Command Palette
Search for a command to run...
OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
Yiying Yang Wei Cheng Sijin Chen Honghao Fu Xianfang Zeng Yujun Cai Gang Yu Xingjun Ma
Abstract
OmniLottie is a versatile framework that generates high quality vector animations from multi-modal instructions. For flexible motion and visual content control, we focus on Lottie, a light weight JSON formatting for both shapes and animation behaviors representation. However, the raw Lottie JSON files contain extensive invariant structural metadata and formatting tokens, posing significant challenges for learning vector animation generation. Therefore, we introduce a well designed Lottie tokenizer that transforms JSON files into structured sequences of commands and parameters representing shapes, animation functions and control parameters. Such tokenizer enables us to build OmniLottie upon pretrained vision language models to follow multi-modal interleaved instructions and generate high quality vector animations. To further advance research in vector animation generation, we curate MMLottie-2M, a large scale dataset of professionally designed vector animations paired with textual and visual annotations. With extensive experiments, we validate that OmniLottie can produce vivid and semantically aligned vector animations that adhere closely to multi modal human instructions.
One-sentence Summary
Fudan University, StepFun, HKU MMLab, and University of Queensland researchers propose OmniLotte, a versatile autoregressive model generating high-quality vector animations from multi-modal inputs via a novel Lotte tokenizer, overcoming JSON structural challenges and enabling precise motion control for creative design tasks.
Key Contributions
- OmniLotte is the first end-to-end framework that generates high-quality vector animations directly from multi-modal instructions by leveraging a novel tokenizer to convert Lottie’s complex JSON structure into compact, learnable command sequences.
- The framework is trained on MMLotte-2M, a large-scale dataset of two million professionally designed Lottie animations paired with text, image, and video annotations, enabling unified evaluation across text-to-, text-image-to-, and video-to-Lottie tasks.
- Experiments show OmniLotte significantly outperforms prior methods in visual fidelity and semantic alignment, delivering robust, editable vector animations that closely follow diverse multi-modal user inputs.
Introduction
The authors leverage Lottie, a widely used vector animation format encoded as JSON, to build OmniLotte—a framework that generates high-quality, editable animations from text, images, or video inputs. Prior methods either lack editability by producing raster outputs or struggle with Lottie’s rigid JSON structure, leading to low success rates and poor instruction adherence. OmniLotte overcomes this by introducing a specialized tokenizer that converts Lottie’s verbose JSON into compact command sequences, enabling efficient training on MMLotte-2M, a new dataset of 2 million annotated vector animations. This approach allows end-to-end generation while preserving the scalability and cross-platform benefits of vector graphics, significantly improving both visual fidelity and semantic alignment with multi-modal prompts.
