Command Palette
Search for a command to run...
T2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
T2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
Abstract
Think about how human handles complex reading tasks: marking key points, inferring their relationships, and structuring information to guide understanding and responses. Likewise, can a large language model benefit from text structure to enhance text-processing performance? To explore it, in this work, we first introduce Structure of Thought (SoT), a prompting technique that explicitly guides models to construct intermediate text structures, consistently boosting performance across eight tasks and three model families. Building upon this insight, we present T2S-Bench, the first benchmark designed to evaluate and improve text-to-structure capabilities of models. T2S-Bench includes 1.8K samples across 6 scientific domains and 32 structural types, rigorously constructed to ensure accuracy, fairness, and quality. Evaluation on 45 mainstream models reveals substantial improvement potential: the average accuracy on the multi-hop reasoning task is only 52.1%, and even the most advanced model achieves 58.1% node accuracy in end-to-end extraction. Furthermore, on Qwen2.5-7B-Instruct, SoT alone yields an average +5.7% improvement across eight diverse text-processing tasks, and fine-tuning on T2S-Bench further increases this gain to +8.6%. These results highlight the value of explicit text structuring and the complementary contributions of SoT and T2S-Bench. Dataset and eval code have been released at https://t2s-bench.github.io/T2S-Bench-Page/.
One-sentence Summary
Researchers from Duke University, UT Austin, and Meta propose Structure of Thought, a prompting technique that guides models to build intermediate text structures, alongside T2S-Bench, the first benchmark for text-to-structure capabilities, which significantly boosts performance across diverse scientific domains and reasoning tasks.
Key Contributions
- Current large language models struggle with complex text processing due to a lack of stable intermediate representations, prompting the need for a universal approach to structure information before generating answers.
- The authors introduce Structure of Thought (SoT), a prompting technique that guides models to construct intermediate text structures, and T2S-Bench, the first benchmark containing 1.8K samples across six scientific domains to evaluate these capabilities.
- Evaluations on 45 mainstream models reveal significant performance gaps, while experiments show that SoT alone improves accuracy by 5.7% and fine-tuning on the new benchmark further increases gains to 8.6% across diverse tasks.
Introduction
Large language models are increasingly deployed in critical workflows like scientific literature review and evidence-based decision making, yet they often struggle with complex, long-context tasks because they rely on unstable end-to-end generation without stable intermediate representations. Prior attempts to improve performance through structured reasoning or task-specific extraction modules have failed to generalize across diverse text types and lack a unified evaluation framework. To address these gaps, the authors introduce Structure of Thought, a prompting technique that guides models to explicitly construct intermediate text structures before answering, and T2S-Bench, the first comprehensive benchmark designed to evaluate and enhance text-to-structure capabilities across multiple scientific domains.
Dataset
T2S-Bench Dataset Overview
The authors introduce T2S-Bench, a comprehensive dataset designed to evaluate and train models on text-to-structure capabilities using high-quality academic sources. The construction process addresses verification challenges by leveraging rigorously validated scientific diagrams and their corresponding texts.
-
Dataset Composition and Sources
- The primary data source consists of academic papers across six major scientific domains: Computer Science, Life Sciences, Social Sciences, Environmental Sciences, Economics & Management Sciences, and Physical Sciences.
- The dataset covers 17 sub-disciplines and 32 distinct structural types, ensuring broad topical diversity.
- All text-structure pairs are derived from real-world diagrams that have been meticulously designed by authors and validated by peer reviewers.
-
Key Details for Each Subset
- T2S-Bench-MR (Multi-hop Reasoning): Contains approximately 1,700 high-quality text-structure-question triples. Each entry includes a text segment, a reference diagram, and a multiple-choice question requiring multi-step reasoning. Questions are categorized into four types: Fault Localization, Functional Mapping, Boundary Testing, and Counterfactual Reasoning.
- T2S-Bench-E2E (End-to-End Extraction): Comprises 87 rigorously vetted Text-KeyStructure pairs. This subset focuses on extracting key nodes and links while filtering noise, with graph complexity controlled to ensure fair evaluation.
