Command Palette
Search for a command to run...
CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
Abstract
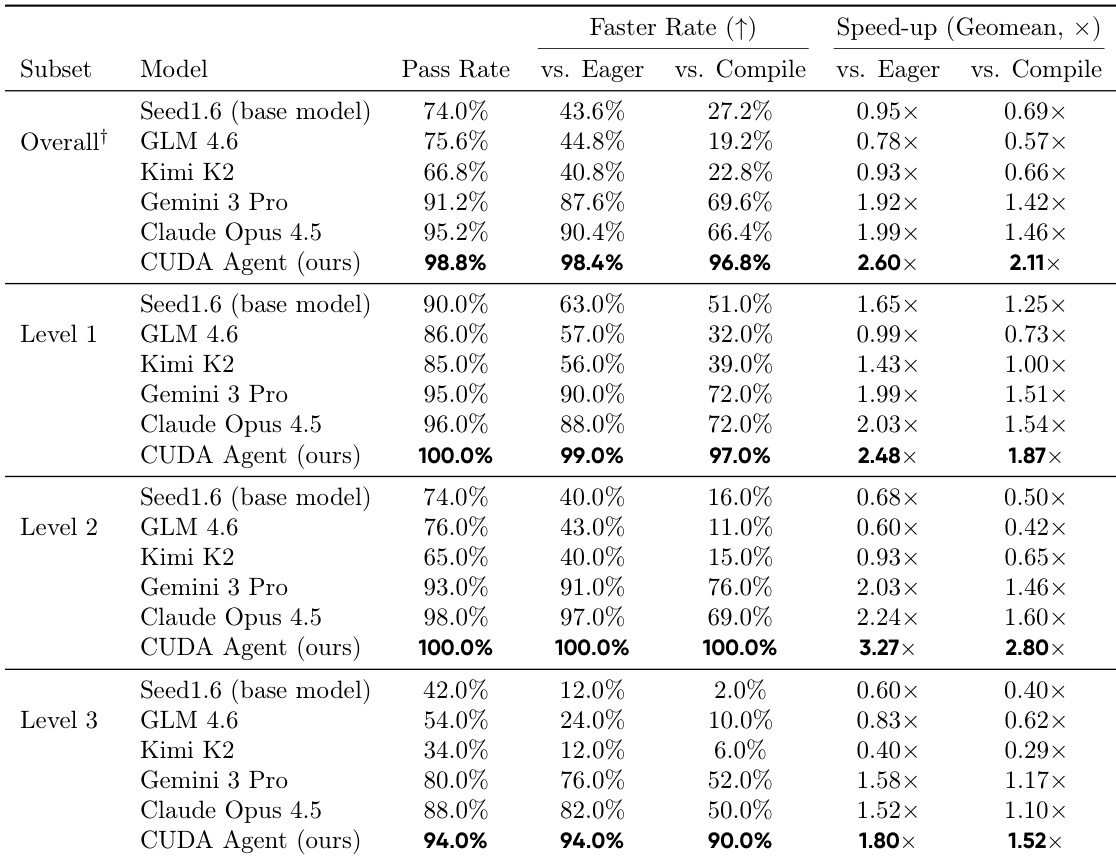
GPU kernel optimization is fundamental to modern deep learning but remains a highly specialized task requiring deep hardware expertise. Despite strong performance in general programming, large language models (LLMs) remain uncompetitive with compiler-based systems such as torch.compile for CUDA kernel generation. Existing CUDA code generation approaches either rely on training-free refinement or fine-tune models within fixed multi-turn execution-feedback loops, but both paradigms fail to fundamentally improve the model's intrinsic CUDA optimization ability, resulting in limited performance gains. We present CUDA Agent, a large-scale agentic reinforcement learning system that develops CUDA kernel expertise through three components: a scalable data synthesis pipeline, a skill-augmented CUDA development environment with automated verification and profiling to provide reliable reward signals, and reinforcement learning algorithmic techniques enabling stable training. CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100%, 100%, and 92% faster rate over torch.compile on KernelBench Level-1, Level-2, and Level-3 splits, outperforming the strongest proprietary models such as Claude Opus 4.5 and Gemini 3 Pro by about 40% on the hardest Level-3 setting.
One-sentence Summary
Researchers from ByteDance Seed and Tsinghua AIR introduce CUDA Agent, an agentic RL system that outperforms torch.compile and top LLMs by up to 100% on KernelBench via scalable data synthesis, skill-augmented environments, and stable RL training—enabling LLMs to master GPU kernel optimization without prior hardware expertise.
