapse. Proprietary models like Gemini-3-Pro demonstrate significantly lower error rates in perception and tool-use, highlighting their more mature planning capabilities, while OmniAtlas improves tool policy but leaves visual and audio perception as a persistent bottleneck. Results show that even with enhanced tool engagement, fundamental perception limitations remain a key barrier to solving complex multi-hop tasks.
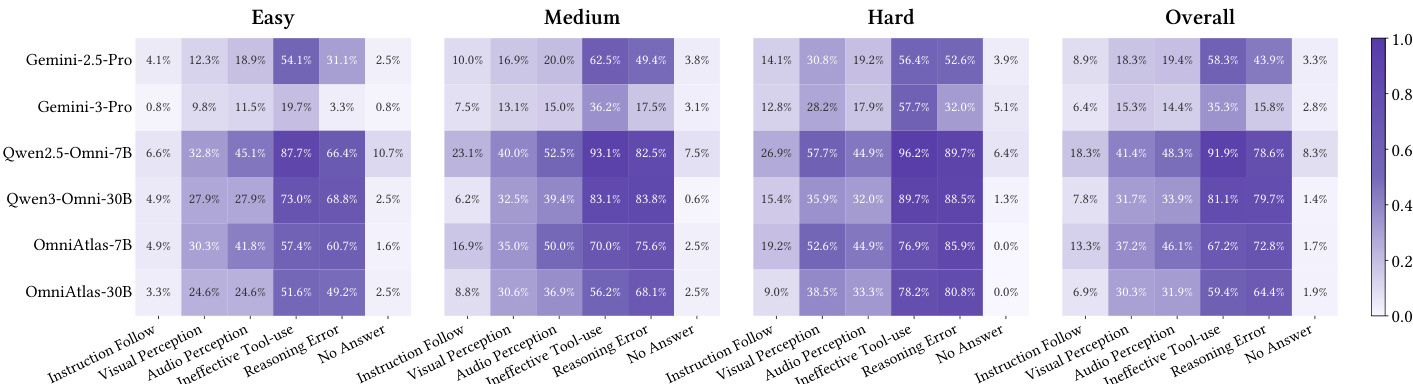
The authors compare native omni-modal perception against using perception models as external tools, finding that native perception delivers superior performance and efficiency for capable models like Gemini-3-Flash, while tool-based perception offers limited gains for weaker models and consistently increases tool call costs. For Qwen-3-Omni, substituting native perception with tools improves performance on easier tasks but degrades results on hard tasks, indicating that tools cannot compensate for the lack of integrated cross-modal reasoning. Results confirm that native perception should be the default for strong agents, with tool-based perception serving as a fallback for weaker systems or missing modalities.