Command Palette
Search for a command to run...
Enhancing Spatial Understanding in Image Generation via Reward Modeling
Enhancing Spatial Understanding in Image Generation via Reward Modeling
Zhenyu Tang Chaoran Feng Yufan Deng Jie Wu Xiaojie Li Rui Wang Yunpeng Chen Daquan Zhou
Abstract
Recent progress in text-to-image generation has greatly advanced visual fidelity and creativity, but it has also imposed higher demands on prompt complexity-particularly in encoding intricate spatial relationships. In such cases, achieving satisfactory results often requires multiple sampling attempts. To address this challenge, we introduce a novel method that strengthens the spatial understanding of current image generation models. We first construct the SpatialReward-Dataset with over 80k preference pairs. Building on this dataset, we build SpatialScore, a reward model designed to evaluate the accuracy of spatial relationships in text-to-image generation, achieving performance that even surpasses leading proprietary models on spatial evaluation. We further demonstrate that this reward model effectively enables online reinforcement learning for the complex spatial generation. Extensive experiments across multiple benchmarks show that our specialized reward model yields significant and consistent gains in spatial understanding for image generation.
One-sentence Summary
Researchers from Peking University and ByteDance Seed propose SpatialScore, a reward model trained on 80k+ preference pairs to enhance spatial understanding in text-to-image generation, enabling effective reinforcement learning and outperforming proprietary models in spatial accuracy across benchmarks.
Key Contributions
- We introduce SpatialReward-Dataset, a human-curated collection of 80k adversarial preference pairs designed to evaluate spatial relationship accuracy in text-to-image generation, addressing the lack of reliable spatial evaluation data.
- We develop SpatialScore, a reward model trained on this dataset that outperforms leading proprietary models in assessing complex spatial relationships, enabling more precise feedback for reinforcement learning.
- We integrate SpatialScore into online reinforcement learning with a top-k filtering strategy, achieving consistent and significant improvements in spatial understanding across multiple benchmarks compared to the base model.
Introduction
The authors leverage reinforcement learning to improve how text-to-image models handle complex spatial relationships—critical for generating accurate, compositionally correct scenes when prompts describe object arrangements. Prior reward models, whether CLIP-based or VLM-driven, struggle to detect spatial errors, often rewarding incorrect layouts, while rule-based or proprietary systems are either too simplistic or too costly for online RL. Their main contribution is SpatialScore, a reward model trained on an 80K adversarial preference dataset (SpatialReward-Dataset), which reliably evaluates spatial accuracy and outperforms leading proprietary models; they further integrate it into online RL with a top-k filtering strategy, achieving consistent gains in spatial reasoning across benchmarks.
