Command Palette
Search for a command to run...
RubricBench: Aligning Model-Generated Rubrics with Human Standards
RubricBench: Aligning Model-Generated Rubrics with Human Standards
Abstract
As Large Language Model (LLM) alignment evolves from simple completions to complex, highly sophisticated generation, Reward Models are increasingly shifting toward rubric-guided evaluation to mitigate surface-level biases. However, the community lacks a unified benchmark to assess this evaluation paradigm, as existing benchmarks lack both the discriminative complexity and the ground-truth rubric annotations required for rigorous analysis. To bridge this gap, we introduce RubricBench, a curated benchmark with 1,147 pairwise comparisons specifically designed to assess the reliability of rubric-based evaluation. Our construction employs a multi-dimensional filtration pipeline to target hard samples featuring nuanced input complexity and misleading surface bias, augmenting each with expert-annotated, atomic rubrics derived strictly from instructions. Comprehensive experiments reveal a substantial capability gap between human-annotated and model-generated rubrics, indicating that even state-of-the-art models struggle to autonomously specify valid evaluation criteria, lagging considerably behind human-guided performance.
One-sentence Summary
Researchers from CityU Hong Kong, Tencent, McGill-Mila, and UI Springfield propose RubricBench, a benchmark with 1,147 expert-annotated pairwise comparisons to evaluate rubric-guided LLM alignment, exposing critical gaps between human and model-generated rubrics in handling nuanced, biased inputs.
Key Contributions
- RubricBench introduces the first unified benchmark with 1,147 expert-annotated pairwise comparisons designed to evaluate rubric-guided reward models, addressing the lack of discriminative complexity and ground-truth rubric annotations in existing datasets.
- The benchmark employs a multi-dimensional filtration pipeline to target hard samples with nuanced input complexity and misleading surface biases, paired with atomic rubrics derived strictly from instructions to enable rigorous assessment of rubric quality and preference accuracy.
- Experiments reveal a 27% accuracy gap between human-annotated and model-generated rubrics, demonstrating that even state-of-the-art models fail to autonomously specify valid evaluation criteria, highlighting cognitive misalignment as the core bottleneck in rubric-guided reward modeling.
Introduction
The authors leverage rubric-guided evaluation to address the growing misalignment between reward models and user intent as LLM outputs become more complex. Prior reward models often favor surface-level traits like verbosity or formatting over actual task completion, and while generative reward models attempt to rationalize judgments via Chain-of-Thought, they lack grounding in verifiable constraints. Existing benchmarks fail to test rubric-based evaluation rigorously due to outdated samples, lack of discriminative difficulty, and absence of human-annotated rubrics as ground truth. The authors’ main contribution is RubricBench, a curated benchmark of 1,147 challenging pairwise comparisons augmented with expert-annotated, instruction-derived rubrics. Their experiments reveal a significant 27% performance gap between human and model-generated rubrics, exposing that current models struggle to autonomously define valid evaluation criteria — a bottleneck that must be solved to achieve trustworthy alignment.
Dataset

-
The authors use RubricBench, a benchmark of 1,147 pairwise comparisons, each paired with an expert-annotated rubric derived solely from the instruction to avoid response-aware leakage. Rubrics are structured as atomic binary checks (Yes/No) to enable granular diagnosis.
-
Data is sourced from existing high-quality benchmarks: HelpSteer3, PPE, and RewardBench2. These are filtered to remove “easy” pairs and retain only discriminative examples that expose model evaluation failures.
-
The benchmark spans five domains: Chat (36.5%), Coding (23.9%), STEM Reasoning (23.8%), Instruction Following (8.8%), and Safety (7.0%). Most examples include 4–6 rubric items, with rubrics kept concise—comparable in length to instructions, not responses.
-
Filtering occurs across three dimensions:
• Input Complexity: Retains instructions with explicit and implicit multi-part requirements (e.g., “explain blockchain to grandparents” implies avoiding jargon).
