Command Palette
Search for a command to run...
The Trinity of Consistency as a Defining Principle for General World Models
The Trinity of Consistency as a Defining Principle for General World Models
Abstract
The construction of World Models capable of learning, simulating, and reasoning about objective physical laws constitutes a foundational challenge in the pursuit of Artificial General Intelligence. Recent advancements represented by video generation models like Sora have demonstrated the potential of data-driven scaling laws to approximate physical dynamics, while the emerging Unified Multimodal Model (UMM) offers a promising architectural paradigm for integrating perception, language, and reasoning. Despite these advances, the field still lacks a principled theoretical framework that defines the essential properties requisite for a General World Model. In this paper, we propose that a World Model must be grounded in the Trinity of Consistency: Modal Consistency as the semantic interface, Spatial Consistency as the geometric basis, and Temporal Consistency as the causal engine. Through this tripartite lens, we systematically review the evolution of multimodal learning, revealing a trajectory from loosely coupled specialized modules toward unified architectures that enable the synergistic emergence of internal world simulators. To complement this conceptual framework, we introduce CoW-Bench, a benchmark centered on multi-frame reasoning and generation scenarios. CoW-Bench evaluates both video generation models and UMMs under a unified evaluation protocol. Our work establishes a principled pathway toward general world models, clarifying both the limitations of current systems and the architectural requirements for future progress.
One-sentence Summary
Researchers from Shanghai AI Lab, UCAS, Westlake University, NUS, SJTU, Zhejiang University, and China University of Petroleum propose that general world models must satisfy a "Trinity of Consistency"—Modal, Spatial, and Temporal—to simulate physical laws, introducing CoW-Bench to evaluate models on multi-frame reasoning and constraint satisfaction, revealing current systems’ reliance on pixel statistics over causal understanding.
Key Contributions
- We introduce the "Trinity of Consistency" — Modal, Spatial, and Temporal Consistency — as a foundational theoretical framework defining the essential properties required for General World Models to simulate physical reality, addressing the lack of principled guidance in current multimodal systems.
- We analyze the architectural evolution of world models through this tripartite lens, showing how unified architectures increasingly integrate perception, language, and reasoning to enable emergent world simulation, moving beyond isolated modules toward synergistic, physics-aware systems.
- We propose CoW-Bench, a new benchmark evaluating multi-frame reasoning and generation across video models and UMMs, providing unified metrics to assess single- and cross-axis consistency, revealing current limitations and guiding future progress toward general world simulators.
Introduction
The authors leverage the Trinity of Consistency—Modal, Spatial, and Temporal—as a unifying theoretical framework to define what constitutes a true General World Model. While recent video generators like Sora and Unified Multimodal Models (UMMs) show impressive scaling and integration, they often mimic visual plausibility without internalizing physical laws, suffering from structural hallucinations, temporal drift, and causal violations. Prior work lacks a principled definition of world modeling and relies on fragmented, single-axis benchmarks that fail to test cross-dimensional coherence. The authors’ main contribution is twofold: first, they formalize the Trinity as the necessary triad for physical simulation—semantic alignment, geometric grounding, and causal evolution—and trace how current models are converging toward this unified paradigm; second, they introduce CoW-Bench, a novel evaluation suite that tests models across 18 sub-tasks derived from the Trinity, enforcing constraint satisfaction over multi-frame, long-horizon, and intervention-driven scenarios to distinguish true simulation from visual mimicry.
