Command Palette
Search for a command to run...
CiteAudit: You Cited It, But Did You Read It? A Benchmark for Verifying Scientific References in the LLM Era
CiteAudit: You Cited It, But Did You Read It? A Benchmark for Verifying Scientific References in the LLM Era
Zhengqing Yuan Kaiwen Shi Zheyuan Zhang Lichao Sun Nitesh V. Chawla Yanfang Ye
Abstract
Scientific research relies on accurate citation for attribution and integrity, yet large language models (LLMs) introduce a new risk: fabricated references that appear plausible but correspond to no real publications. Such hallucinated citations have already been observed in submissions and accepted papers at major machine learning venues, exposing vulnerabilities in peer review. Meanwhile, rapidly growing reference lists make manual verification impractical, and existing automated tools remain fragile to noisy and heterogeneous citation formats and lack standardized evaluation. We present the first comprehensive benchmark and detection framework for hallucinated citations in scientific writing. Our multi-agent verification pipeline decomposes citation checking into claim extraction, evidence retrieval, passage matching, reasoning, and calibrated judgment to assess whether a cited source truly supports its claim. We construct a large-scale human-validated dataset across domains and define unified metrics for citation faithfulness and evidence alignment. Experiments with state-of-the-art LLMs reveal substantial citation errors and show that our framework significantly outperforms prior methods in both accuracy and interpretability. This work provides the first scalable infrastructure for auditing citations in the LLM era and practical tools to improve the trustworthiness of scientific references.
One-sentence Summary
Researchers from Notre Dame and Lehigh introduce APM, a multi-agent framework detecting hallucinated citations via staged verification, outperforming baselines with interpretable, scalable auditing for LLM-generated scientific texts, addressing integrity risks in peer review and scholarly publishing.
Key Contributions
- We introduce the first large-scale, human-validated benchmark for detecting hallucinated citations, covering diverse domains and citation types with standardized evaluation protocols to enable reproducible research on citation faithfulness.
- We propose a multi-agent verification framework that decomposes citation checking into coordinated stages—claim extraction, evidence retrieval, passage matching, contextual reasoning, and calibrated judgment—to handle noisy, real-world citation formats robustly.
- Experiments on state-of-the-art LLMs reveal widespread citation errors, and our framework significantly outperforms existing baselines in both detection accuracy and interpretability, offering scalable tools for reviewers and publishers.
Introduction
The authors leverage the rise of large language models in scientific writing to address a growing threat: hallucinated citations—plausible but nonexistent references that undermine research integrity. Prior automated tools struggle with real-world citation noise and lack standardized benchmarks, while manual verification is no longer feasible at scale. Their main contribution is a multi-agent verification framework that breaks citation checking into specialized stages—claim extraction, evidence retrieval, matching, reasoning, and judgment—paired with the first large-scale, human-validated benchmark spanning diverse citation types and domains. This system outperforms existing baselines in accuracy and interpretability, offering a practical, scalable infrastructure for researchers and publishers to audit citations and restore trust in scholarly references.
Dataset

The authors use CiteAudit, a benchmark for citation hallucination detection, composed of two main components: real-world citations and human-synthesized hallucinated citations. Here’s how the dataset is built and used:
-
Sources and Composition:
- Real citations are drawn from OpenReview and Google Scholar, manually verified against authoritative records (title, authors, venue, year, DOI).
- Hallucinated citations are generated from verified BibTeX entries using controlled perturbations guided by a taxonomy of hallucination types (title, author, metadata errors).
-
Key Subset Details:
- Real-world set: High-quality, naturally occurring errors (e.g., wrong authors, venues, nonexistent papers), manually verified but limited in scale due to labor intensity.
- Generated set (2,500 instances):
- Title Errors (1,000): Generated via keyword substitution, paraphrasing, or GPT-4o-mini topic-conditioned synthesis.
- Author Errors (1,000): Via adding/deleting authors, name swaps, or full fabrication.
- Metadata Errors (500): Venue mismatches, year shifts, or fake DOIs.
- Compound hallucinations (multiple field errors) are always labeled as hallucinated.
-
Processing and Annotation:
- All citations undergo automated web retrieval followed by manual cross-checking by the author team.
- Labeling is strict: only core metadata (title, authors, venue, year, DOI) must match authoritative sources; minor formatting issues are ignored.
- Each citation is reviewed by at least two authors; unresolved cases are excluded. A random subset is audited for consistency.
-
Dataset Use in Evaluation:
- The generated test set (5,000 total: 2,500 real + 2,500 hallucinated) is balanced across error types to enable fair, fine-grained model evaluation.
