Command Palette
Search for a command to run...
From Scale to Speed: Adaptive Test-Time Scaling for Image Editing
From Scale to Speed: Adaptive Test-Time Scaling for Image Editing
Abstract
Image Chain-of-Thought (Image-CoT) is a test-time scaling paradigm that improves image generation by extending inference time. Most Image-CoT methods focus on text-to-image (T2I) generation. Unlike T2I generation, image editing is goal-directed: the solution space is constrained by the source image and instruction. This mismatch causes three challenges when applying Image-CoT to editing: inefficient resource allocation with fixed sampling budgets, unreliable early-stage verification using general MLLM scores, and redundant edited results from large-scale sampling. To address this, we propose ADaptive Edit-CoT (ADE-CoT), an on-demand test-time scaling framework to enhance editing efficiency and performance. It incorporates three key strategies: (1) a difficulty-aware resource allocation that assigns dynamic budgets based on estimated edit difficulty; (2) edit-specific verification in early pruning that uses region localization and caption consistency to select promising candidates; and (3) depth-first opportunistic stopping, guided by an instance-specific verifier, that terminates when intent-aligned results are found. Extensive experiments on three SOTA editing models (Step1X-Edit, BAGEL, FLUX.1 Kontext) across three benchmarks show that ADE-CoT achieves superior performance-efficiency trade-offs. With comparable sampling budgets, ADE-CoT obtains better performance with more than 2x speedup over Best-of-N.
One-sentence Summary
Researchers from CAS, UCAS, Alibaba, and University of Queensland propose ADE-CoT, an adaptive test-time scaling framework that dynamically allocates resources, verifies edits via region-aware checks, and stops early when goals are met—boosting efficiency and performance over prior Image-CoT methods for image editing tasks.
Key Contributions
- ADE-CoT addresses the inefficiency of applying Image-CoT to image editing by introducing difficulty-aware resource allocation, dynamically assigning more sampling budget to complex edits while conserving computation on simple ones.
- It replaces general MLLM verification with edit-specific metrics—region localization and caption consistency—to accurately prune low-potential candidates early, avoiding misjudgments that discard promising results in early denoising stages.
- ADE-CoT implements depth-first opportunistic stopping guided by an instance-specific verifier, terminating generation once intent-aligned results are found, achieving over 2× speedup over Best-of-N while improving performance across three SOTA editing models and benchmarks.
Introduction
The authors leverage test-time scaling—traditionally used to boost text-to-image generation—to improve image editing, where outputs must align precisely with both source images and editing instructions. Prior Image-CoT methods, designed for open-ended generation, suffer from three key flaws in editing: fixed sampling budgets waste compute on simple edits, general MLLM verifiers misjudge early-stage candidates, and large-scale sampling yields redundant correct results. To fix this, they introduce ADE-CoT, which dynamically allocates compute based on edit difficulty, uses region- and caption-aware verification for early pruning, and applies depth-first opportunistic stopping to terminate once an intent-aligned result is found. Evaluated across three state-of-the-art models, ADE-CoT delivers over 2x speedup with better performance than Best-of-N under comparable budgets.