Dataset

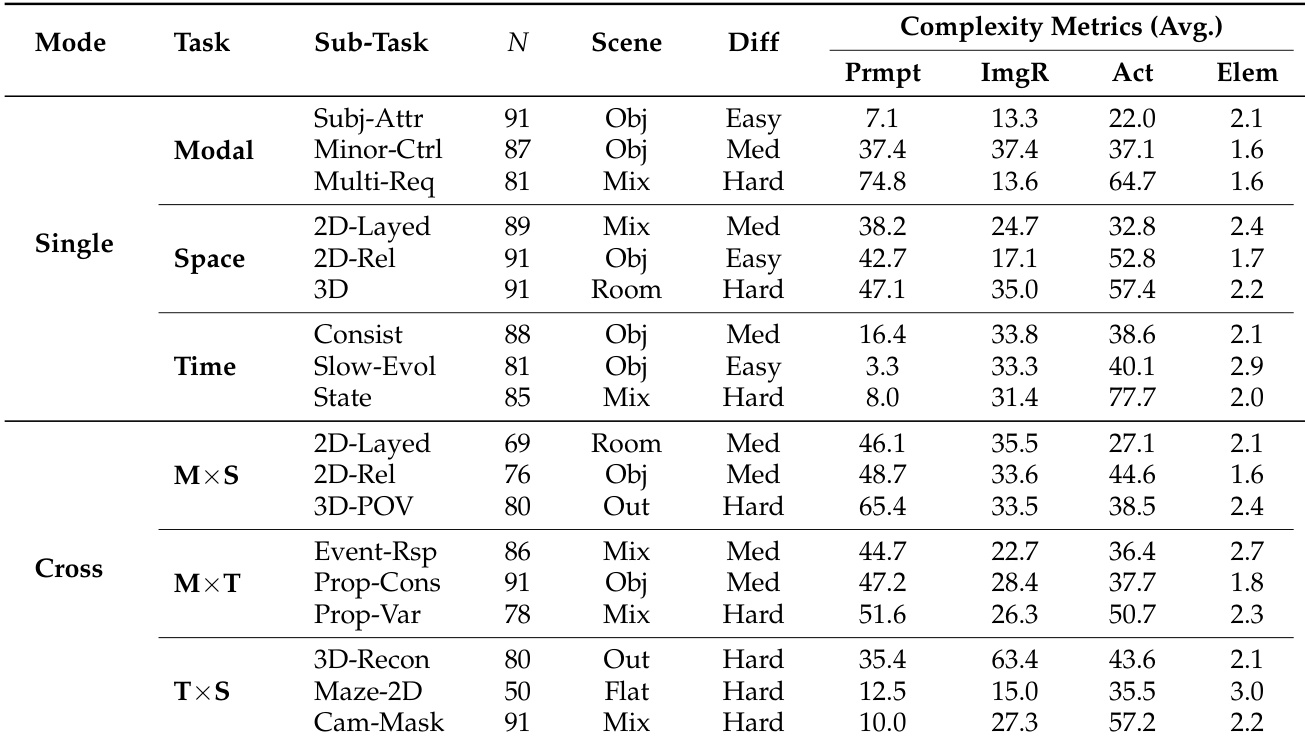
- The authors use CoW-Bench, a rigorously balanced benchmark of 1,485 manually constructed samples, organized into a two-level hierarchy: Modal Level (Single vs. Cross) and Task Level (Modal, Spatial, Temporal dimensions and their intersections).
- The dataset spans 18 fine-grained sub-tasks, each containing 69–91 samples (including 50 hard Maze cases), ensuring uniform distribution to prevent evaluation bias from long-tail task frequencies.
- Task complexity varies across three dimensions: (1) Instruction span (7.1–74.8 words), testing language understanding from atomic to multi-constraint commands; (2) Visual load (avg. 2.1 elements for cross-modal vs. 1.6 for single-modal tasks); and (3) Dynamic evolution (e.g., Time-State tasks average 77.7 action words), capturing intricate temporal changes.
- All samples underwent human-machine collaborative auditing to correct metric biases and verify semantic alignment, establishing CoW-Bench as a reproducible gold standard.
- The benchmark evaluates models against six core consistency challenges using frame-by-frame Physical State Ground Truth, distinguishing “Generators” from true “World Simulators” by testing multi-dimensional constraint handling.
Method
The authors leverage a multi-stage architectural evolution to address the core challenge of modal consistency: aligning heterogeneous modalities (text, image, video, audio) into a unified, physically complete latent space. This process is conceptualized as solving a high-dimensional heterogeneous manifold alignment problem, where the model must overcome entropy disparity and topological mismatch. The framework is built upon two theoretical assumptions—the Platonic Representation Hypothesis and the Hypersphere Geometry Hypothesis—which guide the transition from direct feed-forward mapping to iterative reasoning and planning.