Dataset

The authors use the MMLottie-2M dataset to train and evaluate multi-modal vector animation generation models. Here’s how the dataset is structured and processed:
-
Dataset Composition and Sources
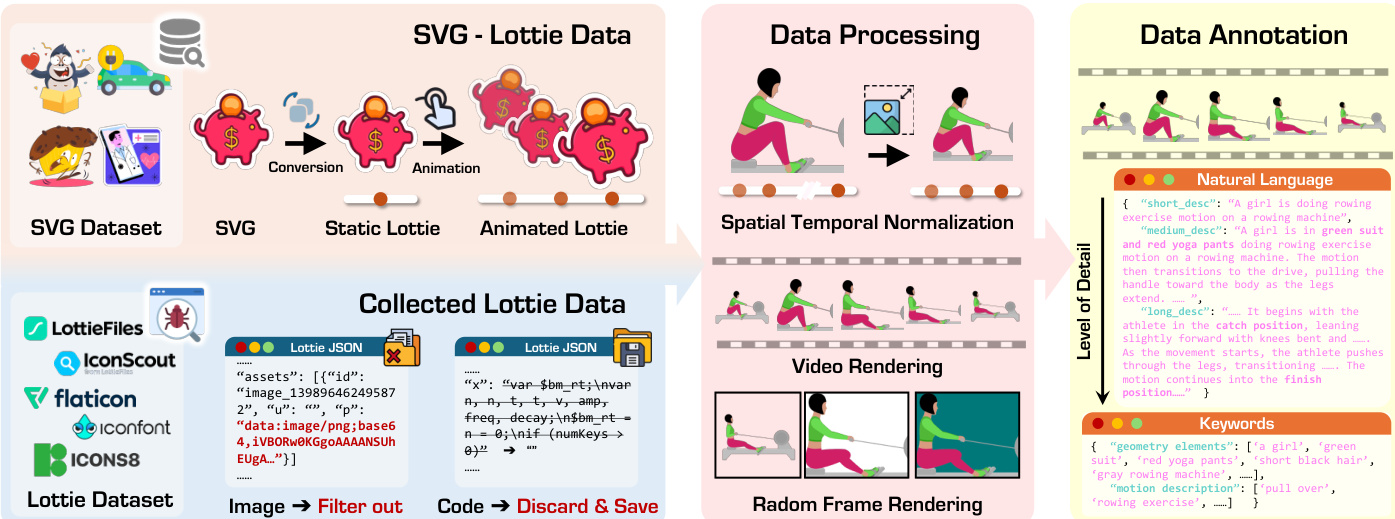
The dataset combines two primary sources: 1.2M web-crawled Lottie animations from LottieFiles, IconScout, Flaticon, Iconfont, and Icons8; and 800K synthesized animations generated from 2M static SVGs in OmniSVG, animated using procedural motions (translation, rotation, scale, opacity, etc.). -
Key Subset Details
- Web-Crawled Lottie: 1.2M files, cleaned to remove base64 images, audio/camera layers, and After Effects expressions. Retained files are fully parameterizable.
- SVG-Derived Lottie: 800K files, created by applying randomized basic motions to static SVGs. Decouples visual content from motion for better learning alignment.
- MMLottie-Bench (Evaluation): 450 real-world samples (150 per task: Text-to-Lottie, Text-Image-to-Lottie, Video-to-Lottie) + 450 synthetic samples (generated via GPT-4o, Gemini 3.1-Pro, and Seedance 1.0) to ensure fairness and avoid train-test leakage.
-
Training Use and Processing
All Lottie files undergo a 5-stage pipeline:- Collection: Aggregated from platforms and SVGs.
- Cleaning: Removed non-parameterizable elements.
- Normalization: Spatially scaled to 512×512 with center alignment; temporally normalized to 0–60 range.
- Rendering: Converted to 30fps MP4 videos with random pastel backgrounds; keyframes extracted for image tasks.
- Annotation: Used Qwen2.5-VL to generate two caption levels — concise overview (avg. 86 words) and detailed temporal description (avg. 114 words) — following strict guidelines for color, motion, and spatial detail.
-
Additional Processing Details
- Motion transfer pipeline extracts transform trajectories from 1M native files to create canonical motion templates, applied to SVG-derived animations to enrich motion diversity.
- Layer structure is flattened into tokenizable function calls for OmniLotte, extending Qwen2.5-VL with a dedicated Lottie tokenizer.
- Evaluation uses Claude-3.5-Sonnet as judge for Object and Motion Alignment, validated against human scores (Spearman ρ = 0.82 and 0.79).
- Metrics include token efficiency (via Qwen2.5-VL tokenizer) and inference time (on A100 GPU or API latency).
The dataset is provided for research only, with all rights reserved by original content owners.
Method
The authors leverage a structured, tokenization-driven framework called OmniLottie to enable multi-modal generation of vector animations from text, image, and video inputs. The core innovation lies in abstracting the verbose Lottie JSON format into a compact, semantically rich sequence of discrete tokens that can be efficiently processed by a vision-language model (VLM). This approach avoids the inefficiency of directly generating raw JSON, which contains redundant structural metadata that distracts the model from learning animation-relevant priors such as shape, motion, and temporal dynamics.
