Command Palette
Search for a command to run...
Density-Guided Response Optimization: Community-Grounded Alignment via Implicit Acceptance Signals
Density-Guided Response Optimization: Community-Grounded Alignment via Implicit Acceptance Signals
Patrick Gerard Svitlana Volkova
Abstract
Language models deployed in online communities must adapt to norms that vary across social, cultural, and domain-specific contexts. Prior alignment approaches rely on explicit preference supervision or predefined principles, which are effective for well-resourced settings but exclude most online communities -- particularly those without institutional backing, annotation infrastructure, or organized around sensitive topics -- where preference elicitation is costly, ethically fraught, or culturally misaligned. We observe that communities already express preferences implicitly through what content they accept, engage with, and allow to persist. We show that this acceptance behavior induces measurable geometric structure in representation space: accepted responses occupy coherent, high-density regions that reflect community-specific norms, while rejected content falls in sparser or misaligned areas. We operationalize this structure as an implicit preference signal for alignment and introduce density-guided response optimization (DGRO), a method that aligns language models to community norms without requiring explicit preference labels. Using labeled preference data, we demonstrate that local density recovers pairwise community judgments, indicating that geometric structure encodes meaningful preference signal. We then apply DGRO in annotation-scarce settings across diverse communities spanning platform, topic, and language. DGRO-aligned models consistently produce responses preferred by human annotators, domain experts, and model-based judges over supervised and prompt-based baselines. We position DGRO as a practical alignment alternative for communities where explicit preference supervision is unavailable or misaligned with situated practices, and discuss the implications and risks of learning from emergent acceptance behavior.
One-sentence Summary
Patrick Gerard (USC) and Svitlana Volkova (Aptima) propose DGRO, a method that aligns language models to community norms using implicit acceptance signals—modeling locally dense regions in representation space where accepted content clusters—enabling alignment without explicit preference labels, particularly useful for sensitive or annotation-scarce online communities.
Key Contributions
- We demonstrate that community acceptance behavior—such as content persistence and engagement—induces measurable, high-density regions in embedding space that encode implicit preference signals, enabling alignment without explicit annotations.
- We introduce Density-Guided Response Optimization (DGRO), a method that leverages local density in representation space to align language models to community norms, validated across diverse, annotation-scarce settings including sensitive and non-English forums.
- DGRO-aligned models outperform supervised and prompt-based baselines in human and model-based evaluations, while we explicitly frame the approach as descriptive and caution against uncritical deployment due to risks of bias amplification and exclusion.
Introduction
The authors leverage community behavior—what content gets accepted, engaged with, or allowed to persist—as an implicit signal for aligning language models to context-specific norms, bypassing the need for costly or ethically fraught preference annotations. Prior methods like RLHF and DPO rely on explicit human feedback, which excludes many online communities lacking institutional support or facing cultural sensitivities. DGRO instead models accepted responses as forming high-density regions in embedding space, treating local density as a proxy for preference. Their key contribution is a practical, annotation-free alignment method that matches or outperforms supervised baselines across diverse, annotation-scarce communities, while explicitly framing the approach as descriptive—not normative—to avoid amplifying harmful or exclusionary norms.
Dataset

-
The authors use the Stanford Human Preferences (SHP) benchmark, which provides pairwise preference judgments from five distinct Reddit communities: changemyview, askkulinary, askhistorians, legaladvice, and explainlikeimfive. These communities were selected for their divergent moderation styles, interaction norms, and response evaluation criteria, enabling tests of whether preference structure generalizes across heterogeneous settings.
-
Each data instance includes a conversation history (prompt), a preferred response, and a non-preferred response, as determined by community voting. Metadata includes the normalized upvote ratio between responses, serving as a proxy for preference strength. Dataset sizes per community are detailed in Appendix Table 4.
-
For testing the manifold hypothesis, the authors embed all training responses using a fixed sentence encoder to build an unlabeled reference pool. Preference labels are not used during embedding or density estimation. Test prompts are evaluated by ranking candidate responses based on their estimated local density under the community distribution, using the 150 nearest training histories for conditioning.