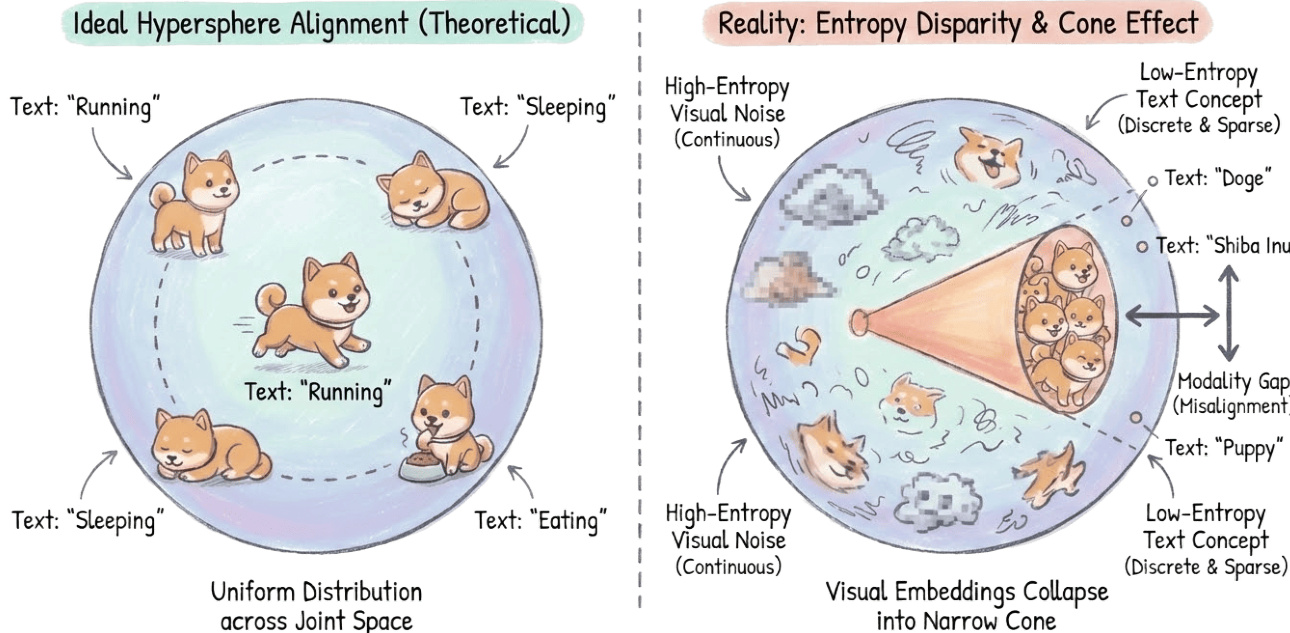
As shown in the framework diagram, the overall architecture is organized around three core consistency pillars: Modal, Spatial, and Temporal. Modal consistency, depicted on the left, involves projecting diverse inputs like text descriptions, images, and audio into a shared latent representation. This is contrasted with the ideal theoretical state of uniform hypersphere alignment, where text and visual concepts are evenly distributed. In reality, as illustrated in the figure below, a significant modality gap exists: high-entropy, continuous visual embeddings collapse into a narrow cone, while low-entropy, discrete text concepts remain sparse, leading to misalignment.
To systematically deconstruct this alignment, the authors trace the evolution of multimodal architectures through distinct paradigms. The journey begins with geometric isolation, exemplified by Dual-Tower architectures like CLIP and ALIGN, which use contrastive learning to project modalities onto a shared hypersphere but lack deep, fine-grained interaction. This is followed by the Connector-Based Alignment paradigm, represented by Flamingo and BLIP-2, which freeze a pre-trained visual encoder and introduce lightweight, learnable bridge modules (like Q-Former or Perceiver Resampler) to align visual features with the semantic space of large language models (LLMs). This design reduces training costs and establishes a standard template for subsequent LMMs.