The pipeline begins with a custom Lottie Tokenizer that reorganizes the Lottie JSON into a hierarchical representation composed of base metadata and layer-specific attributes. The metadata includes global animation properties such as version (v), frame rate (fr), in-point (ip), out-point (op), width (w), height (h), name (nm), and 3D flag (ddd). Each layer is then parameterized by its type (ty ∈ {0,1,3,4,5} for Precomposition, Solid, Null, Shape, Text) and its associated attributes, including transformations (ks), effects (ef), masks (masksProperties), and text content (t). As shown in the figure below, this structured decomposition enables a lossless, tree-based representation that preserves the full generative flexibility of the original format while eliminating syntactic redundancy.
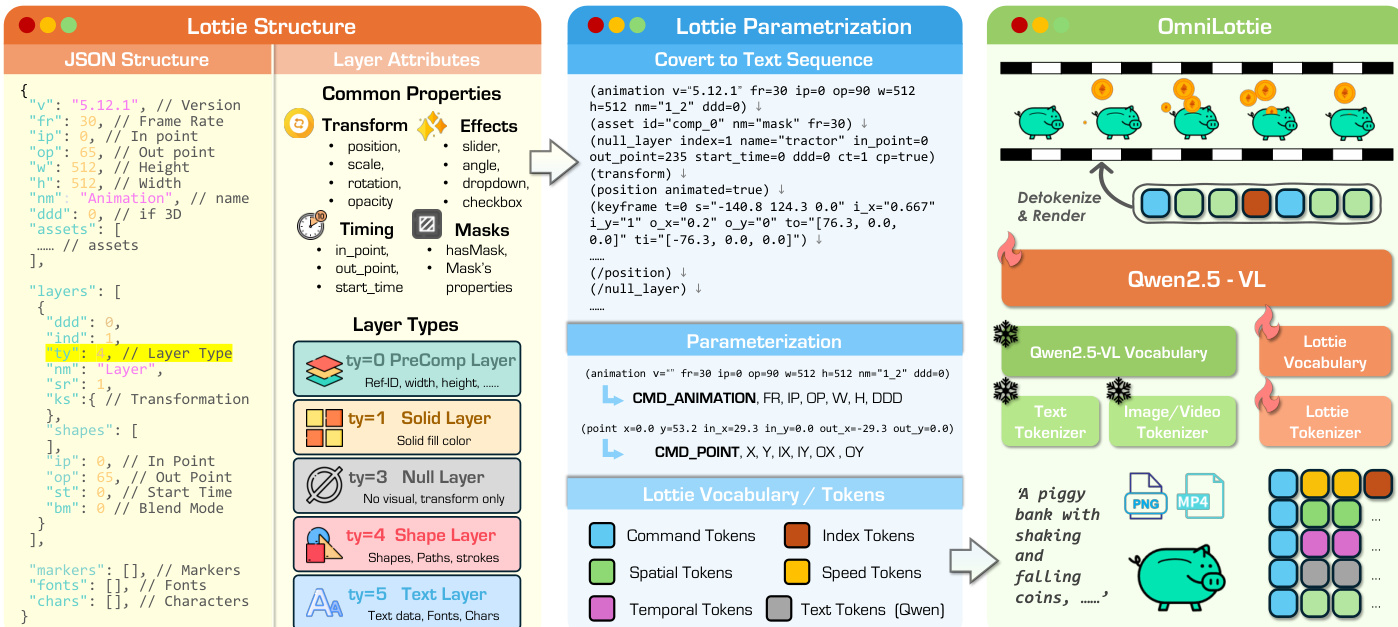
The tokenizer maps continuous parameters to discrete tokens using an offset-based quantization scheme: token(x,t)=⌊x⋅st⌋+ot, where x is the parameter value, t is its semantic type, st is a type-specific scale factor, and ot is a vocabulary offset. This ensures that each parameter category—temporal, spatial, transformation, style—occupies a non-overlapping region in the token space, preventing conflicts while preserving numerical relationships. Textual fields such as font names or character strings are handled separately using the backbone VLM’s native tokenizer (Qwen2.5-VL), encoded as a count-prefixed token sequence to preserve linguistic semantics.