Dataset

-
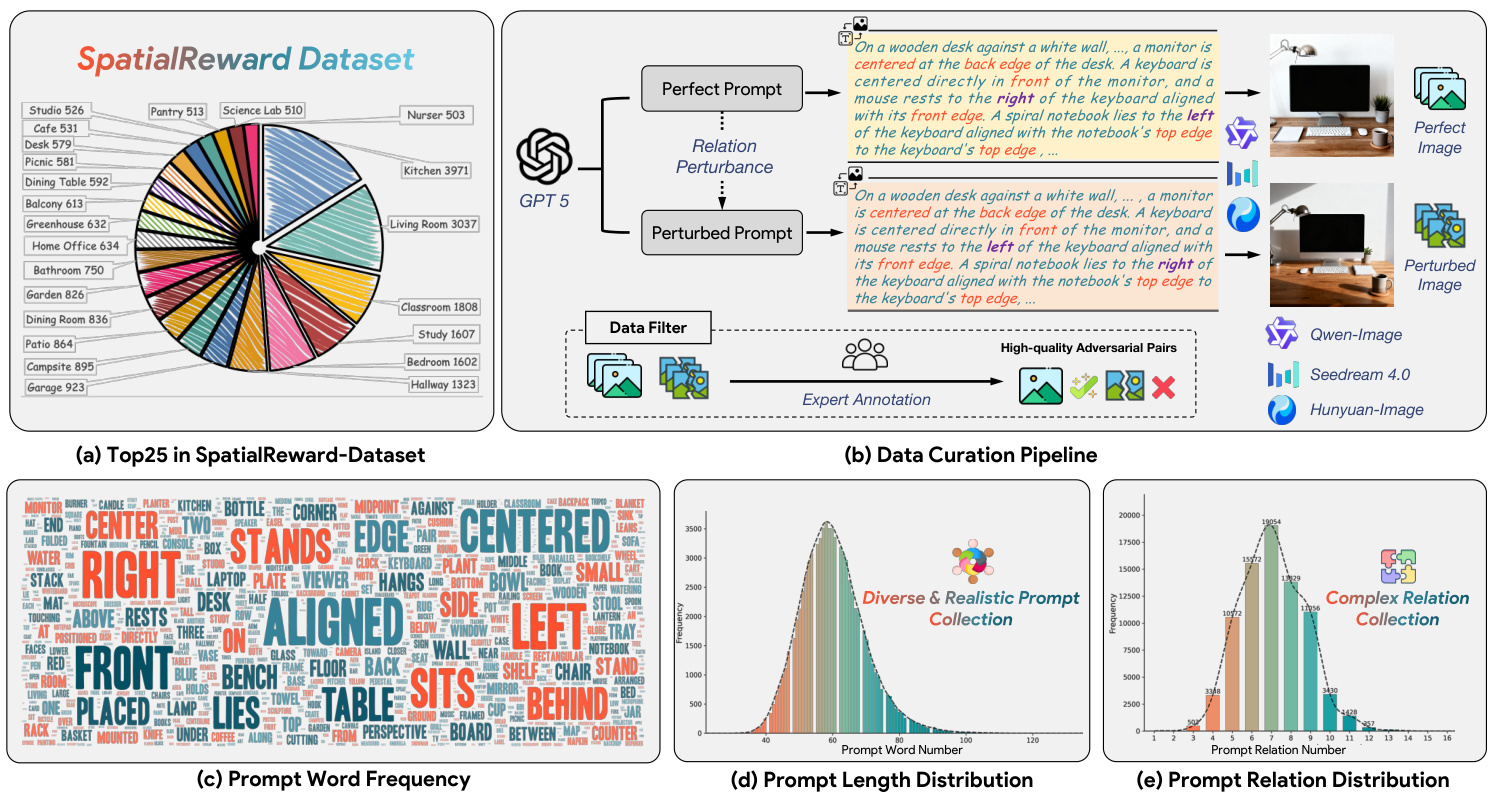
The authors use the SPATIALREWARD-DATASET, a curated collection of 80K adversarial image pairs, as the foundation for reward model training. Each pair consists of a “perfect” image (generated from a clean prompt) and a “perturbed” image (generated from a spatially altered version of the same prompt), designed to isolate spatial reasoning errors.
-
Dataset construction begins with GPT-5 generating complex prompts describing multi-object spatial relationships. GPT-5 then perturbs each prompt by altering one or more spatial relations (e.g., swapping positions, shifting left/right) while preserving all others. Images are generated using Qwen-Image, HunyuanImage-2.1, and Seedream4.0 — models selected for strong text-image alignment to reduce post-generation filtering.
-
All 80K pairs undergo manual human review: perfect images must fully satisfy the spatial constraints in their prompts; perturbed images must visibly deviate in the intended spatial relation. Pairs failing either criterion are discarded. Prompts are notably longer and more spatially complex than those in GenEval, supporting higher compositional diversity.
-
For evaluation, the authors build a separate benchmark of 365 preference pairs using the same generation and verification pipeline. Human annotators validate each pair to ensure reliable ground truth. Evaluation includes proprietary models (GPT-5, Gemini-2.5 Pro), Qwen2.5-VL series (7B–72B), and existing reward models (PickScore, ImageReward, UnifiedReward, HPS). To mitigate order bias, each pair is evaluated twice with reversed image order, and accuracy is averaged across both runs.
-
No cropping or metadata construction is mentioned. The focus is on prompt-driven generation and human validation to ensure spatial fidelity and contrast. The dataset’s design enables training and evaluation of reward models specifically on spatial reasoning capability.
Method
The authors leverage a two-stage framework that first trains a specialized reward model, SpatialScore, and then deploys it within an online reinforcement learning loop to enhance spatial reasoning in image generation. The architecture centers on a vision-language model backbone fine-tuned to output probabilistic reward scores, followed by a policy optimization phase that uses group-based advantage estimation with top-k filtering to mitigate bias.