The next stage involves Early Fusion and Unified Optimization, where models like Unified-IO attempt to handle all tasks within a single sequence-to-sequence framework. However, this approach exposes deep optimization instability due to significant differences in training dynamics between modalities, particularly the higher gradient variance of visual tokens compared to text. A key limitation of this stage is the Asymmetric Projection, as seen in LLaVA, where a linear projection layer acts as a low-rank compressor. This prioritizes semantic alignment with the LLM while discarding high-frequency visual textures essential for generation, explaining why such models excel in understanding but fail in detailed generation.
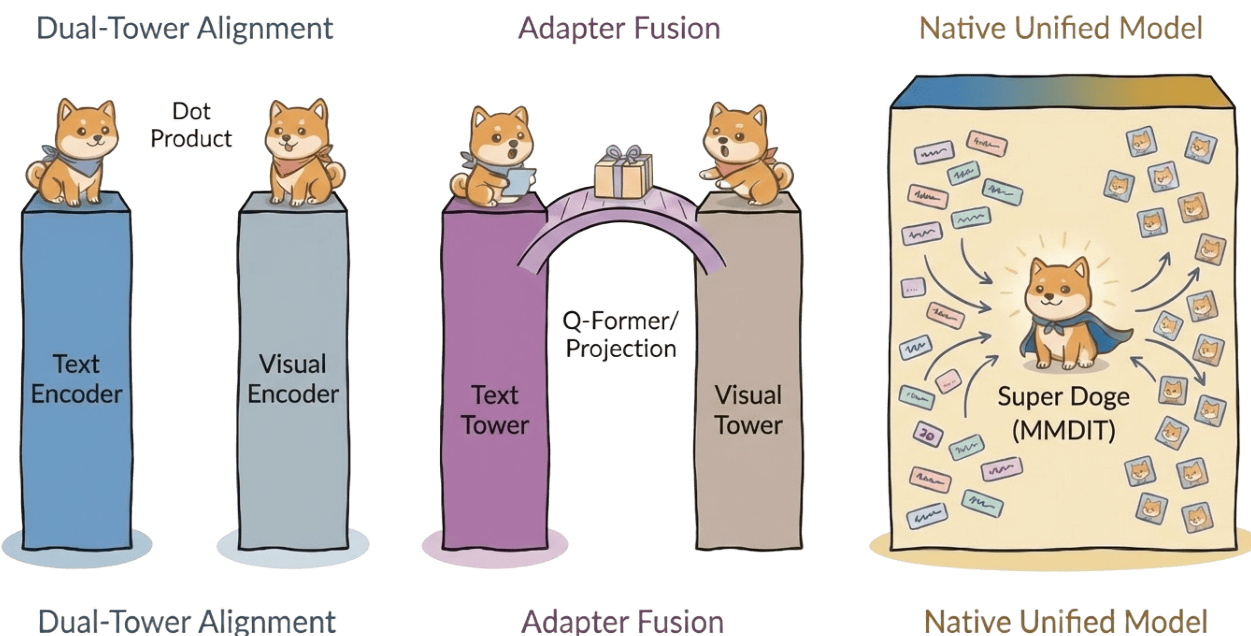
The current mainstream paradigm is Orthogonal Decoupling, as implemented in architectures like Stable Diffusion 3.5 and Emu3. The core innovation here is weight decoupling: maintaining independent weight sets for text and image modalities (Wtxt,Wimg) and exchanging data only during attention operations. This design forces the Hessian matrix of the joint loss function to exhibit an approximate block-diagonal structure, effectively isolating modality-specific curvature and causing gradient updates for different modalities to tend towards orthogonality in the parameter space. This significantly reduces gradient conflict, enabling superior instruction following and physical fidelity.
Finally, the framework incorporates Intent Alignment via Reinforcement Learning (RL) to shift the focus from physical representation fitting to high-level semantic alignment. After achieving orthogonal decoupling, the authors introduce RLHF to reframe alignment as a reward-guided search on the hypersphere manifold. This involves using preference fine-tuning, such as SPO and VisualPRM, for stepwise evaluation, and incorporating physics-aware feedback via PhyGDPO to penalize non-physical phenomena. The architecture also establishes a Perception-Generation Synergistic Loop, utilizing VLMs as judges to create a Generate-Evaluate-Refine closed-loop system, enabling iterative fine-tuning and bootstrapping towards the semantic understanding upper bound of VLMs without external human annotation.