Key Contributions
- CUDA Agent introduces a large-scale agentic reinforcement learning system that enhances LLMs’ intrinsic CUDA kernel optimization capabilities through a scalable data synthesis pipeline, a skill-augmented development environment with automated verification and profiling, and RL techniques enabling stable long-context training.
- It addresses the limitations of prior approaches—such as static refinement loops or data leakage—by enabling autonomous, multi-turn debugging and optimization within a rigorously isolated environment that provides reliable performance-based reward signals.
- On KernelBench, CUDA Agent achieves 100%, 100%, and 92% speedups over torch.compile across Level-1, Level-2, and Level-3 splits, and outperforms proprietary models like Claude Opus 4.5 and Gemini 3 Pro by ~40% on the hardest Level-3 tasks.
Introduction
The authors leverage large-scale agentic reinforcement learning to tackle the challenge of generating high-performance CUDA kernels—a critical task in GPU-accelerated deep learning that traditionally demands deep hardware expertise. Prior approaches either rely on training-free heuristics or fine-tune models within rigid, fixed-turn loops, both of which fail to fundamentally improve the model’s intrinsic optimization ability and are often constrained by data leakage or limited context. CUDA Agent overcomes these limitations by integrating a scalable data synthesis pipeline, a skill-augmented development environment with automated verification and profiling, and RL techniques that enable stable training over long contexts and many interaction turns. The result is a system that outperforms torch.compile and top proprietary models like Claude Opus 4.5 and Gemini 3 Pro by up to 40% on the hardest benchmarks, demonstrating that LLMs can evolve from passive code generators into active performance optimizers for GPU computing.
Dataset

-
The authors use a custom-built training dataset called CUDA-Agent-Ops-6K², consisting of 6,000 curated PyTorch operator classes designed to train a CUDA-capable agent via reinforcement learning.
-
Dataset sources and composition:
- Seed problems are mined from the torch and transformers libraries, represented as torch.nn.Module subclasses with init and forward methods.
- Composite problems are synthesized using LLMs, which sample up to five torch operators and stack them sequentially into fused computational layers; transformers operators are excluded from synthesis due to their higher-level, multi-op nature.
- Final dataset includes both primitive operators and composite operators of varying depth (1 to 5 ops), plus standalone transformers modules for balance.
-
Filtering and quality control:
- Each operator must execute successfully in both Eager and Compile modes.
- Stochastic operators are excluded to ensure reproducibility.
- Outputs must vary meaningfully across inputs — no constant or numerically identical results allowed.
- Execution time in Eager mode is constrained to 1–100 ms to avoid trivial or overly heavy tasks.
- High similarity to KernelBench test cases is filtered using AST-based similarity (PythonASTSimilarity); samples exceeding 0.9 similarity are removed.
-
Data format and structure:
- Each sample includes the operator class plus two auxiliary functions: get_init_inputs() for class instantiation and getInputs() for forward pass inputs, forming self-contained, executable tasks.
- Final dataset composition reflects a deliberate mix: mostly composite operators (1–5 ops), with a subset of standalone transformers modules.
-
Usage in training:
- The dataset is used as the sole training corpus for the CUDA Agent, with no additional external data.
- Training tasks are sampled directly from the 6,000 filtered samples, with no explicit mixture ratios or split stratification mentioned — implying uniform sampling across the curated set.
Method
The authors leverage a large-scale agentic reinforcement learning system, CUDA Agent, designed to autonomously generate high-performance CUDA kernels for PyTorch models. The system is structured around three core components: a scalable data collection pipeline, a skill-integrated and non-hackable training environment, and algorithmic innovations for stable RL training. Each component is engineered to address the unique challenges of CUDA kernel generation, including the sparsity of relevant pretraining data, the need for precise correctness validation, and the instability of policy gradients in low-probability token spaces.
The agent operates within a structured workspace that enforces strict separation between user-modifiable and protected files. As shown in the figure below, the agent receives a SKILL.md prompt that defines its role as a PyTorch and CUDA expert, along with a predefined workdir containing the original model.py, protected infrastructure files (binding_registry.h, binding.cpp, utils/), and the kernels/ directory where all custom CUDA code must be implemented. The agent generates a model_new.py that imports and invokes custom operators implemented in kernels/.cu and kernels/_binding.cpp files. The GPU Pool executes the generated code, and the Performance module validates numerical correctness and measures execution time against PyTorch Eager and torch.compile baselines.