Method
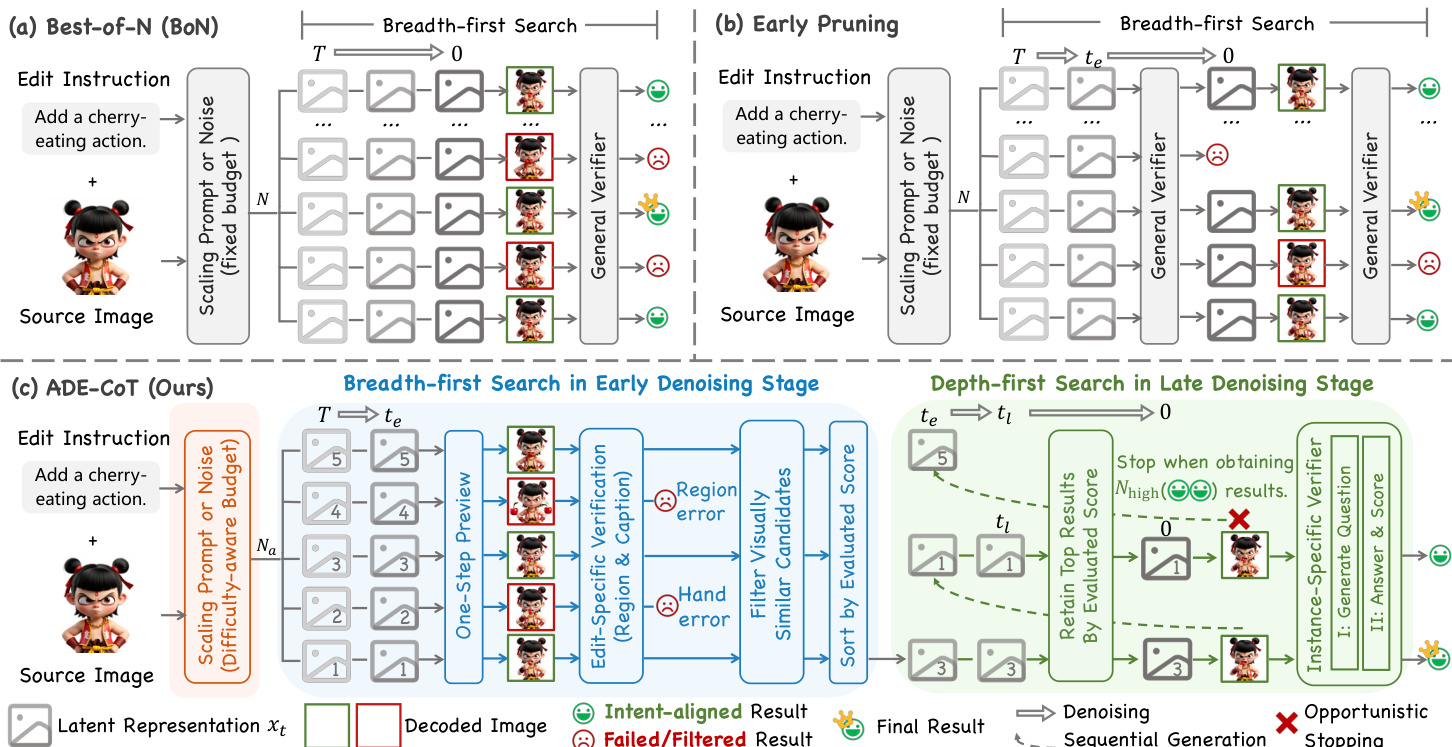
The authors leverage a three-stage adaptive framework, ADE-CoT, to address the inefficiencies and inaccuracies of standard Image-CoT methods in image editing. The core innovation lies in dynamically allocating computational resources, refining early-stage verification with edit-specific signals, and terminating generation as soon as sufficient intent-aligned results are found. This approach shifts from a fixed, breadth-first search to a guided, depth-first process that prioritizes quality and efficiency.
The framework begins with a difficulty-aware resource allocation strategy. Instead of using a fixed sampling budget N, the system first generates a single candidate image from the source image Isrc and edit instruction c. The general MLLM verifier assigns an initial score S to this candidate, which serves as a proxy for edit difficulty. The adaptive budget Na is then computed as:
Na=Nmin+⌈(N−Nmin)×(1−S/Smax)γ⌉,where Nmin is the minimal budget, Smax is the maximum possible score, and γ controls sensitivity. This ensures that easy edits (high S) are processed with minimal samples, while difficult edits (low S) receive a larger budget, optimizing resource use.
Following budget allocation, the system enters the early pruning stage, which employs a depth-first search guided by edit-specific verification. At an early denoising timestep te, the system generates a set of Na intermediate latents. For each, a one-step preview mechanism estimates the clean latent x0∣te from the noisy latent xte using the model’s predicted noise ϵθ:
x0∣te=xte−σteϵθ(xte,Tte).This preview image I0∣te is then evaluated using a unified score S that combines three components: a general MLLM score Sgen, an edited-region correctness score Sreg, and an instruction-caption consistency score Scap. The region correctness score is derived by prompting an MLLM with Preg to identify the object to edit or keep, which is then used to generate a binary mask M via Grounded SAM2. The per-pixel change map Δ between the edited and source image is computed and normalized via softmax, and Sreg is the sum of changes within the mask:
Sreg=H,W∑M⊙H,Wsoftmax(Δ).The caption consistency score is computed by prompting an MLLM with Pcap to generate a target caption ccap for the ideally edited image, and then evaluating the CLIP similarity between the preview and this caption:
Scap=CLIPScore(I,ccap).The unified score is a weighted sum:
S=Sgen+λregSreg+λcapScap.Candidates scoring below a rejection threshold Srj are pruned. To further reduce redundancy, visually similar candidates are filtered using DINOv2 embeddings, and the remaining candidates are sorted by their unified score in descending order.
