Command Palette
Search for a command to run...
OpenAutoNLU: Open Source AutoML Library for NLU
OpenAutoNLU: Open Source AutoML Library for NLU
Grigory Arshinov Aleksandr Boriskin Sergey Senichev Ayaz Zaripov Daria Galimzianova Daniil Karpov Leonid Sanochkin
Abstract
OpenAutoNLU is an open-source automated machine learning library for natural language understanding (NLU) tasks, covering both text classification and named entity recognition (NER). Unlike existing solutions, we introduce data-aware training regime selection that requires no manual configuration from the user. The library also provides integrated data quality diagnostics, configurable out-of-distribution (OOD) detection, and large language model (LLM) features, all within a minimal lowcode API. The demo app is accessible here https://openautonlu.dev.
One-sentence Summary
Researchers from MWS AI, ITMO University, and MBZUAI present OpenAutoNLU, an open-source AutoML library for NLU tasks that automates training regime selection, integrates OOD detection and LLM features via low-code API, eliminating manual tuning while enhancing data diagnostics for text classification and NER.
Key Contributions
- OpenAutoNLU introduces a data-aware training regime selector that automatically chooses between few-shot learning (AncSetFit, SetFit) or full transformer fine-tuning based on per-class sample counts, eliminating manual configuration while adapting to dataset size and label distribution.
- The library integrates built-in data quality diagnostics—including retagging, uncertainty scoring, and V-Information analysis—and configurable OOD detection methods (e.g., Mahalanobis distance, softmax probability) tailored to each training regime, enhancing model robustness in production.
- Supporting both text classification and NER through a unified low-code API, OpenAutoNLU demonstrates competitive performance on intent classification benchmarks and includes optional LLM-powered data augmentation for low-resource scenarios.
Introduction
The authors leverage automated machine learning to simplify natural language understanding (NLU) model development for text classification and named entity recognition—tasks critical to applications like intent detection and information extraction. Prior AutoML tools for NLP often require manual configuration, lack unified interfaces, and ignore NLP-specific needs such as training regime selection based on data size or built-in data quality checks. OpenAutoNLU addresses this by introducing a data-aware training regime selector, integrated diagnostics, configurable OOD detection, and a low-code API that unifies both NLU tasks without user tuning—delivering competitive performance with minimal setup.
Dataset
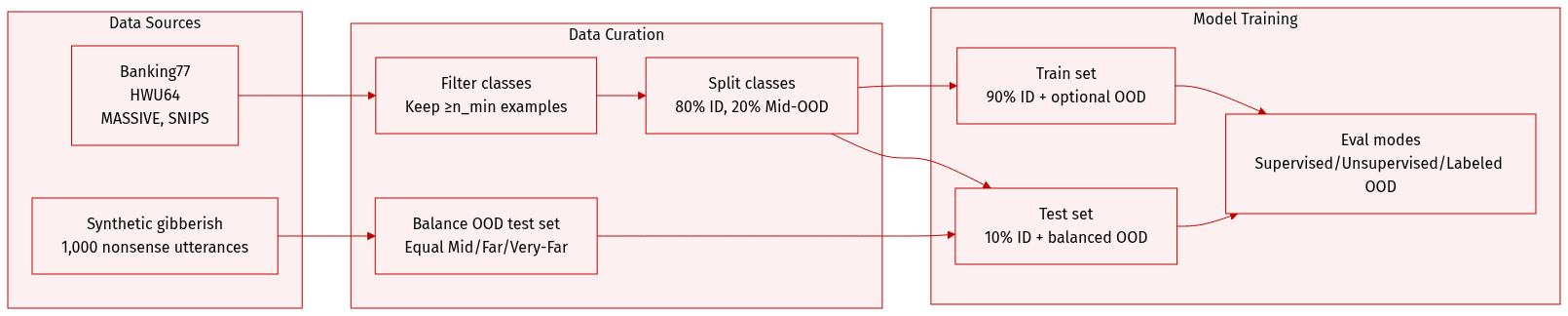
The authors use four English intent classification datasets—Banking77, HWU64, MASSIVE, and SNIPS—to evaluate OOD detection under a consistent setup. Here’s how the data is composed and processed:
-
Dataset Composition and Sources
Each dataset is split into in-distribution (ID) and out-of-distribution (OOD) subsets. OOD samples are grouped into three categories:- Mid-OOD: Held-out classes from the same dataset (20% of classes not used for training).
- Far-OOD: Samples from a semantically related but distributionally distinct dataset (e.g., Banking77 ↔ HWU64).
- Very-Far-OOD: 1,000 synthetically generated gibberish utterances to test robustness to nonsensical inputs.
