Command Palette
Search for a command to run...
HoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations
HoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations
Xiaomeng Xu Jisang Park Han Zhang Eric Cousineau Aditya Bhat Jose Barreiros Dian Wang Shuran Song
Abstract
We present Whole-Body Mobile Manipulation Interface (HoMMI), a data collection and policy learning framework that learns whole-body mobile manipulation directly from robot-free human demonstrations. We augment UMI interfaces with egocentric sensing to capture the global context required for mobile manipulation, enabling portable, robot-free, and scalable data collection. However, naively incorporating egocentric sensing introduces a larger human-to-robot embodiment gap in both observation and action spaces, making policy transfer difficult. We explicitly bridge this gap with a cross-embodiment hand-eye policy design, including an embodiment agnostic visual representation; a relaxed head action representation; and a whole-body controller that realizes hand-eye trajectories through coordinated whole-body motion under robot-specific physical constraints. Together, these enable long-horizon mobile manipulation tasks requiring bimanual and whole-body coordination, navigation, and active perception. Results are best viewed on: https://hommi-robot.github.io
One-sentence Summary
Stanford University and Toyota Research Institute researchers introduce HoMMI, a framework enabling whole-body mobile manipulation learned directly from robot-free human demos via egocentric sensing; it bridges embodiment gaps using 3D visual representations and look-at point actions, achieving precise bimanual coordination, navigation, and active perception on real robots.
Key Contributions
- HoMMI enables scalable whole-body mobile manipulation learning from robot-free human demonstrations by augmenting UMI with egocentric sensing, capturing global context for navigation and bimanual coordination while avoiding costly teleoperation.
- To bridge the human-robot embodiment gap, it introduces embodiment-agnostic 3D visual representations and a relaxed “3D look-at point” head action space, allowing transfer of active perception strategies to robots with differing morphology and neck constraints.
- The system integrates a constraint-aware whole-body controller that coordinates base, torso, and arm motions to track end-effector trajectories under physical limits, achieving precise, long-horizon manipulation tasks in large, real-world environments.
Introduction
The authors leverage human demonstrations to learn whole-body mobile manipulation without requiring robot teleoperation, addressing a key bottleneck in scaling robot learning for real-world tasks. Prior systems using handheld interfaces like UMI lack global context due to wrist-centric sensing, while egocentric approaches introduce large embodiment gaps in both visual and kinematic domains—often requiring additional robot data or restricting tasks to fixed bases. HoMMI overcomes this by combining an egocentric head-mounted camera with a redesigned policy architecture: it uses embodiment-agnostic 3D visual representations to handle viewpoint mismatches, a relaxed “look-at point” action space to accommodate differing neck kinematics, and a constraint-aware whole-body controller that translates hand-eye trajectories into feasible, coordinated robot motions. This enables direct transfer of complex, long-horizon mobile manipulation skills—including navigation, bimanual coordination, and active perception—from human demonstrations to real robots.
Dataset
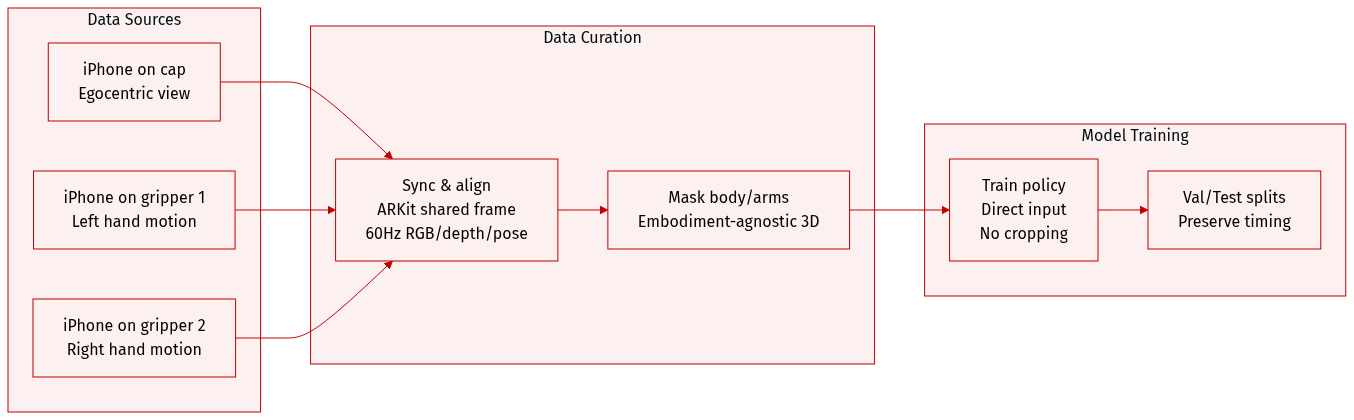
- The authors use a custom data collection interface built around three iPhones: two mounted on grippers and one on a cap, enabling egocentric, bimanual mobile manipulation demonstrations without robots.