The resulting token sequence is fed into a pre-trained VLM backbone, Qwen2.5-VL, which has been extended with a custom Lottie vocabulary. The model is trained to auto-regressively generate Lottie tokens conditioned on multi-modal instructions (text, image, video) using standard cross-entropy loss: θ∗=argminθ−∑i=1LlogP(xs[i]∣xc;xs<i;θ). During inference, the generated token sequence is detokenized back into a valid Lottie JSON file through a deterministic inverse transformation, ensuring full reconstruction fidelity.
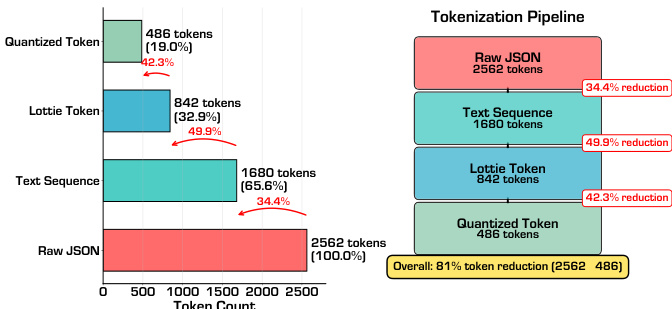
The tokenization pipeline achieves significant compression: as illustrated in the figure below, raw Lottie JSON (2,562 tokens on average) is reduced to 486 tokens—a 81% reduction—by first converting to a structured text sequence (1,680 tokens), then to a command-parameter format (842 tokens), and finally to quantized tokens. This efficiency allows the model to focus its capacity on learning animation semantics rather than formatting syntax.
For data annotation, the authors render Lottie animations into videos and use a VLM to generate multi-level descriptions: a coarse overall caption followed by finer temporal details using cues like “begins with” and “then.” Keywords emphasizing geometry and motion are highlighted to improve text-following accuracy. For text-image-to-Lottie, a single frame is selected and the VLM is prompted to focus on foreground object motion. For video-to-Lottie, the rendered video itself serves as the multi-modal instruction, simplifying annotation. As shown in the figure below, this enables three generation modalities: text-to-Lottie, text-image-to-Lottie, and video-to-Lottie, each producing vector animations that match the input specification.
The model architecture integrates the Qwen2.5-VL backbone with a custom Lottie tokenizer and vocabulary, enabling seamless processing of interleaved multi-modal inputs. The tokenization design adheres to principles of separation of concerns, vocabulary efficiency, reconstruction guarantees, and model compatibility, ensuring that the discrete representation does not compromise the vector nature of the output. During detokenization, numerical parameters are recovered via p=sttoken−ot, and text content is decoded using the pretrained tokenizer, preserving semantic consistency. The final output is a renderable Lottie JSON file that maintains resolution independence, editability, and full vector fidelity.