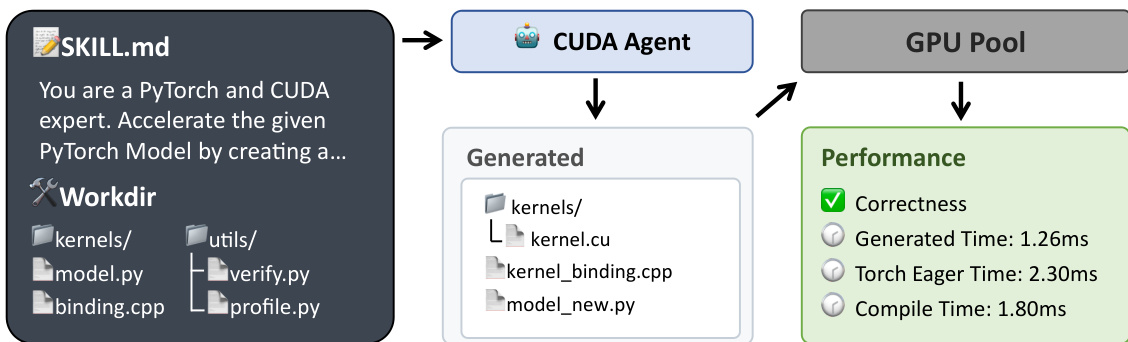
The agent loop follows a ReAct-style paradigm, interleaving reasoning, action execution, and observation. It is equipped with a suite of developer tools—including Bash, Read/Write, Edit/MultiEdit, Glob, Grep, and NotebookEdit—that enable it to inspect, modify, compile, and debug code within a sandboxed environment. The agent is guided by a CUDA-specific SKILL.md that formalizes a four-step optimization process: (1) profile the native PyTorch model to identify bottlenecks, (2) implement custom CUDA operators targeting those bottlenecks, (3) compile and evaluate the optimized model, and (4) iterate until a 5% speedup over torch.compile is achieved while passing all correctness checks.
To prevent reward hacking, the system enforces multiple safeguards: protected evaluation scripts, execution-time constraints that forbid fallback to torch.nn.functional, validation against five random inputs, and a carefully engineered profiling pipeline with device synchronization and repeated measurements. The reward function is designed to be robust against outliers and bias toward easy kernels. Instead of using raw speedup, the authors assign a discrete reward r∈{−1,1,2,3} based on correctness and performance:
r=⎩⎨⎧−1321if correctness check failsif b(t,teager)∧b(t,tcomplie)if b(t,teager)otherwisewhere b(t,t0)=I[(t0−t)/t0>5%] indicates a significant speedup over baseline t0.
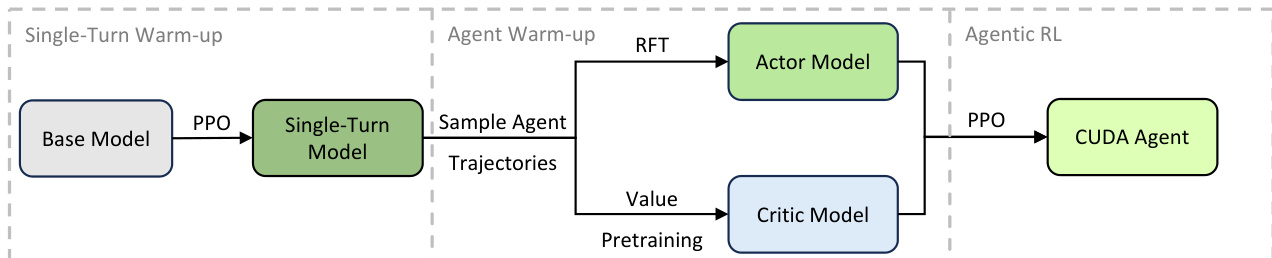
Training stability is achieved through a multi-stage initialization process. The authors observe that direct RL training collapses after 17 steps due to a severe domain distribution mismatch: CUDA kernel tokens are extremely rare in the base model’s pretraining data, leading to large variance in importance sampling ratios when numerical precision errors occur. To mitigate this, they introduce a warm-up phase illustrated in the figure below. First, a single-turn RL stage fine-tunes the base model using PPO. Then, Rejection Fine-Tuning (RFT) initializes the actor model by filtering trajectories that achieve positive rewards and exhibit valid behavior patterns. Concurrently, Value Pretraining initializes the critic model using Generalized Advantage Estimation on the same trajectory data. Only after this warm-up does the full agentic RL stage commence, using PPO with a clipped surrogate objective to optimize the actor policy.