- Data includes synchronized RGB video, depth maps, 6-DoF poses, and gripper widths recorded at 60Hz per device, all aligned via Apple’s ARKit multi-device collaboration for a shared coordinate frame.
- The system avoids VR-induced motion sickness by offering direct visual and haptic feedback, making it lightweight and intuitive for operators.
- Observations are processed into an embodiment-agnostic 3D visual representation, masking out body and arm-specific elements to generalize across embodiments.
- This multimodal trajectory data is directly fed into the policy learning pipeline without additional preprocessing or cropping, preserving temporal and spatial alignment.
Method
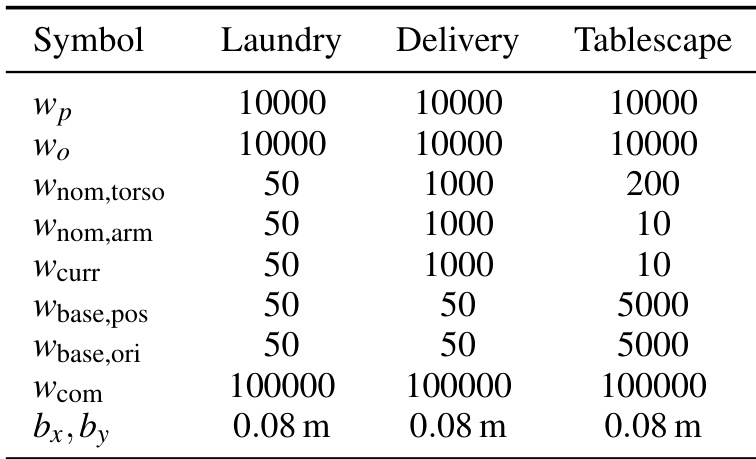
The authors leverage a cross-embodiment hand-eye policy architecture designed to bridge the visual, kinematic, and spatial gaps between human demonstrators and the target mobile manipulator. The system operates on a diffusion-based policy trained end-to-end, conditioned on a short observation window Ot=ot−To+1,…,ot and predicting a horizon of actions At=at+1,…,at+Tp. To ensure transferability, the policy integrates three core algorithmic innovations: a 3D visual representation, a 3D look-at point action representation, and a gripper-centric spatial frame.
Refer to the framework diagram, which illustrates the full pipeline from data collection through policy inference to robot deployment. The policy ingests multimodal observations including head and wrist RGB images, depth-derived pointmaps, and proprioception. These are processed through embodiment-agnostic visual encoders before being fused into a global embedding that conditions the Diffusion Transformer (DiT) backbone. The policy outputs a 23-dimensional action vector comprising bimanual end-effector poses (each 9D: 3D position + 6D orientation via rotation matrix columns), a 3D look-at point, and gripper widths.