Experiment
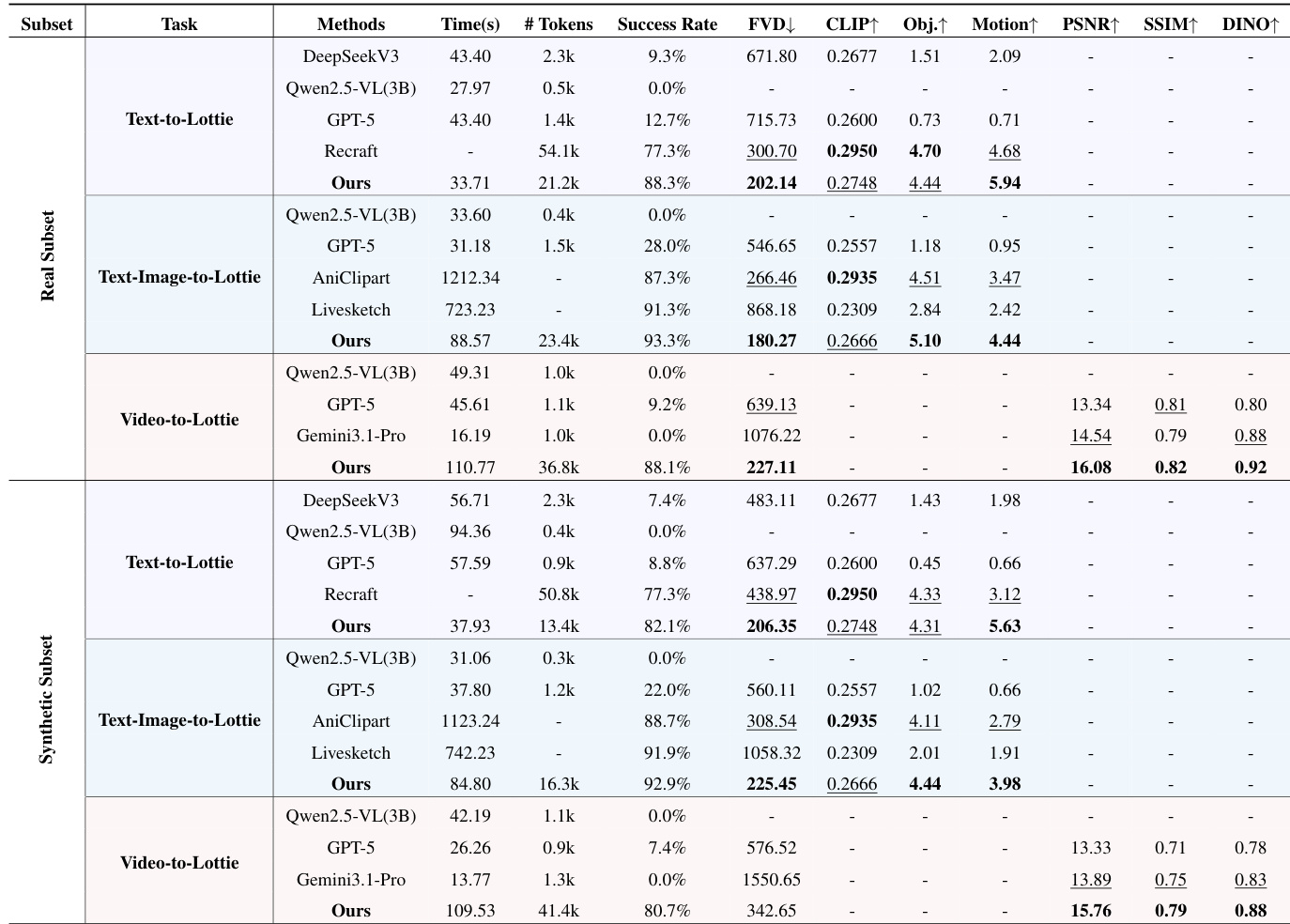
- OmniLotte outperforms all baselines across Text-to-Lottie, Text-Image-to-Lottie, and Video-to-Lottie tasks, achieving superior visual quality, motion fidelity, and semantic alignment.
- Qualitative results confirm OmniLotte generates more accurate, expressive, and visually coherent animations compared to commercial tools and LLM/VLM baselines, which suffer from structural errors, motion misalignment, or low success rates.
- Ablation studies show that moderate mixing of SVG and Lottie data optimizes geometric richness and motion complexity, while the custom Lottie tokenizer significantly boosts generation quality and efficiency.
- Failure analysis reveals OmniLotte’s errors are mostly rendering-level (e.g., missing styles, temporal misalignment), whereas baselines fail at specification or input dependency levels, making OmniLotte more reliable and practical.