The system’s effectiveness is demonstrated through case studies. For a Level 1 problem involving diagonal matrix multiplication, the agent recognizes that A⋅B (where A is diagonal) can be reduced to row-wise scaling, eliminating the need to materialize the diagonal matrix. This algebraic simplification, implemented in a grid-stride loop kernel, yields a 73.31× speedup. For a Level 2 problem with a sequence of matrix operations, the agent algebraically rearranges the computation to fuse operations, implements two custom kernels (one for column-wise reduction, one for vectorized dot product with shared-memory tree reduction), and achieves a 24.04× speedup. For a Level 3 ResNet BasicBlock, the agent folds BatchNorm into Conv weights, uses cuDNN’s fused convolution-bias-activation API, and fuses residual addition with ReLU, achieving a 3.59× speedup while preserving numerical equivalence.
The agent’s ability to combine high-level algebraic reasoning, library-level fusion, and low-level CUDA optimizations—such as memory coalescing, shared memory tiling, and vectorized loads—demonstrates a comprehensive approach to kernel generation that goes beyond simple code translation. The structured environment, robust reward design, and stable training protocol enable the agent to consistently produce kernels that outperform torch.compile across diverse problem complexities.
Experiment
- CUDA Agent outperforms leading proprietary and open-source models in both correctness and optimization, achieving near-perfect pass and faster rates by leveraging agentic RL to generate highly optimized CUDA kernels.
- The agent consistently surpasses static compiler heuristics, especially in complex operator fusion tasks, by exploring hardware-specific optimizations inaccessible to rule-based compilers.
- Multi-turn interaction with execution feedback (compilation, profiling, errors) is essential; single-turn training leads to degraded performance and regression.
- A milestone-based reward design proves superior to raw speed-up rewards, enabling more reliable discovery of performance gains by avoiding noisy runtime signals.
- Multi-stage training—particularly Rejection Sampling Fine-Tuning and Value Pretraining—is critical to stabilize learning, prevent policy collapse, and guide efficient exploration.
- Common optimization patterns include algebraic simplification, kernel fusion, memory access tuning, hardware-aware TF32 use, and strategic library calls, demonstrating systematic bridging of algorithmic and low-level engineering.
- Training relies on a large, isolated GPU sandbox for stable measurements, which, while effective, imposes significant resource demands and limits accessibility.
The authors use a multi-turn reinforcement learning framework with specialized reward shaping and pretraining stages to train a CUDA optimization agent, which consistently outperforms both proprietary and open-source models across all task difficulty levels. Results show that iterative feedback from compilation and profiling, combined with milestone-based rewards, enables the agent to generate kernels that are not only functionally correct but also significantly faster than static compiler baselines. The agent’s performance gains are most pronounced in complex operator sequences, where it discovers hardware-aware optimizations that traditional compilers cannot achieve through rule-based heuristics.
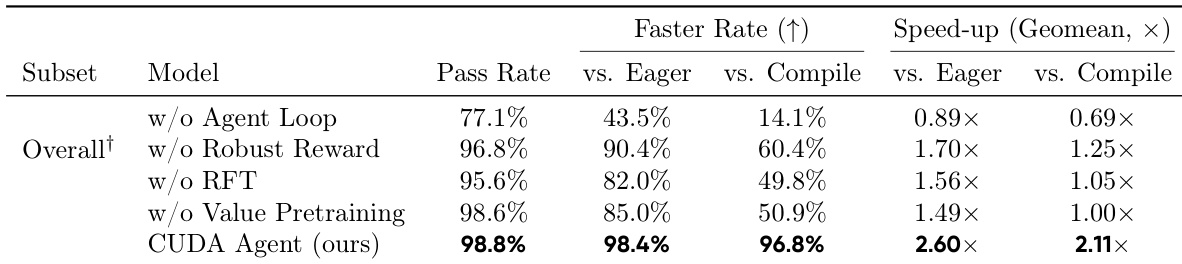
The authors use a multi-turn reinforcement learning framework with skill-integrated feedback to train a CUDA optimization agent, enabling iterative refinement through compilation and profiling signals. Results show that this approach significantly outperforms both general-purpose LLMs and static compiler baselines, achieving near-perfect correctness and substantial speedups by discovering hardware-aware optimizations inaccessible to rule-based systems. Ablation studies confirm that the agent loop, milestone-based reward design, and multi-stage training are critical to stable and effective policy learning.

The authors use a multi-stage reinforcement learning framework with an interactive agent loop to train a specialized CUDA kernel optimizer, achieving a 98.8% pass rate and 96.8% faster rate against torch.compile. Results show that removing key components—such as the agent loop, robust reward design, or value pretraining—leads to significant drops in optimization quality and training instability, confirming their necessity for reliable performance gains. The final system consistently outperforms both general-purpose LLMs and static compiler baselines by leveraging iterative feedback and hardware-aware transformations.