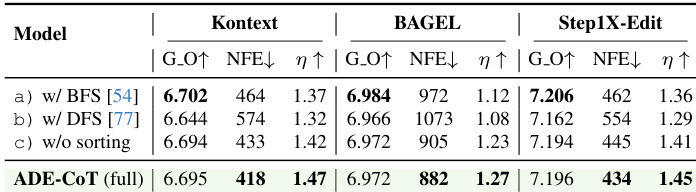
The final stage is depth-first opportunistic stopping. The system processes the sorted candidates sequentially. At a later timestep tl, it applies an adaptive filter: a candidate is retained for full generation only if its preview score is within a tolerance δ of the current best score. For retained candidates, the system performs full denoising to t=0 and applies an instance-specific verifier. This verifier uses a two-stage MLLM prompt: first, Pq generates five specific yes/no questions about the edit, and then Pa answers them. The instance-specific score Sspec is the count of “yes” answers. The search stops after Nhigh candidates achieve a perfect score (all “yes” answers), and the candidate with the highest combined score is selected as the final output.
Refer to the framework diagram for a visual comparison of the three strategies. The diagram illustrates how ADE-CoT integrates difficulty-aware budgeting, edit-specific verification, and opportunistic stopping to overcome the limitations of fixed-budget and general-score-based methods.
Experiment
- ADE-CoT significantly improves performance-efficiency trade-offs across multiple benchmarks (GEdit-Bench, AnyEdit-Test, Reason-Edit) by reducing computational cost while maintaining or exceeding baseline quality.
- It achieves over 2x higher reasoning efficiency and 2.7–4.9x higher outcome efficiency compared to Best-of-N, indicating substantial reductions in redundant computation.
- Difficulty-aware resource allocation dynamically scales sampling budgets based on edit complexity, preserving quality while cutting NFE by up to 24% without degradation.
- Edit-specific verifiers enhance early pruning accuracy by targeting localization and semantic alignment, reducing misjudgments by 63% and enabling higher rejection thresholds.
- Opportunistic stopping minimizes late-stage redundancy by halting generation once sufficient high-quality results are found, improving robustness with minimal quality loss.
- ADE-CoT consistently outperforms prior Image-CoT methods (PRM, PARM, TTS-EF) under both fixed budget and comparable performance settings, validating its hybrid search and pruning strategies.
- The method is robust across different MLLMs, with stronger verifiers yielding incremental gains, though MLLM overhead and hallucination remain practical limitations.
- Qualitative results show superior handling of complex, multi-turn, and fine-grained edits, with instance-specific verification enabling detection of subtle errors missed by general scores.