- T2S-Train: A training split of 1,200 instruction-answer pairs derived from the collected data, used for fine-tuning structure-aware models.
-
Data Usage and Processing
- Construction Pipeline: The authors employ a four-module automated pipeline involving paper search, PDF download, figure cropping, and structural validity checks using advanced models like GPT-5.2 and Gemini-2.5-Pro.
- Human Verification: Three rounds of human filtering by PhD-level experts ensure quality. The first round removes noisy diagrams, the second validates question solvability and logic, and the third confirms the alignment between text and key structures.
- Split Strategy: The final benchmark uses a stratified 7:3 split by domain. The test set (T2S-Bench-MR) contains 500 samples for multiple-choice evaluation, while the E2E set remains separate for structure extraction tasks.
- Evaluation Metrics: The authors use Exact Match (EM) and F1 scores for multiple-choice tasks. For E2E tasks, they evaluate node extraction via average semantic similarity and link extraction via F1 scores on predicted link pairs.
-
Cropping and Metadata Details
- Figure Cropping: Figures are extracted from PDFs using
pdffigures2and validated by GPT-4o to confirm structural relevance before further processing. - Text Segmentation: The pipeline ensures that at least three text segments correspond clearly to each structural diagram, with start and end sentences explicitly identified.
- Partial Constraint Strategy: To handle the one-to-many mapping problem in E2E tasks, the authors evaluate nodes and links separately. Models are provided with either all node information to predict links or all link information to predict nodes, standardizing outputs for accurate assessment.
- Figure Cropping: Figures are extracted from PDFs using
Method
The authors propose a systematic pipeline for constructing the T2S (Text-to-Structure) dataset, which is designed to evaluate multi-hop reasoning capabilities over structural diagrams. The overall workflow, depicted in the framework diagram, consists of three main phases: Sample Collection, T2S Multi-hop Reasoning Dataset Construction, and T2S-Bench-E2E Construction.