• Output Surface Bias: Keeps pairs where the rejected response misleads via length (≥1.5× longer), formatting (e.g., Markdown/JSON), or tone (overly confident language).
• Process Failures: Uses judge models to identify reasoning errors (hallucinations, logical gaps, constraint erosion) requiring CoT inspection. -
Annotations are performed by 9 expert annotators—domain practitioners and CS PhD candidates—with deep NLP evaluation experience to ensure accurate capture of both technical and implicit constraints.
-
The benchmark is not used for training; it is designed for evaluating reward models (RMs) by testing their ability to align with human-derived, instruction-based rubrics rather than surface or final-answer cues.
Method
The authors leverage a three-stage pipeline to construct and validate instruction-aligned rubrics for evaluating model responses. The framework begins with source pool curation, proceeds through human annotation of atomic rubric items, and concludes with multi-layered quality control to ensure structural integrity and semantic objectivity.
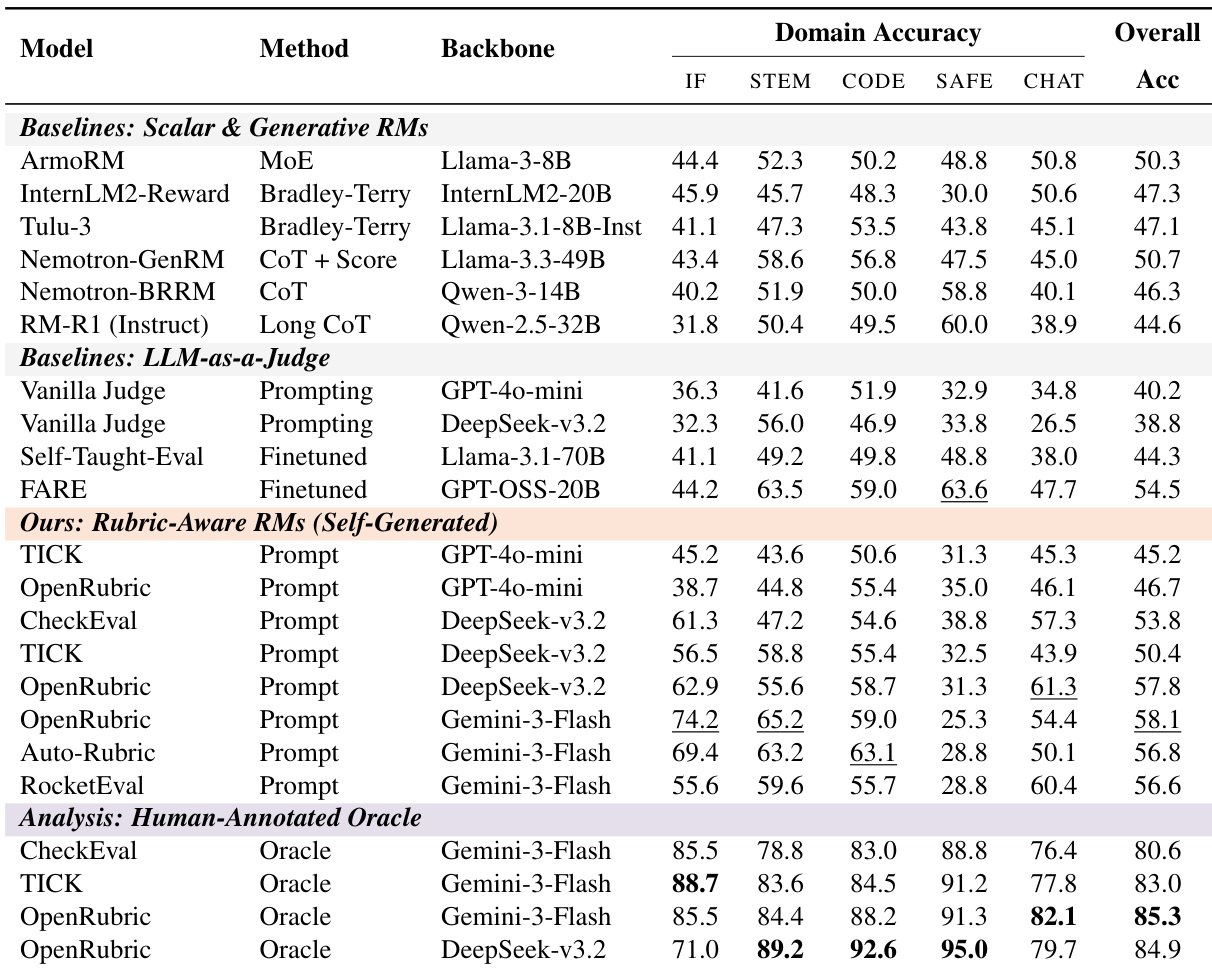
In Stage I: Curation, the system ingests instructions from diverse domains—Chat, IF (Instruction Following), Code, STEM, and Safety—and applies multi-dimensional filtering to assess input complexity, output bias, and process validity. For instance, an instruction such as “Can you make a 10 day notice email to my boss whose name is Walt? The company I am resigning from is ‘Common Market’” is evaluated for multi-constraint compliance, factual grounding, and absence of hallucinated reasoning steps. This stage ensures only well-formed, evaluable instructions proceed to annotation.
Refer to the framework diagram for a visual mapping of this curation logic and its downstream impact on rubric generation.