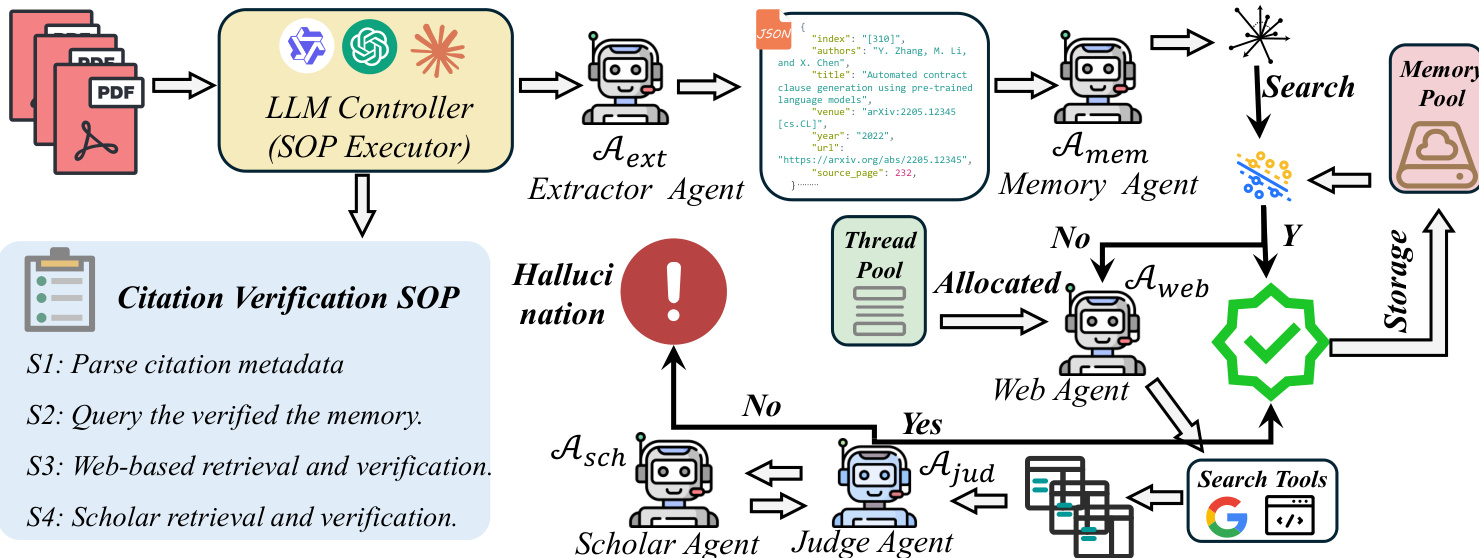
- Generated hallucinations are validated to match real-world error distributions (chi-square test: p ≈ 0.97).
- No automated or crowd-sourced labeling is used — all annotations are author-verified for high confidence.
This design supports reproducible, controlled evaluation of citation verification systems under both naturally occurring and systematically perturbed hallucination scenarios.
Method
The authors leverage a decentralized multi-agent framework governed by a hierarchical Standardized Operating Procedure (SOP) to systematically audit scholarly citations for existence and metadata integrity. The system treats citation verification as a multi-stage evidence validation problem, where each citation ri is evaluated against a strict consistency criterion Sc defined over its structured metadata tuple Mi={mT,mA,mU,mV}, representing title, authors, URL, and venue. A citation is classified as Fake if no corresponding entry exists in the global scholarly graph Gscholar or if Sc=0, where Sc is computed as the product of indicator functions over exact character-level matches between extracted and ground-truth fields:
Sc=k∈{T,A,U,V}∏I(mk=m^k)The framework is orchestrated by an LLM Controller acting as the SOP Executor, which decomposes the verification task into a sequential and parallelizable graph based on predefined stages (S1–S4). The pipeline begins with the Extractor Agent (Aext), which ingests raw PDFs using vision-integrated OCR tools and maps unstructured citation strings into immutable JSON metadata, preserving the original authorial intent without semantic distortion. This structured output serves as the substrate for all downstream verification.
Refer to the framework diagram for a visual representation of the agent interactions and decision flow. The Memory Agent (Amem) then performs a high-speed semantic lookup against a dual-end knowledge base K, computing a confidence score smem via cosine similarity between embeddings of the citation and stored records:
smem(Mi)=k∈Kmax(∣∣Enc(Mi)∣∣⋅∣∣Enc(k)∣∣Enc(Mi)⋅Enc(k))If smem>τ (with τ=0.92), the citation is immediately verified via the “fast-path” and stored in the Memory Pool for future reuse. Otherwise, the task is allocated to the Web Search Agent (Aweb), which interfaces with the Google Search API to retrieve and deep-crawl the full content of the top five results, ensuring evidence is grounded in actual textual data rather than snippets.