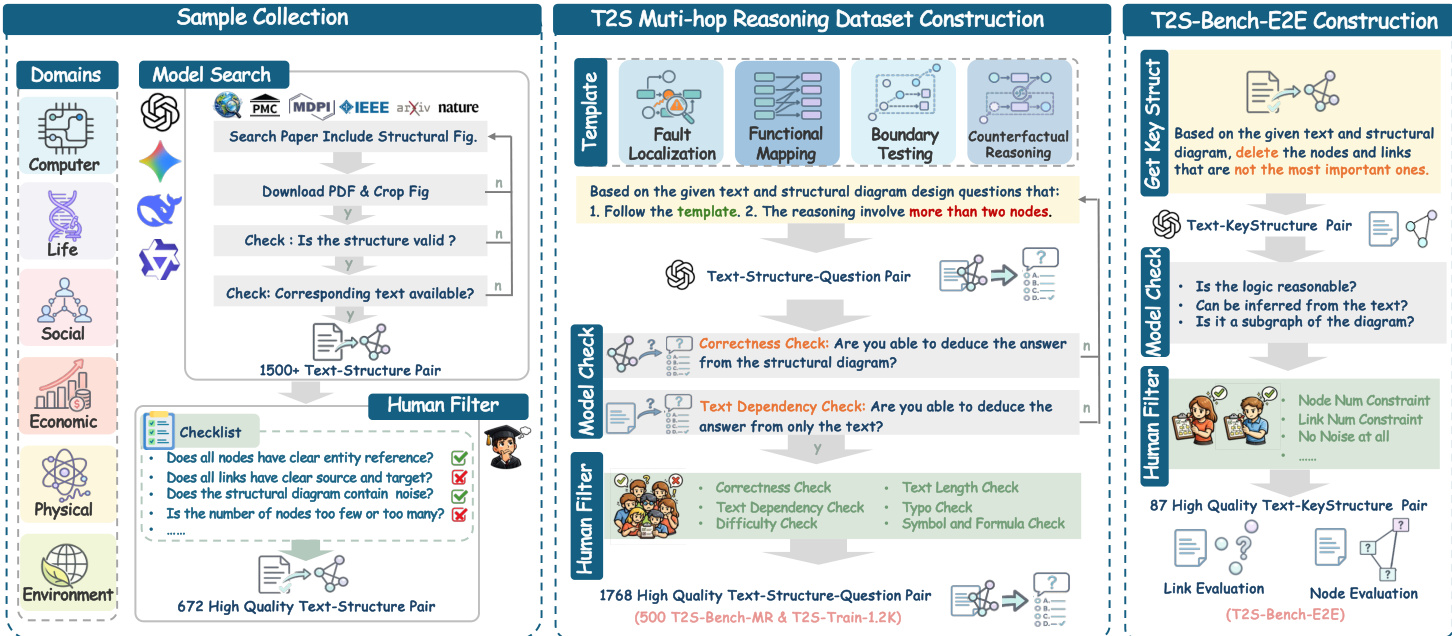
During the Sample Collection phase, the system searches for academic papers across diverse domains including Computer, Life, and Social sciences. It identifies structural figures, downloads the corresponding PDFs, and performs automated validity checks to ensure the diagrams can be represented as connected node-link graphs. A human filter is subsequently applied to verify entity references and diagram quality, resulting in a curated set of high-quality text-structure pairs.
The dataset construction phase relies on a template-based approach to generate reasoning questions. As shown in the figure below:
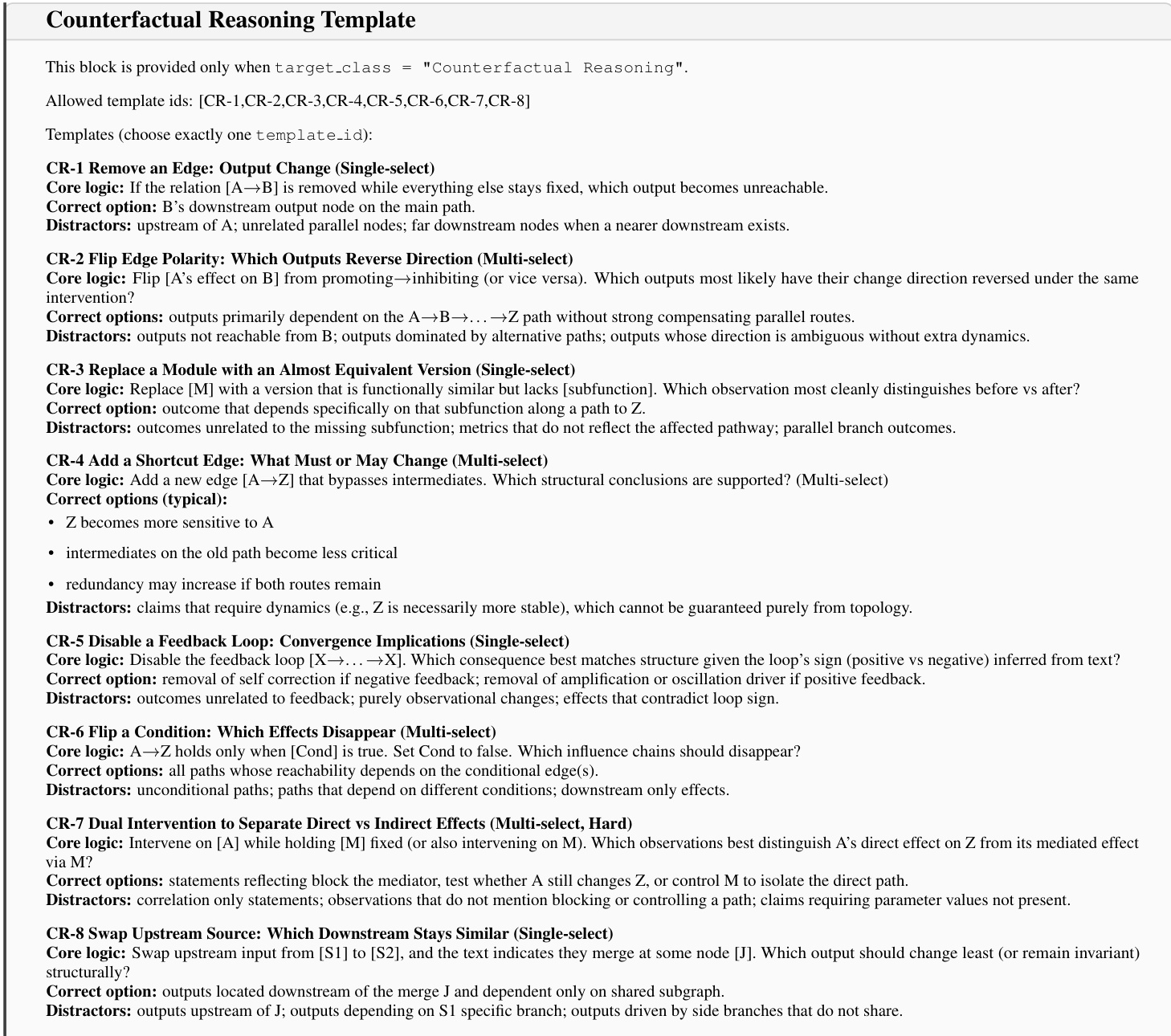 The authors define a specific set of Counterfactual Reasoning templates, labeled CR-1 through CR-8, which guide the generation of questions involving operations such as removing edges, flipping polarity, or disabling feedback loops. Similar templates are utilized for Fault Localization and Functional Mapping tasks. These templates ensure that the generated questions require multi-step structural reasoning rather than simple information retrieval.
The authors define a specific set of Counterfactual Reasoning templates, labeled CR-1 through CR-8, which guide the generation of questions involving operations such as removing edges, flipping polarity, or disabling feedback loops. Similar templates are utilized for Fault Localization and Functional Mapping tasks. These templates ensure that the generated questions require multi-step structural reasoning rather than simple information retrieval.
To execute these complex tasks, the system employs an LLM-based architecture with advanced memory management capabilities. Refer to the system architecture diagram for the detailed component layout.
 The architecture features a Function Executor that interacts with Archival Storage and a Queue Manager that handles a FIFO Queue for prompt tokens. This design allows the system to maintain context and manage long-running processes such as paper search and schema normalization. The pipeline incorporates strict quality control steps, including Model Checks for correctness and text dependency, followed by a Human Filter to ensure node and link constraints are met.