The reward model is built upon Qwen2.5-VL-7B, whose original language modeling head is replaced with a linear reward head Rϕ that maps joint image-text embeddings to a scalar reward. To model uncertainty and improve ranking robustness, the authors adopt a Gaussian formulation: the final-layer embedding of a special token—inserted at the end of the instruction prompt—is projected via an MLP into parameters μ and σ, defining a one-dimensional Gaussian distribution s∼N(μ,σ2). The reward score is then sampled from this distribution. For each preference pair (c,yw,yl), the model performs two forward passes to compute scores sw and sl, and optimizes using the Bradley-Terry model via binary cross-entropy loss:
LReward(θ)=Ec,yw,yl[−logσ(Rϕ(Hϕ(yw,c))−Rϕ(Hϕ(yl,c)))].Training employs LoRA to preserve pretrained knowledge and uses 1000 Monte Carlo samples per pair to stabilize gradient estimation. The model is trained on 80k preference pairs from the SpatialReward-Dataset, constructed by perturbing spatial relations in prompts and generating corresponding image pairs via Qwen-Image, Seedream 4.0, and Hunyuan-Image, followed by expert annotation to ensure high-quality adversarial pairs. Refer to the framework diagram for the full data curation pipeline, including prompt perturbation, image generation, and filtering stages.
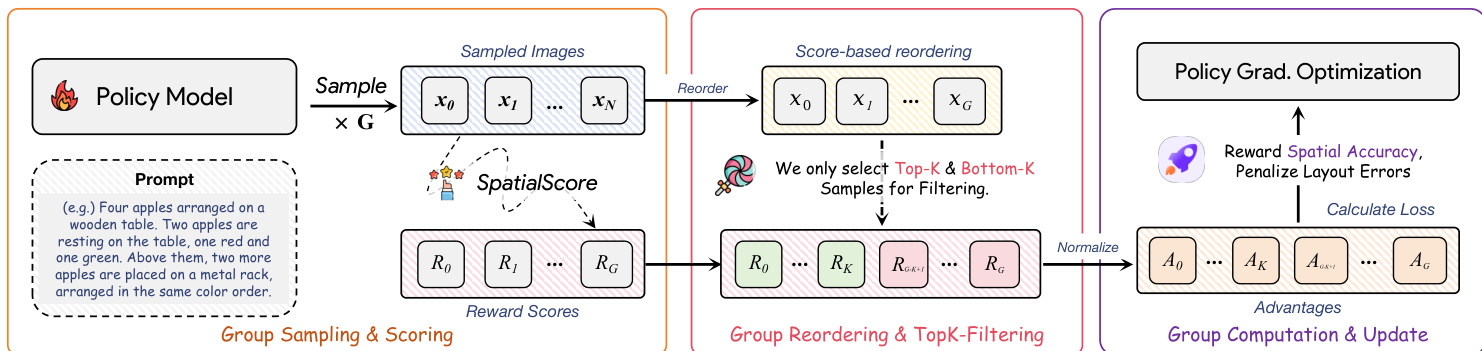
For policy optimization, the authors integrate SpatialScore into the GRPO algorithm using FLUX.1-dev as the base generator. The policy πθ samples a group of G images per prompt via an SDE derived from flow matching, enabling stochastic exploration. Each image is scored by SpatialScore, and advantages are computed by normalizing scores within the group:
Ai=std({R(x0i,c)}i=1G)R(xi0,c)−mean({R(x0i,c)}i=1G).To counter advantage bias—where easy prompts yield negative advantages for high-quality samples due to inflated group means—the authors introduce a top-k and bottom-k filtering strategy. Only the top-k and bottom-k scored samples are used to compute group statistics and update the policy, ensuring balanced reward signals. The policy is then optimized via clipped surrogate objective:
LGRPO(θ)=∣S∣1i∈S∑T1t=0∑T−1min(rti(θ)Ati,clip(rti(θ),1−ϵ,1+ϵ)Ati),with an additional KL penalty to constrain deviation from a reference policy. As shown in the training pipeline diagram, this process directly rewards spatial accuracy and penalizes layout errors, enabling targeted enhancement of spatial understanding.