Experiment
- New metrics like VCD and CoW-Bench shift evaluation from perceptual quality to constraint satisfaction, detecting temporal flicker, spatial penetration, and semantic drift invisible to traditional scores like FVD.
- Temporal consistency now requires physical causality and rule-following evolution, not just smooth motion; models like Veo 3 show emergent reasoning but still fail on structured stage transitions and attribute dynamics.
- Spatial evaluation emphasizes topological logic and physics-based verification; models handle single-view 3D well but struggle with cross-view anchoring, occlusion updates, and directional grounding.
- Modal consistency reveals widespread “constraint backoff” — models relax rare instructions into defaults — and fail to bind attributes to correct entities despite plausible visuals.
- Compound tasks expose core world-model gaps: video generators produce fluid motion but lack persistent world states, while image models better maintain constraints but lack temporal continuity.
- CoW-Bench’s atomic decomposition enables diagnostic scoring, revealing that top models excel in local plausibility but collapse under multi-step, multi-dimensional consistency demands.
- The key bottleneck across modalities is not visual fidelity but semantic grounding, temporal programming, and maintaining invariant world states under transformation — traits essential for true world modeling.
The authors use a cross-generational evaluation to show that models incorporating world model priors, such as Google Veo 3, achieve superior temporal consistency and physics compliance while maintaining minimal high-frequency artifacts, as measured by VCD. Results show that these models also demonstrate strong causal reasoning capabilities, with task success rates exceeding 70%, indicating a shift from perceptual smoothness to physically grounded, rule-following generation. Earlier paradigms, in contrast, exhibit higher frequency instability and weaker adherence to physical laws, even when producing visually coherent outputs.

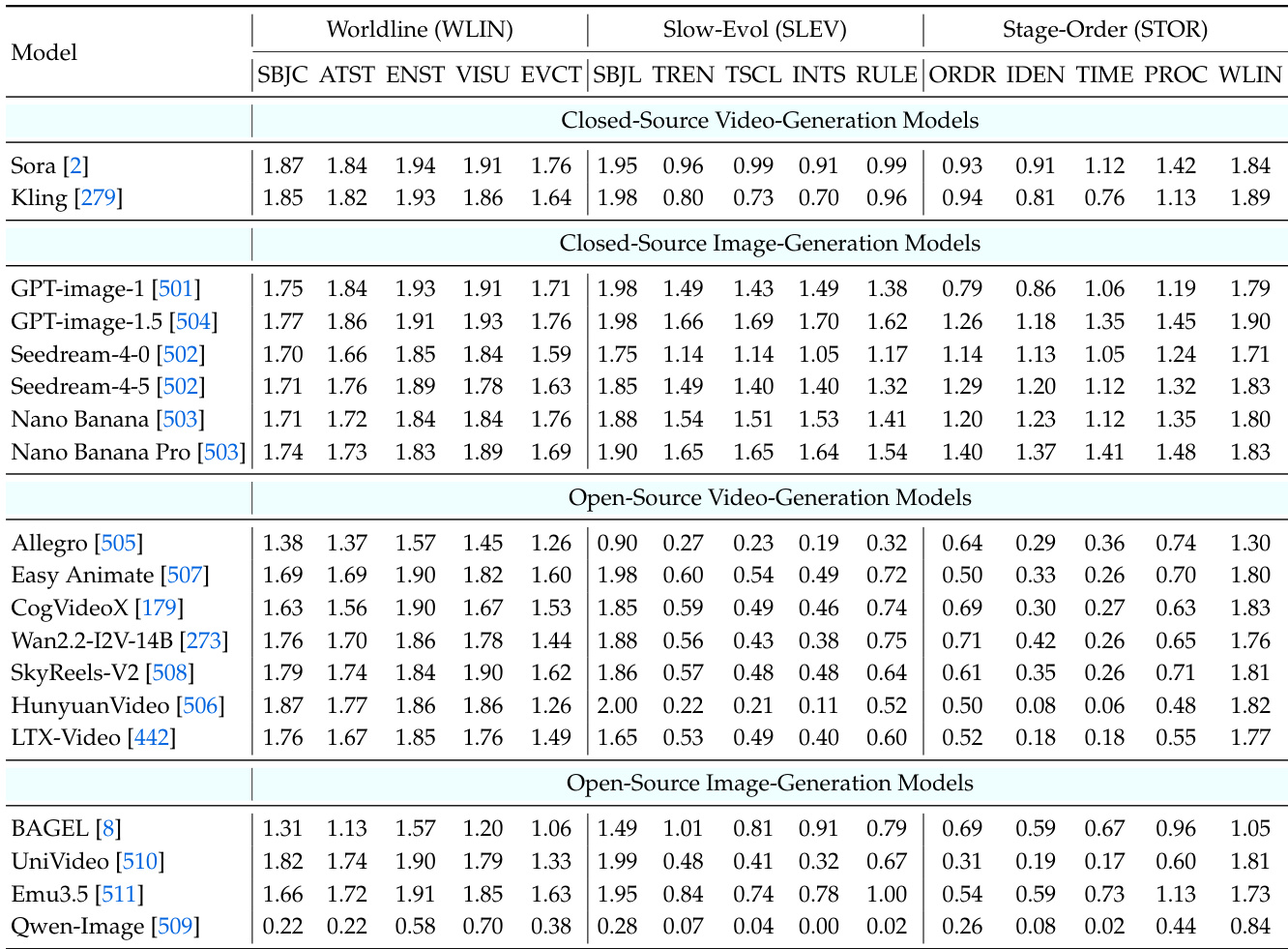
The authors use CoW-Bench to evaluate temporal consistency across models, revealing that while video generators excel at maintaining visual continuity (Worldline), they struggle with rule-guided evolution and stage-ordered transitions. Image models, particularly closed-source ones, show stronger adherence to temporal constraints and structured progression, indicating that current video models prioritize smooth motion over causal, instruction-following dynamics. Results show a clear performance gap between closed-source and open-source models, with the latter often failing to maintain consistent state evolution or execute discrete temporal logic.
The authors use CoW-Bench to evaluate world models across modal, temporal, and spatial consistency, revealing that even visually plausible outputs often fail to satisfy explicit constraints like directional grounding, attribute binding, or causal event timing. Results show that top closed-source image models outperform video generators in maintaining stable referents and executing rule-based dynamics, while open-source video models frequently collapse under