-
Key Subset Details
- In-distribution: Only classes with ≥ n_min examples are retained (n_min = upper few-shot bound or 100 for full-data). 80% of qualifying classes are randomly selected as ID; within each, 90% of samples train, 10% test. In few-shot runs, per-class training samples are randomly sampled within a defined range; classes below the minimum are dropped.
- OOD Test Set: Total OOD size = 95th percentile of ID class sizes, split evenly across Mid, Far, and Very-Far-OOD.
- OOD Training Set (optional): When used, OOD volume equals half the ID training size, also split evenly across OOD types.
-
How Data Is Used in the Model
- For supervised OOD detection, OOD samples are included in training and testing.
- For unsupervised OOD (e.g., OpenAutoNLU), OOD samples appear only at test time.
- The authors also test performance when OOD is introduced as a labeled class during training.
- Evaluation metrics are reported in Table 2, with full details in Appendix D.
-
Processing and Metadata
- Thresholds (n_min = 5 and n_min = 80) were empirically chosen across multiple datasets and tasks to identify optimal transitions between training methods (AncSetFit, SetFit, full fine-tuning).
- OOD categories are uniformly balanced in the test set.
- Far-OOD sources are selected to be semantically related but domain-shifted (see Table E.1 for pairings).
Method
The authors leverage a modular, data-aware pipeline architecture in OpenAutoNLU to automate NLU model training across varying data regimes without requiring manual intervention. The system dynamically selects training strategies based on the minimum per-class sample count nmin, ensuring optimal method selection for few-shot, mid-shot, or full fine-tuning scenarios. This decision is deterministic and grounded in empirical benchmarks, eliminating the need for users to manually configure algorithms or hyperparameter grids.
At the top level, the framework exposes public pipeline classes under the auto_classes module, which inherit from abstract base classes managing the full lifecycle: data loading, preprocessing, optional data quality evaluation, method resolution, training, evaluation, and model export. The core logic resides in the methods module, which encapsulates four primary training strategies: Finetuner (for nmin>80), SetFitMethod (for 5<nmin≤80), AncSetFitMethod (for 2≤nmin≤5), and TokenClassificationFinetuner for named entity recognition tasks. Each method is paired with an OOD detection variant—Marginal Mahalanobis for fine-tuning, Maximum Softmax Probability for SetFit, and a logit-based “outOfScope” class for AncSetFit—all accessible via a single configuration flag.