The Judge Agent (Ajud) then evaluates the alignment between the extracted metadata Mi and the retrieved evidence E using the strict verification function:
Fjudge(Mi,E)=f∈{T,A,U,V}∏I(ExactMatch(Mif,E))A successful match triggers storage in the Memory Pool; a mismatch escalates the citation to the Scholar Agent (Asch), which performs low-frequency, high-precision crawling of authoritative repositories (e.g., Google Scholar) to retrieve the canonical ground-truth record M^i. The Judge Agent performs a final character-level alignment against this record. If this definitive check fails, the citation is flagged as Hallucinated with a provenance report; otherwise, it is verified and stored.
The entire pipeline is implemented using the Qwen3-VL-235B A22 model deployed via vLLM, with agents instantiated for specific roles: the Planning Model for task routing, Aext for OCR and schema mapping, Amem based on the Mem0 framework for persistent knowledge retention, Aweb for deep web crawling, Ajud for strict matching, and Asch for authoritative retrieval. The system operates on a multi-thread pool (size=4) with deterministic inference (temperature=0.0) and employs a structured prompt-based SOP to ensure reproducible, auditable decision-making. Role separation between the Planning Agent (task routing only) and Judge Agent (strict matching only) enforces determinism and prevents heuristic conflation.
Experiment
- Our model excels in detecting hallucinated citations without falsely rejecting real ones, outperforming existing systems by enforcing strict authenticity over permissive plausibility.
- On real-world benchmarks, it achieves the highest accuracy, precision, recall, and F1 score, significantly surpassing alternatives and proving robust under noisy, ambiguous conditions.
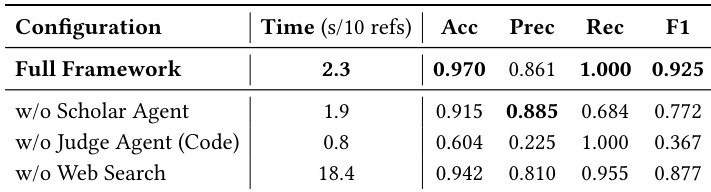
- Ablation studies confirm critical roles: the Scholar Agent acts as a final safety net for authoritative validation, the LLM Judge enables semantic resilience against formatting noise, and the Web Search Agent ensures efficiency via fast-path filtering.
- Proprietary LLMs underperform due to opaque, unreliable retrieval behavior, highlighting the need for transparent, evidence-grounded verification tools.
- Case studies demonstrate fine-grained detection of metadata mismatches (e.g., title, author), offering interpretable, structured verification beyond binary classification, crucial for scholarly integrity.
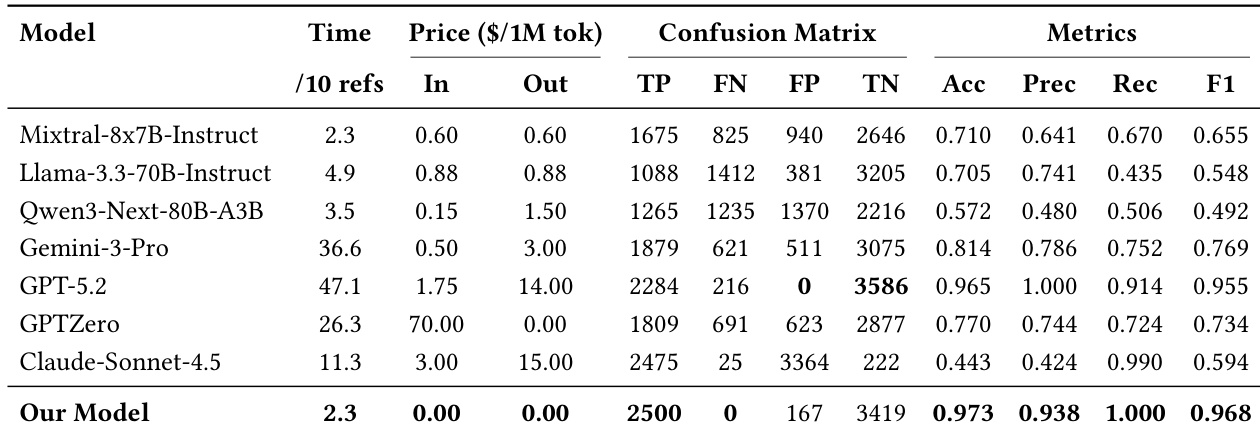
The authors use a generated benchmark and real-world test set to evaluate citation verification models, revealing that most existing systems struggle to balance detecting hallucinated citations with preserving genuine ones. Their proposed model achieves near-perfect detection of fabricated references while maintaining low false positives on real citations, outperforming baselines in both accuracy and cost efficiency. Ablation studies confirm that each component—web search, semantic reasoning, and authoritative verification—plays a critical role in achieving this robust and efficient performance.