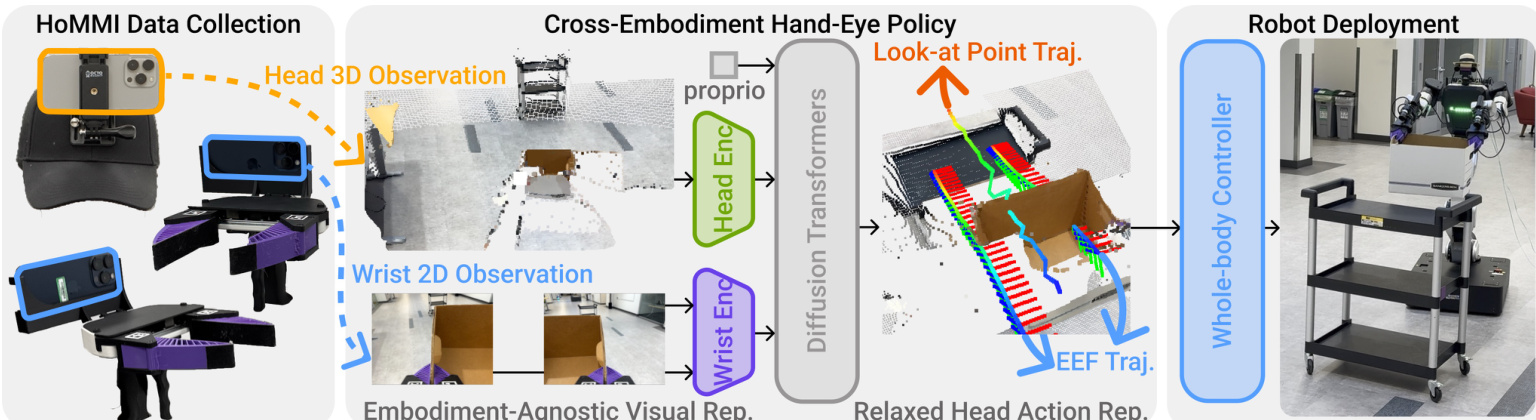
The 3D visual representation mitigates the visual gap by lifting egocentric head camera observations into 3D space. For each frame, a pointmap is generated (via iPhone depth or stereo estimation), patchified into 16×16 regions, and downsampled to 512 tokens. Each patch is encoded with a DINO-v3 ViT feature, then augmented with a sinusoidal encoding of its 3D position. To reduce appearance mismatch, arm points are masked out by transforming the pointmap into the left/right gripper frame and discarding points with z<0. An attention pooling layer aggregates these geometry-aware tokens into a head observation embedding Fego. Wrist images are processed via a shared DINO-v3 ViT encoder, resized to 224×224, and represented by the CLS token Fwrist. Proprioception is concatenated to form the full observation embedding.
As shown in the figure below, the 3D head observation is anchored in the gripper frame, with arm points masked and positional encoding applied to tie appearance to geometry.
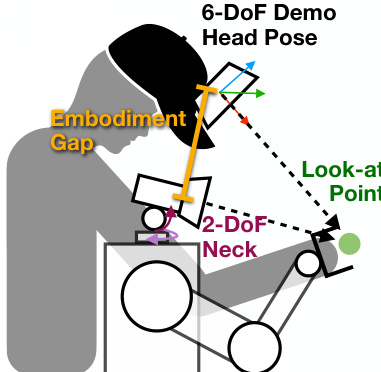
To address the kinematic gap, the policy does not output 6-DoF head poses but instead predicts a 3D look-at point ℓt∈R3. This relaxed representation preserves the intent of active perception while respecting the robot’s 2-DoF neck constraints. During training, ℓt is computed as the intersection of the head camera ray with the scene pointmap. At inference, the head controller converts ℓt into a feasible orientation by constructing a rotation matrix Rt=[x^ty^td^t], where d^t=∥ℓt−ct∥ℓt−ct is the unit vector from current head position ct to the look-at point, x^t is the normalized projection of the current x-axis onto the plane orthogonal to d^t, and y^t=d^t×x^t. If the projection is near zero, a world-up vector is used to ensure numerical stability.
The figure below illustrates how the 3D look-at point decouples perception intent from kinematic constraints, enabling the robot to achieve task-relevant gaze without mimicking human head poses exactly.
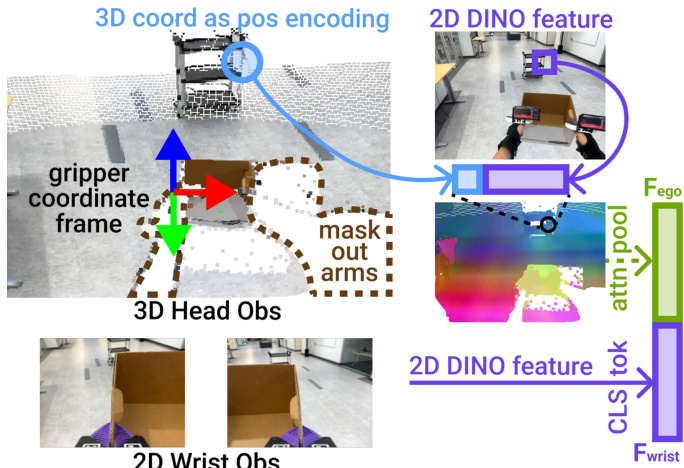
All observations and actions are expressed in a gripper-centric frame to maintain spatial consistency. Head pointmaps, look-at points, and gripper poses are transformed into the left-gripper frame, anchoring the policy’s reasoning to the manipulators executing the task. This mitigates drift caused by embodiment differences in head height, neck DoF, and camera placement.