Stage II: Annotation focuses on generating instruction-only human rubrics. Annotators derive binary (Yes/No) criteria directly from the instruction, without exposure to candidate responses, to prevent post-hoc bias. Each rubric item must map to one of five domains: Reasoning, Content, Expression, Alignment, or Safety. For the resignation email example, rubric items include explicit constraints such as “States a 10-day resignation notice” and implicit ones like “Uses polite, professional tone.” The protocol enforces structural atomicity—each rubric contains 2–10 items, each phrased as a single, verifiable constraint—to enable independent evaluation.
Stage III: Quality Control implements a three-tiered verification protocol. First, expert reconciliation synthesizes dual-annotated rubrics into a consensus version, removing subjective or non-essential items. Second, structural validation checks for logical consistency, minimal redundancy, and strict instruction alignment. Third, stress testing validates rubrics against held-out model responses, particularly on safety and reasoning tasks, to ensure discriminative power across quality levels. The final output, RubricBench, comprises approximately 1,147 instruction-response pairs with 2–10 rubric items per sample, normalized into atomic checklists for cross-source comparison.
The normalization process converts both human and model-generated rubrics into flat sets of atomic items:
R={r1,…,rM},R~={r~1,…,r~K}.This enables precise structural alignment metrics and facilitates automated evaluation via deterministic decoding with Qwen3-30B-A3B (temperature = 0.0). Additionally, a meta-evaluation prompt is deployed to score the Intent Necessity (N) of each rubric rule on a 1–5 scale, measuring how essential the rule is to the user’s explicit or implicit intent—ensuring rubrics remain grounded in task requirements rather than evaluator interpretation.
Experiment
- Automated judges show a clear performance hierarchy on RubricBench, confirming the benchmark’s ability to differentiate evaluator quality.
- Without explicit rubrics, even strong models perform near chance levels, indicating they lack intrinsic ability to infer granular evaluation criteria.
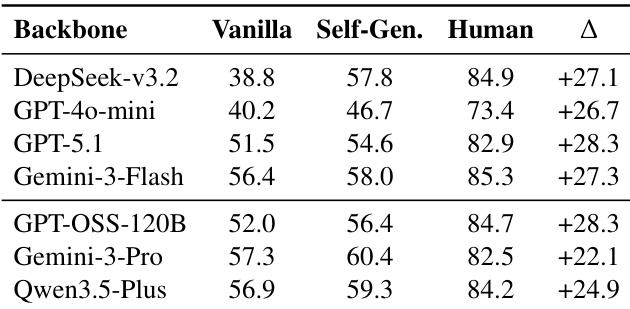
- Introducing self-generated rubrics improves performance moderately, but a large and persistent “Rubric Gap” remains—human-annotated rubrics consistently boost accuracy by ~26% across all models.