-
The model, called “acceptance density,” computes pairwise margins between preferred and non-preferred responses and reports accuracy as the probability that the margin is positive. Performance is compared against baselines: random assignment, kNN with majority vote, global density estimation, and the original supervised SHP reward model (used as an upper bound).
-
All data is publicly available, handled in compliance with platform terms and CSS research norms. No individual identification was attempted; analysis focused on aggregate community patterns. The authors emphasize that DGRO models descriptive norms, not prescriptive values, and caution against deployment without oversight, transparency, and domain-specific safeguards.
Method
The authors leverage a novel approach called Density-Guided Response Optimization (DGRO) to derive implicit preference signals from community-accepted responses without relying on explicit human annotations. Rather than using pairwise preference labels as in traditional alignment methods like RLHF or DPO, DGRO interprets the distribution of accepted responses in embedding space as a proxy for community norms. Specifically, responses embedded in higher-density regions of this space are treated as more aligned with community expectations, enabling the construction of synthetic preferred/dispreferred pairs for training.
To operationalize this concept, the authors adopt a context-conditioned local density estimation strategy. For a given query context h, they first identify its k nearest neighbors in the embedding space using a kNN search over historical contexts. The corresponding accepted responses from these neighbors form a context-specific reference set B(h). Acceptance density for a candidate response x is then estimated via a kernel density estimator:
logp(x∣h,c)∝log∣B(h)∣1j∈B(h)∑Kσ(x,xj),where Kσ denotes an RBF kernel with bandwidth determined by the median heuristic. This formulation ensures that preference signals are locally calibrated—responses are evaluated relative to what the community accepts in semantically similar contexts, rather than against a global, potentially misleading aggregate distribution.
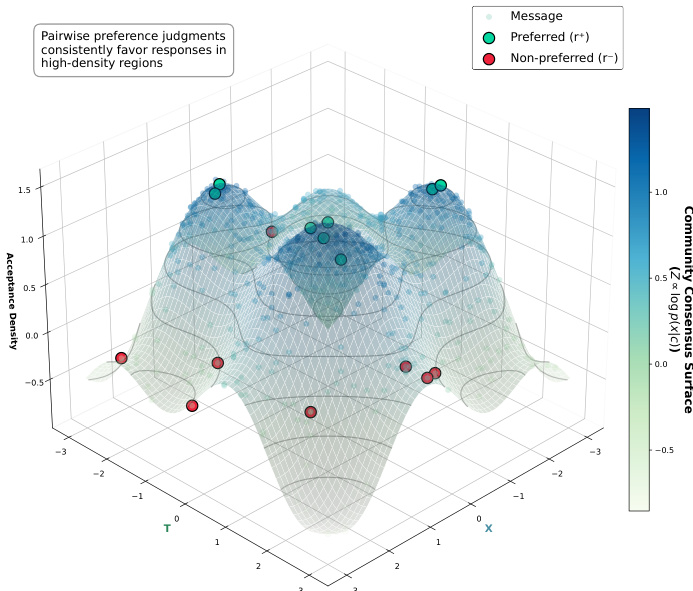
As shown in the figure below, this local density estimation enables DGRO to adaptively model community norms across diverse topics and intents, preserving fine-grained preference structure that global density estimation would otherwise obscure.
Experiment
- Validated the manifold hypothesis: local acceptance density in representation space reliably recovers human preference signals, especially where community consensus is strong, outperforming global density and kNN baselines.
- Demonstrated that acceptance density can substitute explicit preference labels in standard optimization objectives, achieving performance close to supervised reward models without labeled data.
- Successfully applied density-guided response optimization (DGRO) in annotation-scarce, high-stakes communities (e.g., eating disorder support, conflict documentation), where it consistently outperformed baselines like SFT and ICL in producing authentic, contextually appropriate responses.
- Confirmed that LLM-based evaluation aligns with human expert judgments in sensitive domains, enabling scalable validation without compromising reliability.