Refer to the framework diagram for a visual overview of the pipeline’s modular structure and data flow. The diagram illustrates how the Data Quality module, when enabled, employs a Dynamic Tuner to generate per-sample diagnostic signals. These signals feed into four evaluators: Retag (flagging label-model disagreements), Uncertainty (identifying low-confidence predictions), V-Information (measuring learnable signal per sample), and Dataset Cartography (partitioning data into easy, ambiguous, and hard regions). For NER tasks, a Label Aggregation evaluator based on Dawid–Skene consensus estimation replaces these, detecting token-level annotation disagreements via Monte Carlo dropout.
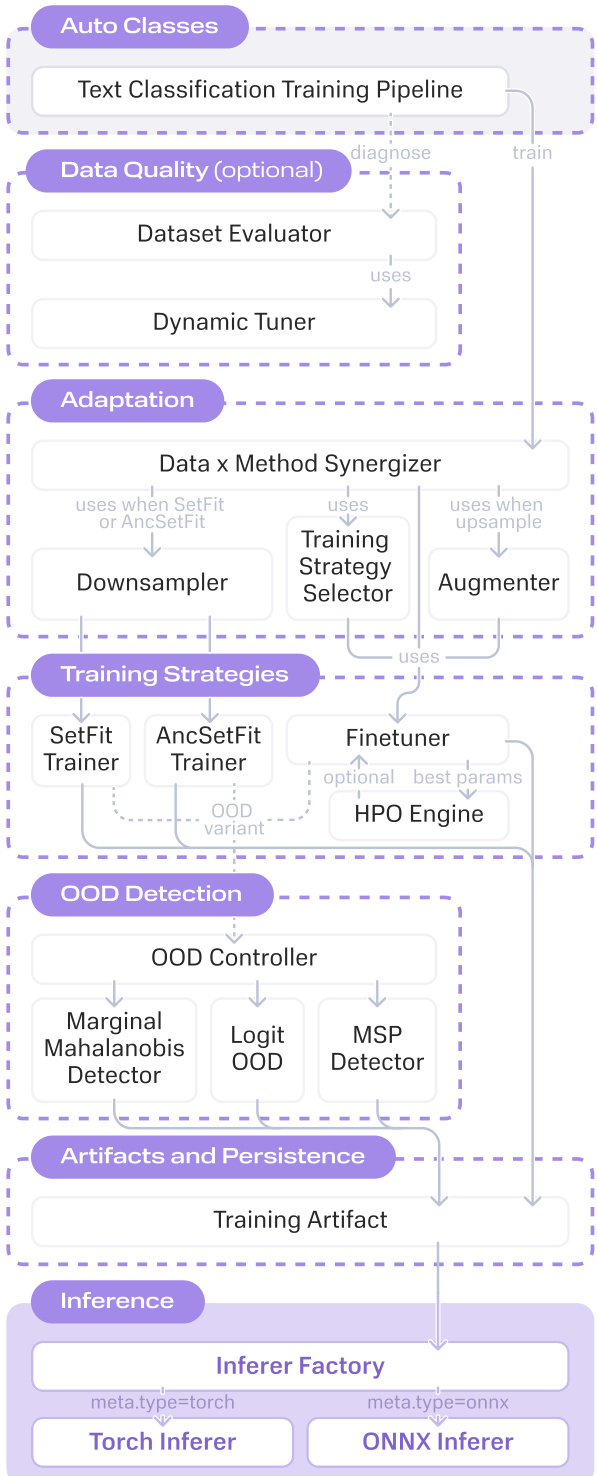
Before method selection, the pipeline performs adaptive data rebalancing. If low-resource classes (those with n≤80) exceed 30% of the dataset, underrepresented classes are upsampled to n=81 using either Augmentex-based perturbations or LLM-generated paraphrases. Conversely, when a few-shot method is selected, overrepresented classes are downsampled to the method’s ceiling (80 for SetFit, 5 for AncSetFit) to maintain training balance. This rebalancing can shift the dataset into a higher data regime, triggering a reevaluation of the optimal training strategy.
For the fine-tuning regime, hyperparameter optimization is conducted via Optuna using a Tree-structured Parzen Estimator sampler over learning rate (log-uniform in [10−6,10−3]), batch size, and weight decay, with a default budget of 10 trials and early stopping (patience = 5). In contrast, SetFit and AncSetFit use fixed, empirically tuned hyperparameters and train on the full downsampled dataset without search.
When OOD detection is enabled, the pipeline jointly optimizes the classifier and detector. Synthetic OOD samples are generated via a gibberish generator, and the detection threshold (on Mahalanobis distance or softmax probability) is tuned on validation data, adjustable via a threshold_factor parameter. Additionally, an LLM-powered test set generation module synthesizes labeled evaluation samples when no held-out test set is available, providing a reliable proxy for model quality estimation in low-resource settings.
All trained models are serialized into inference-ready packages supporting ONNX export. These packages include the ONNX graph, tokenizer files, label mapping, and a meta.json descriptor. The inference layer automatically detects available hardware (CUDA, CoreML, CPU) and performs batched inference with dynamic batch sizing to prevent out-of-memory failures.
Experiment
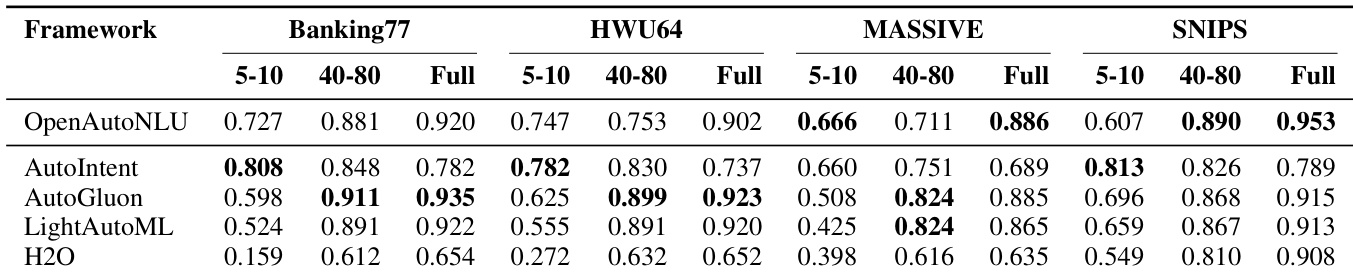
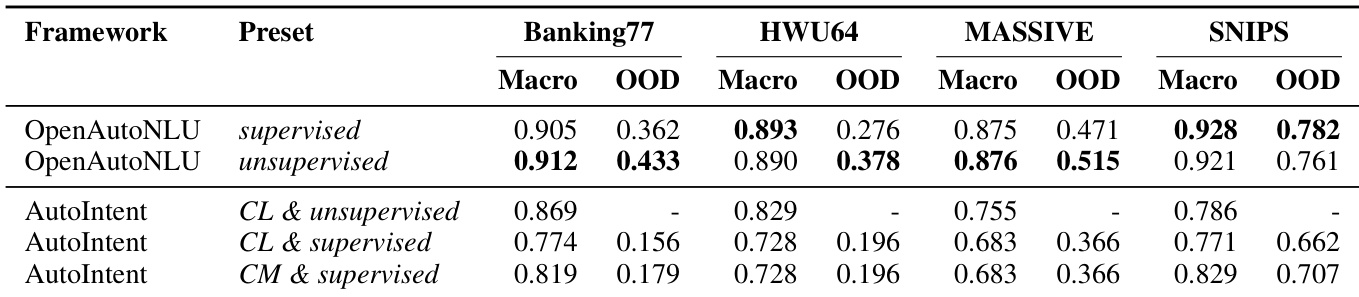
- OpenAutoNLU consistently matches or outperforms competing AutoML frameworks across multiple intent classification datasets, particularly in medium- to full-data regimes, while maintaining strong in-domain classification under realistic OOD-unaware conditions.