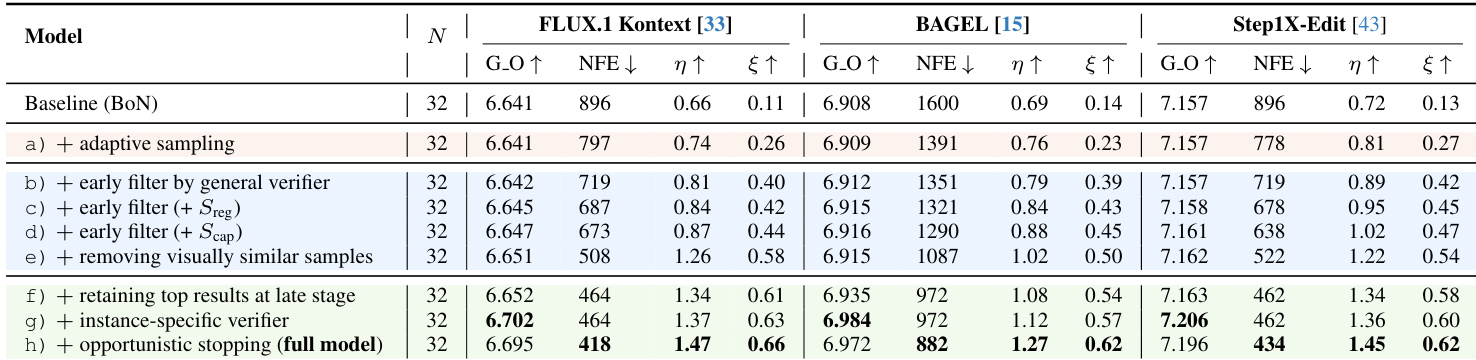
The authors use ADE-CoT to improve the efficiency of image editing by adaptively allocating computational resources and pruning redundant candidates. Results show that their method achieves comparable or better performance than Best-of-N while significantly reducing denoising steps, with the full model delivering the highest reasoning and outcome efficiency across all tested editing models. This improvement stems from combining difficulty-aware sampling, edit-specific verification, and opportunistic stopping to minimize wasted computation without sacrificing output quality.
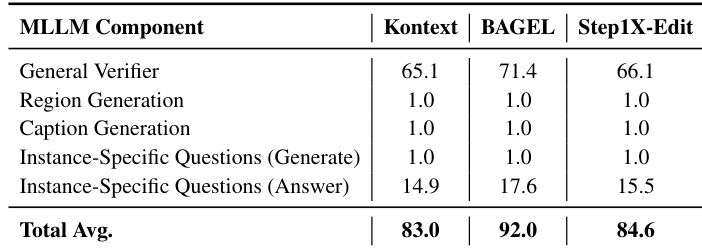
The authors use MLLM components to verify image edits, with the general verifier accounting for most queries while instance-specific question answering adds moderate overhead. Across three models, total average MLLM calls per case range from 83.0 to 92.0, showing that edit-specific verification introduces limited additional cost relative to the overall framework. Results confirm that targeted verification strategies achieve significant computational savings without proportional increases in MLLM usage.
The authors use ADE-CoT to improve the performance-efficiency trade-off in image editing by adaptively allocating computation and reducing redundant sampling. Results show that ADE-CoT consistently achieves higher reasoning efficiency and lower computational cost compared to baseline strategies across multiple models, without degrading output quality. The method’s gains stem from difficulty-aware budgeting, edit-specific verification, and opportunistic stopping, which together minimize wasted computation while preserving high-fidelity outputs.
The authors use ADE-CoT to adaptively allocate computational resources during image editing, achieving comparable or better performance than Best-of-N while significantly reducing denoising steps. Results show that ADE-CoT improves reasoning efficiency by over 2x and outcome efficiency by up to 4.9x across benchmarks, indicating effective pruning and reduced redundancy. The method consistently outperforms baselines under fixed sampling budgets and maintains quality with lower computational cost when performance is matched.
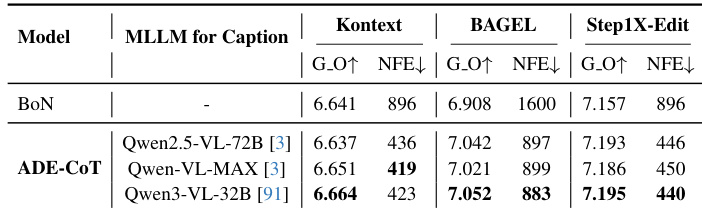
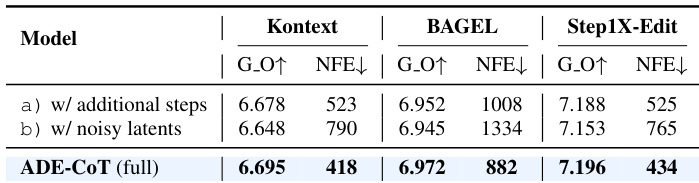
The authors use ADE-CoT to reduce computational cost while maintaining or improving image editing quality across multiple models. Results show that ADE-CoT achieves lower NFE than both additional-step and noisy-latent preview methods, indicating more efficient resource use without sacrificing output quality. This efficiency stems from adaptive sampling and early pruning guided by edit-specific verification.