- Showed DGRO’s robustness across model architectures and embedding choices, with performance largely independent of base model or embedding type.
- Identified a key limitation: when candidate responses fall entirely outside the local acceptance manifold, density-based rankings become arbitrary and uninformative.
The authors use local acceptance density to recover human preference signals from community discourse without explicit annotations, finding it consistently outperforms unsupervised baselines and approaches supervised model performance. Results show that preference recovery improves with stronger human agreement, indicating that local geometric structure in representation space encodes meaningful community norms. This supports the use of density-guided optimization as a viable alternative to labeled preference data in alignment tasks.

The authors use local acceptance density to recover human preference signals from community discourse without explicit annotations, achieving performance close to supervised models in high-agreement contexts. Results show that preference alignment improves with stronger community consensus, indicating that local geometric structure in representation space encodes meaningful normative distinctions. In annotation-scarce domains like eating disorder and conflict documentation communities, density-guided optimization consistently outperforms standard fine-tuning and in-context learning, producing responses that better match authentic community norms in both relevance and tone.
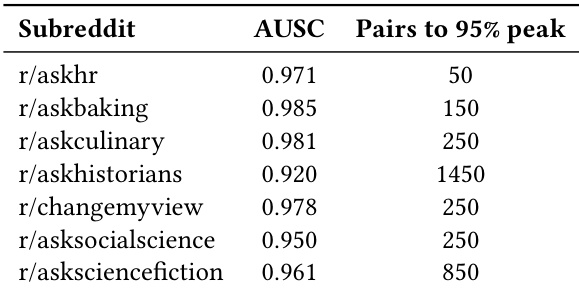
The authors evaluate how different embedding models affect the performance of local acceptance density in recovering community preferences across multiple subreddits. Results show that while performance varies slightly by subreddit, the choice of embedding model has minimal impact on overall accuracy, with all tested models achieving comparable results within narrow confidence intervals. This suggests the method’s robustness to embedding architecture under the evaluated conditions.

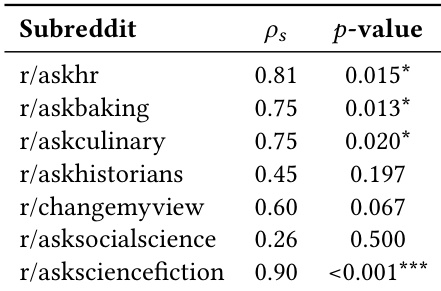
The authors find that local acceptance density reliably recovers human preference signals in community discourse, with performance strongly tied to the strength of human agreement within each subreddit. Communities exhibiting higher consensus, such as r/asksciencefiction and r/askhr, show the strongest correlations between density-based rankings and human judgments, suggesting that preference structure becomes more recoverable as norms solidify. This pattern supports the hypothesis that local geometric structure in representation space encodes meaningful preference information, particularly where community norms are well-defined.
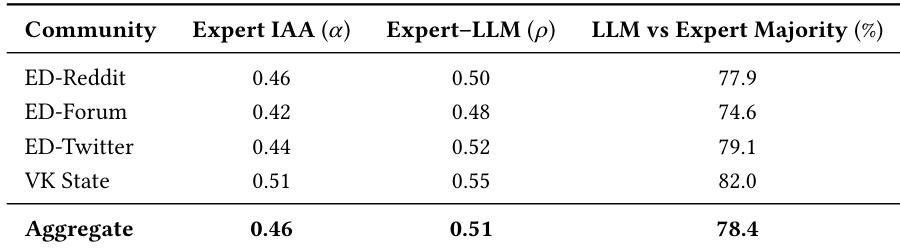
The authors use expert evaluations to validate that LLM-based judgments align with human preferences in annotation-scarce domains, showing moderate inter-annotator agreement and strong rank correlation between experts and LLMs. Aggregate LLM judgments match expert majority decisions in 78.4% of cases, supporting their use as a scalable proxy for human evaluation. This reliability enables large-scale assessment of model alignment where explicit preference labels are unavailable.