compound tasks requiring persistent world-state maintenance. This highlights a fundamental gap: current video models rely on pixel interpolation rather than physical reasoning, leading to failures in cross-consistency scenarios that demand long-horizon constraint satisfaction.
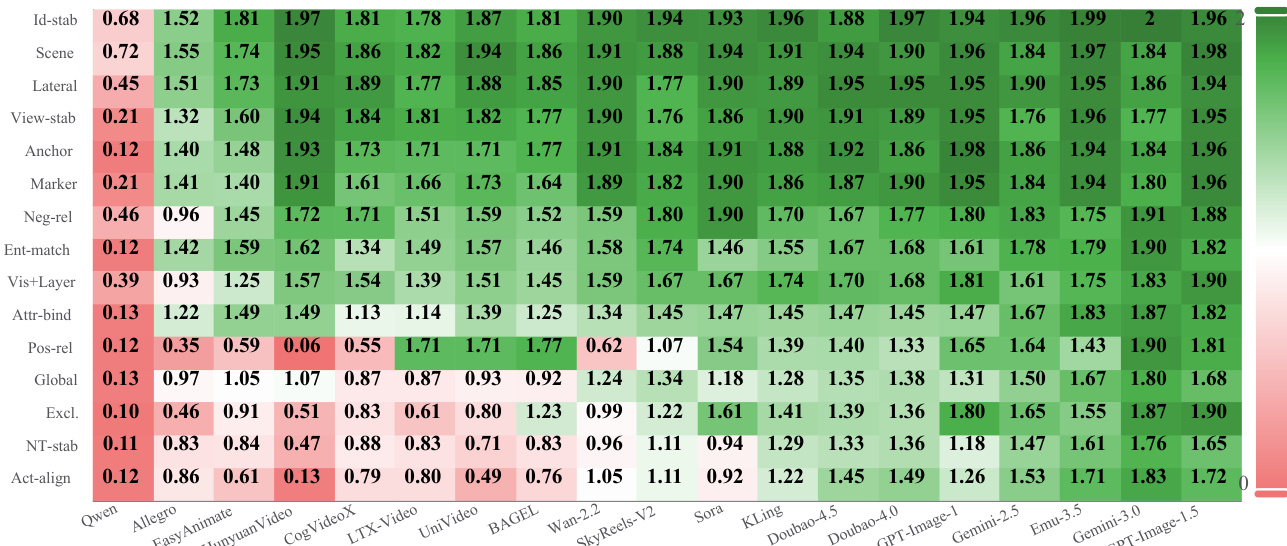
The authors use CoW-Bench to evaluate world models across single and compound consistency tasks, revealing that while models perform well on isolated modal, spatial, or temporal constraints, they struggle significantly when multiple dimensions must be maintained simultaneously. Results show that cross-consistency tasks—especially those requiring synchronized modal-spatial-temporal reasoning—expose fundamental gaps in maintaining stable world states under dynamic evolution, indicating current models rely more on perceptual interpolation than genuine physical or causal reasoning.
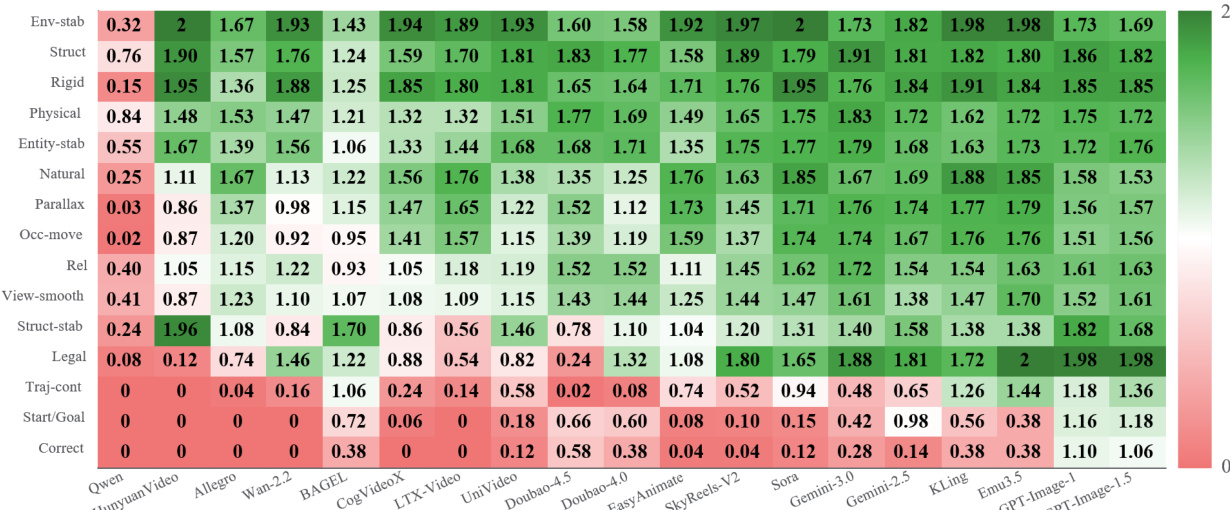
The authors use CoW-Bench to evaluate world models across time-space consistency tasks, revealing that while many models generate visually smooth motion, they frequently fail to maintain a persistent spatial structure or execute goal-directed trajectories. Results show that top-performing models like GPT-Image-1.5 achieve high scores on structural and environmental stability, but most video generators struggle with core navigation tasks such as correctly reaching a goal or preserving trajectory continuity. This indicates that current video models prioritize perceptual smoothness over maintaining a coherent, physics-grounded world state during dynamic sequences.