The architecture features a Function Executor that interacts with Archival Storage and a Queue Manager that handles a FIFO Queue for prompt tokens. This design allows the system to maintain context and manage long-running processes such as paper search and schema normalization. The pipeline incorporates strict quality control steps, including Model Checks for correctness and text dependency, followed by a Human Filter to ensure node and link constraints are met.
Finally, the evaluation process utilizes specific prompt contracts for API models. The system enforces a strict output schema for multiple-choice QA and employs two-stage prompts for structure evaluation: one for node labeling and another for link extraction. This ensures robust parsing of the model's responses during benchmarking.
Experiment
- The Structure of Thought (SoT) prompting strategy was evaluated against Direct Answer and Chain of Thought methods, validating that explicitly forcing models to structure text into nodes and links significantly improves performance across diverse text-processing tasks and model families.
- Benchmarking 45 models on T2S-Bench revealed that while proprietary models currently lead, instruction-tuned open-source models are rapidly closing the gap, though all models struggle most with identifying correct nodes compared to linking them.
- Fine-tuning experiments demonstrated that enhancing a model's ability to extract text structures directly translates to improved performance on downstream long-context reasoning tasks, confirming that structural understanding is a fundamental prerequisite for effective multi-hop reasoning.
- Analysis of structural complexity showed that model accuracy declines sharply as the number of nodes in a graph increases, indicating that current systems lack the scalability to handle highly complex structural relationships.
- Correlation studies confirmed a strong positive relationship between a model's ability to perform text-to-structure extraction and its general long-context reasoning capabilities, suggesting that structural thinking is a universal indicator of reasoning proficiency.