The policy is implemented using Diffusion Policy with a DiT backbone, conditioned on global observation embeddings and trained to predict noise via a DDIM scheduler. The model uses 768-dimensional embeddings, 10 layers, 12 attention heads, and RMS normalization. Observations are downsampled to 20 Hz with To=2 and Tp=32. Actions are 23D: 9D per gripper (3D position + 6D orientation), 3D look-at point, and 2D gripper widths. Training employs AdamW with a cosine learning rate schedule, weight decay 1×10−6, and 500 epochs.
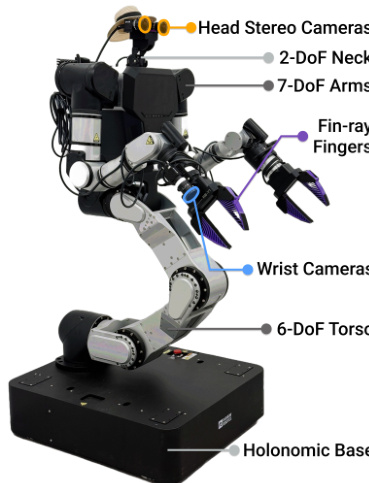
The hardware platform is a Rainbow Robotics RB-Y1 bimanual mobile manipulator with a 6-DoF torso, two 7-DoF arms, a 2-DoF neck, and a holonomic base. Custom fin-ray fingers match the UMI grippers used in data collection. Head-mounted stereo cameras and wrist-mounted RGB cameras provide egocentric and wrist views. The sensing stack uses GigE cameras connected via PoE switches and 10 Gbps fiber links to an external workstation running policy inference and control.
As shown in the hardware schematic, the robot integrates head stereo cameras, 2-DoF neck, 7-DoF arms with wrist cameras, fin-ray fingers, and a 6-DoF torso mounted on a holonomic base.
The whole-body controller translates policy outputs into joint velocities using a differential IK solver based on Mink. The solver minimizes an objective function f(Δq)=Cee+Cnominal+Ccurrent+Ccom, subject to constraints on configuration, joint velocity, base velocity, collision avoidance, and upright posture. The bimanual SE(3) tracking cost Cee prioritizes end-effector accuracy, while Cnominal regularizes toward a human-like posture, Ccurrent ensures smooth motion, and Ccom maintains center-of-mass over the base. The solver runs asynchronously at 100Hz, interpolating policy commands (issued at 10Hz) to provide continuous targets to the 500Hz robot control loop. Temporal interpolation blends position linearly and orientation via spherical linear interpolation to eliminate motion jitter.
The system employs asynchronous policy inference to avoid pausing for computation. A detached policy server receives timestamped, latency-corrected observations, performs inference, and returns timestamped action chunks. A real-time execution bridge synchronizes sensor streams, discards stale actions, and streams time-aligned targets to the whole-body controller, ensuring seamless integration between perception, policy, and control.
Experiment
- HoMMI successfully transfers policies from human demonstrations to a robot with different embodiment, validating cross-embodiment learning for long-horizon bimanual mobile manipulation.
- The system excels in whole-body coordination, long-horizon navigation, and active perception, outperforming all baselines across laundry, delivery, and tablescape tasks.
- Wrist-only sensing fails to capture global context, leading to navigation and alignment errors; head-only sensing lacks local contact cues, causing grasping failures.
- Naively adding egocentric RGB degrades performance due to embodiment mismatch and kinematic infeasibility, while HoMMI’s 3D egocentric representation and look-at point control resolve these issues.
- Active head control is critical for gathering task-relevant visual information and maintaining observability, significantly boosting success rates when enabled.
- HoMMI’s joint use of wrist and head views enables cleaner, task-focused attention, improving robustness and reducing out-of-distribution sensitivity.
The authors use a cross-embodiment hand-eye policy that integrates wrist and head camera inputs to enable long-horizon bimanual mobile manipulation, achieving high success rates across diverse tasks by combining local contact cues with global scene context. Results show that active head control and 3D egocentric representation are critical for robust navigation and object interaction, while baselines relying solely on wrist or head views fail due to limited observability or embodiment mismatch. Disabling active perception or omitting wrist inputs significantly reduces performance, confirming that coordinated multi-view sensing and adaptive viewpoint control are essential for reliable real-world deployment.