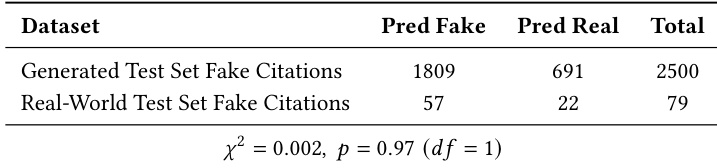
The authors evaluate their citation verification model against several baselines on a generated benchmark, showing it achieves near-perfect recall with zero false negatives and maintains high precision, outperforming others in balancing hallucination detection and real citation preservation. Their model also incurs no API cost and processes references as quickly as the most efficient baselines, leveraging lightweight agents and external tools rather than relying on expensive LLM inference. Results confirm the system’s ability to enforce strict authenticity constraints while remaining cost-effective and scalable.
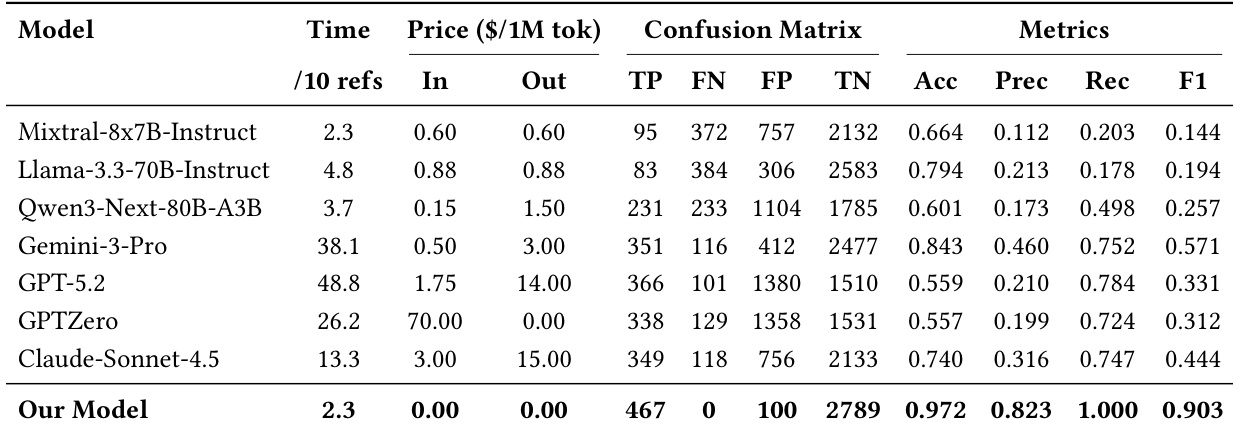
The authors evaluate their citation verification framework against ablated variants, showing that removing the Scholar Agent significantly reduces recall, while replacing the LLM Judge with string matching drastically lowers precision and F1 score. Disabling the Web Search Agent increases processing time eightfold, confirming its role in maintaining efficiency. These results demonstrate that each component contributes uniquely to the system’s balanced accuracy, reliability, and speed.
The authors evaluate their citation verification model against several baselines on a generated benchmark, showing it achieves near-perfect recall with zero false negatives while maintaining high precision and low false positives. Their model also outperforms commercial LLMs in cost efficiency, incurring no monetary cost and matching or exceeding speed, due to its architecture that limits LLM use to high-level judgment while offloading verification to lightweight agents. Results indicate the model enforces strict citation authenticity rather than relying on plausibility, leading to more reliable and interpretable verification in both controlled and real-world settings.
The authors evaluate citation verification models across two test sets: a generated benchmark with controlled hallucinations and a real-world set with naturally occurring errors. Results show that existing models struggle to balance detecting fake citations with preserving real ones, while their proposed system achieves high accuracy and reliability by combining lightweight agents with authoritative verification. The framework also maintains efficiency and cost-effectiveness by limiting heavy LLM usage to final judgment rather than full retrieval.