- AutoGluon achieves top performance on Banking77 but at significantly higher computational cost; other general-purpose frameworks (LightAutoML, H2O) lag behind, especially in low-resource settings.
- AutoIntent, though designed for intent classification, underperforms OpenAutoNLU across all datasets, with notable gaps on MASSIVE; its OOD detection requires supervised training and degrades in-domain performance.
- OpenAutoNLU’s unsupervised OOD detection performs robustly without labeled OOD data, often outperforming supervised variants; in contrast, AutoIntent cannot generate OOD predictions without supervision and suffers performance trade-offs.
- LLM-generated test sets serve as reliable proxies in some regimes but not all, indicating context-dependent validity for synthetic evaluation.
- All experiments were conducted on standardized hardware, with training times reflecting real-world deployment constraints, reinforcing OpenAutoNLU’s efficiency advantage.
OpenAutoNLU achieves the best or tied performance on three of the four evaluated datasets, demonstrating strong in-domain classification accuracy under realistic OOD-unaware conditions. While AutoGluon slightly outperforms it on Banking77, it does so at a significantly higher computational cost. AutoIntent, despite being purpose-built for intent classification, consistently underperforms across all datasets, particularly on MASSIVE.
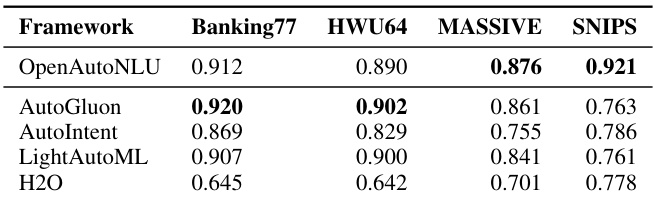
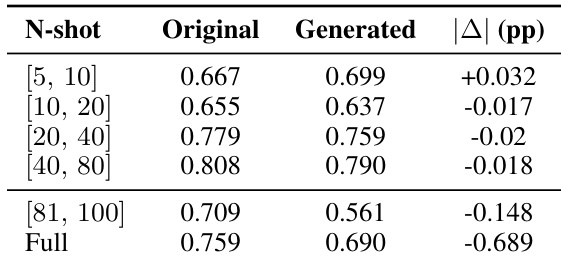
The authors evaluate classification performance using both original and LLM-generated test sets across varying data regimes, finding that generated sets closely approximate original performance in low- to medium-shot settings but diverge significantly in full-data conditions. Results indicate that LLM-generated test sets can serve as reliable proxies only when the absolute performance difference remains under 5 percentage points, which holds for smaller training sizes but not for full datasets.
OpenAutoNLU consistently outperforms AutoIntent across all datasets in both supervised and unsupervised OOD detection regimes, achieving higher macro F1 and OOD F1 scores without requiring labeled OOD data. AutoIntent’s performance degrades significantly when forced to handle OOD detection, especially in supervised mode, where it sacrifices in-domain classification accuracy. The results indicate that OpenAutoNLU’s unsupervised OOD mechanism is effective and robust, delivering strong joint classification and detection performance without additional supervision.
The authors evaluate multiple AutoML frameworks across four intent classification datasets under varying data regimes, finding that OpenAutoNLU consistently achieves top or near-top performance in full-data settings while maintaining strong results in low- and medium-shot scenarios. AutoGluon and LightAutoML show competitiveness at larger data sizes but degrade significantly in low-resource conditions, whereas AutoIntent performs best in low-shot settings but lags as training data increases. H2O consistently underperforms across all datasets and data regimes.