- User studies validate OmniLotte’s dominance in human-rated dimensions—visual quality, condition adherence, animation smoothness, and geometric fidelity—with automated metrics (Object and Motion Alignment) strongly correlating with human judgments.
- OmniLotte delivers high success rates (90.7–97.3%) and drastically lower generation time per successful output (31s) compared to optimization-based methods, offering a 52x–530x speedup.
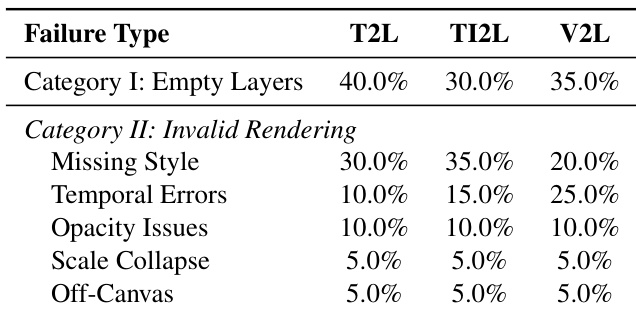
The authors analyze failure modes across Text-to-Lottie, Text-Image-to-Lottie, and Video-to-Lottie tasks, finding that empty layer generation is the most common structural failure, while rendering issues like missing style attributes and temporal errors dominate invalid outputs. Results show Video-to-Lottie is most prone to temporal errors, while Text-Image-to-Lottie exhibits higher rates of style-related failures, reflecting task-specific challenges in aligning visual and textual inputs.
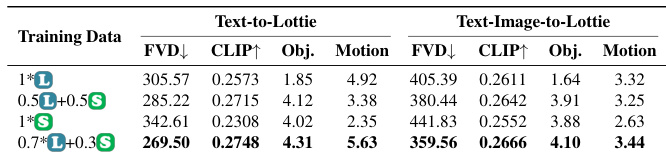
The authors evaluate different training data compositions for OmniLotte, finding that a mix of 70% Lottie and 30% SVG data yields the best performance across both Text-to-Lottie and Text-Image-to-Lottie tasks. This balanced approach improves object and motion alignment while maintaining visual quality, as measured by FVD and CLIP scores. Results indicate that moderate SVG integration enhances geometric understanding without compromising motion complexity.
The authors use automated metrics like Object Alignment and Motion Alignment to evaluate generated animations, and these metrics show strong positive correlation with human judgments across geometric fidelity and animation quality. Results indicate that their proposed metrics are more effective than CLIP or FVD at capturing human-perceived quality, validating their use for automated evaluation.

The authors use OmniLotte to generate Lottie animations from text, text-image, and video inputs, comparing it against multiple baselines including commercial tools and large language models. Results show OmniLotte consistently achieves the highest success rates and outperforms others on key metrics like FVD, object alignment, and motion alignment, while maintaining efficient generation speed. Its structured tokenizer and targeted training enable reliable, high-fidelity vector animation output across all input modalities.
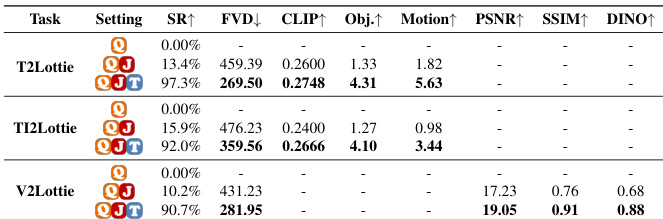
The authors use OmniLotte to generate Lottie animations from text, text-image, and video inputs, consistently outperforming baselines across success rates, visual quality, and motion alignment. Results show that OmniLotte achieves the highest scores in most metrics, particularly in motion fidelity and token efficiency, while maintaining strong performance on both real and synthetic data. The method also demonstrates superior reliability and speed compared to optimization-based and general-purpose VLM approaches.