- This gap does not narrow with increased test-time compute, more sampled rubrics, or deeper refinement, proving it stems from rubric mis-specification, not reasoning or scaling limits.
- Models fail to generate rubrics that align with human priorities: they produce irrelevant or overly rigid rules, miss critical constraints, and misallocate attention, leading to inverted judgments.
- Even with perfect human rubrics, performance plateaus around 85%, revealing persistent execution errors where models ignore or misweight binding constraints during final decisions.
- Safety-critical tasks are especially vulnerable: self-generated rubrics often ignore refusal logic, while human rubrics restore near-perfect enforcement.
- Human evaluators also perform poorly under flawed rubrics, confirming that rubric quality—not evaluator capability—is the dominant bottleneck.
- Future progress requires aligning rubric content with human values and priorities, not just scaling generation or refinement.
The authors use controlled experiments to isolate the impact of rubric quality on automated judge performance, comparing vanilla prompting, self-generated rubrics, and human-annotated rubrics across multiple models. Results show that while self-generated rubrics improve accuracy over baseline methods, a consistent and substantial performance gap remains when compared to human-authored rubrics—indicating that rubric mis-specification, not reasoning capacity, is the primary bottleneck. This gap persists across model scales and is not closed by increasing test-time compute, confirming that current models systematically fail to autonomously induce valid evaluation criteria.
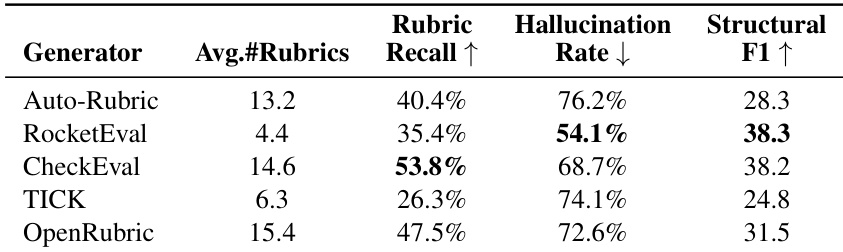
The authors evaluate multiple rubric-generation methods and find that even when models produce lengthy checklists, they frequently fail to capture essential human-defined constraints, resulting in high hallucination rates and low structural alignment. CheckEval achieves the highest rubric recall, suggesting that incorporating minimal human priors can improve the validity of generated criteria. Overall, the results highlight a persistent misalignment between model-generated and human-annotated rubrics, pointing to rubric formation—not reasoning capacity—as the primary bottleneck in automated evaluation.
Results show that even human evaluators experience a significant drop in accuracy when constrained by model-generated rubrics, confirming that rubric quality—not evaluator capability—is the primary bottleneck. The performance gap persists across both human and model judges, reinforcing that mis-specified rubrics systematically degrade evaluation reliability regardless of the evaluator’s reasoning capacity.

The authors use structural feature analysis to compare human-authored and LLM-generated rubrics, revealing that models produce more rigid and less necessary criteria, leading to misaligned evaluation priorities. Results show that LLM rubrics contain a higher proportion of overly strict rules that lack task relevance, weakening the correlation between constraint rigidity and intent necessity compared to human rubrics. This misalignment contributes to judgment failures, even when models generate longer rubric sets, indicating a fundamental gap in value and constraint prioritization.

The authors use RubricBench to isolate how rubric quality affects automated judge performance, finding that self-generated rubrics consistently underperform human-annotated ones across all model families. Results show that even with identical backbones and verification steps, injecting human rubrics boosts accuracy by roughly 26%, revealing rubric mis-specification—not reasoning capacity—as the dominant bottleneck. This gap persists regardless of test-time compute scaling, confirming that current models fail to autonomously induce the necessary evaluation criteria despite possessing the ability to execute them when provided.