Experiment
- SPATIALSCORE, a fine-tuned 7B reward model, achieves state-of-the-art accuracy (95.77%) in evaluating complex multi-object spatial relationships, outperforming proprietary models like GPT-5 and Gemini-2.5 Pro while being cost-efficient for online RL.
- Applied in online RL to fine-tune Flux.1-dev, SPATIALSCORE significantly improves spatial reasoning in generated images, especially for long and complex prompts, surpassing rule-based GenEval-trained variants which degrade on spatial fidelity and introduce artifacts.
- The RL-enhanced model shows consistent gains across in-domain and out-of-domain benchmarks (DPG-Bench, TIIF-Bench, UniGenBench++), with performance approaching proprietary models like GPT-Image-1 and demonstrating broad generalization beyond spatial tasks.
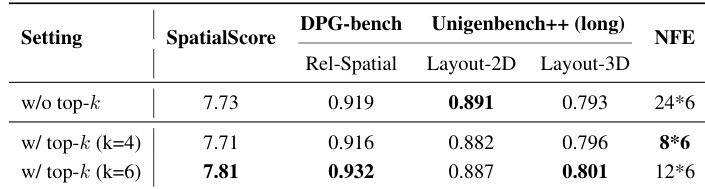
- Ablations confirm that scaling SPATIALSCORE’s backbone improves accuracy, with the 7B variant offering the best balance of performance and training efficiency; top-k filtering in RL training accelerates convergence and reduces computational cost without sacrificing quality.
- SPATIALSCORE’s effectiveness extends to other base models like Qwen-Image, yielding consistent spatial understanding improvements across benchmarks, validating its generalizability and robustness as a reward signal for spatially complex image generation.
The authors use their specialized reward model SpatialScore to guide online reinforcement learning on Flux.1-dev, achieving substantial gains in spatial reasoning across multiple benchmarks compared to both the base model and a variant trained with rule-based rewards. Results show consistent improvements in spatial alignment, particularly on long prompts and out-of-domain evaluations, indicating stronger generalization and more faithful adherence to complex multi-object spatial descriptions.

The authors use their specialized reward model SpatialScore to guide online reinforcement learning for image generation, achieving significant improvements in spatial understanding across multiple benchmarks. Results show that their method outperforms the base Qwen-Image model not only on in-domain spatial evaluation but also on out-of-domain spatial subdimensions, including both short and long prompt settings. The gains demonstrate that reward-guided training with SpatialScore enhances the model’s ability to accurately render complex multi-object spatial relationships described in prompts.

The authors use their specialized reward model SPATIALSCORE to guide online RL training of Flux.1-dev, achieving substantial gains in spatial understanding across multiple evaluation dimensions. Results show their method outperforms both the base model and a variant trained with rule-based rewards, particularly on complex spatial relationships and long prompts. The improved model also approaches the performance of proprietary systems like GPT-Image-1 on comprehensive alignment benchmarks.
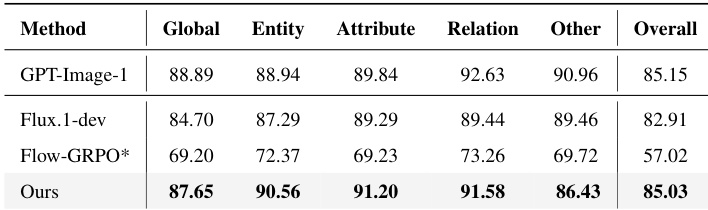
The authors use their specialized reward model SPATIALSCORE to guide online RL training of Flux.1-dev, resulting in improved performance across multiple spatial reasoning dimensions including object positioning and attribute consistency. Results show consistent gains over the base model, particularly in complex multi-object spatial relationships, while also demonstrating better generalization than models trained with rule-based rewards. The approach achieves higher overall scores by focusing on fine-grained spatial alignment rather than relying on generic text-image matching.

The authors use a top-k filtering strategy during online RL training to balance reward distribution across prompts of varying difficulty, which reduces computational cost while maintaining or improving performance. Results show that using k=6 achieves the best tradeoff, yielding higher scores on spatial reasoning benchmarks and fewer function evaluations compared to both the unfiltered baseline and the k=4 variant. This optimization enables more efficient training without sacrificing spatial understanding quality.