Command Palette
Search for a command to run...
Lost in Stories: Consistency Bugs in Long Story Generation by LLMs
Lost in Stories: Consistency Bugs in Long Story Generation by LLMs
Junjie Li Xinrui Guo Yuhao Wu Roy Ka-Wei Lee Hongzhi Li Yutao Xie
Abstract
What happens when a storyteller forgets its own story? Large Language Models (LLMs) can now generate narratives spanning tens of thousands of words, but they often fail to maintain consistency throughout. When generating long-form narratives, these models can contradict their own established facts, character traits, and world rules. Existing story generation benchmarks focus mainly on plot quality and fluency, leaving consistency errors largely unexplored. To address this gap, we present ConStory-Bench, a benchmark designed to evaluate narrative consistency in long-form story generation. It contains 2,000 prompts across four task scenarios and defines a taxonomy of five error categories with 19 fine-grained subtypes. We also develop ConStory-Checker, an automated pipeline that detects contradictions and grounds each judgment in explicit textual evidence. Evaluating a range of LLMs through five research questions, we find that consistency errors show clear tendencies: they are most common in factual and temporal dimensions, tend to appear around the middle of narratives, occur in text segments with higher token-level entropy, and certain error types tend to co-occur. These findings can inform future efforts to improve consistency in long-form narrative generation. Our project page is available at https://picrew.github.io/constory-bench.github.io/.
One-sentence Summary
Researchers from Microsoft and the Singapore University of Technology and Design introduce ConStory-Bench, a new benchmark with an automated checker to evaluate narrative consistency in long-form story generation, revealing that factual and temporal errors frequently occur mid-narrative to guide future model improvements.
Key Contributions
- Existing story generation benchmarks overlook consistency errors in long-form narratives, prompting the creation of ConStory-Bench with 2,000 prompts and a taxonomy of five error categories containing 19 fine-grained subtypes.
- The authors introduce CONSTORY-CHECKER, an automated pipeline that detects contradictions across narratives while grounding every judgment in explicit textual evidence through exact quotations.
- Systematic evaluations of diverse LLMs reveal that consistency errors are most frequent in factual and temporal dimensions, tend to emerge in the middle of stories, and correlate with higher token-level entropy.
Introduction
Long-form narrative generation is increasingly vital for content creation and educational authoring, yet large language models often fail to maintain consistency across thousands of tokens by contradicting established facts, character traits, or world rules. Prior work has largely focused on plot quality and fluency while neglecting systematic evaluation of global consistency, and existing automated judges typically lack explicit textual evidence to support their assessments. To address these gaps, the authors introduce ConStory-Bench, a comprehensive benchmark with 2,000 prompts and a detailed error taxonomy, alongside CONSTORY-CHECKER, an automated pipeline that detects contradictions and grounds every judgment in exact textual quotations.
Dataset
-
Dataset Composition and Sources The authors construct ConStory-Bench by aggregating seed stories from seven diverse public corpora: LONGBENCH, LONGBENCH_WRITE, LONGLAMP, TELLMEASTORY, WRITINGBENCH, WRITINGPROMPTS, and WIKIPLOTS. These sources provide both creative writing queries and full-length narratives to serve as the foundation for the benchmark.
-
Key Details for Each Subset The final dataset consists of 2,000 high-quality prompts distributed across four distinct task types designed to test specific narrative challenges:
- Generation: Produces free-form narratives from minimal plot setups.
- Continuation: Extends initial story fragments into complete narratives while preserving established facts.
- Expansion: Develops long-form stories from concise plot outlines by elaborating on implicit details.
- Completion: Writes full stories with predefined beginnings and endings, filling in the intervening plot. Each prompt is constrained to a target generation length of 8,000–10,000 words.
-
Data Usage and Processing The authors utilize the entire set of 2,000 prompts for evaluation rather than training, having models generate outputs for all task scenarios under comparable settings. The data processing pipeline involves:
- LLM Rewriting: Using the o4-mini model to convert collected stories into task-specific prompts grounded in authentic narrative elements.
- Deduplication: Applying MinHash-based techniques to remove near-duplicate prompts.
- Quality Control: Filtering out low-quality or trivial cases through a combination of manual inspection and automated heuristics.
-
Metadata and Error Taxonomy To enable systematic evaluation, the authors developed a hierarchical consistency error taxonomy comprising five top-level categories and 19 fine-grained error types. This framework covers contradictions in timeline and plot logic, characterization, world-building rules, factual details, and narrative style. The benchmark employs an LLM-as-judge pipeline to detect these errors and classify them into the defined categories.
Method
The authors introduce ConStory-Checker, an automated LLM-as-judge pipeline designed for scalable and auditable consistency evaluation in long-form narrative generation. The system operates through a structured four-stage process that transforms raw story text into quantified consistency metrics.
Refer to the framework diagram for an overview of the entire pipeline, which encompasses long story generation, consistency analysis, and weighted scoring.
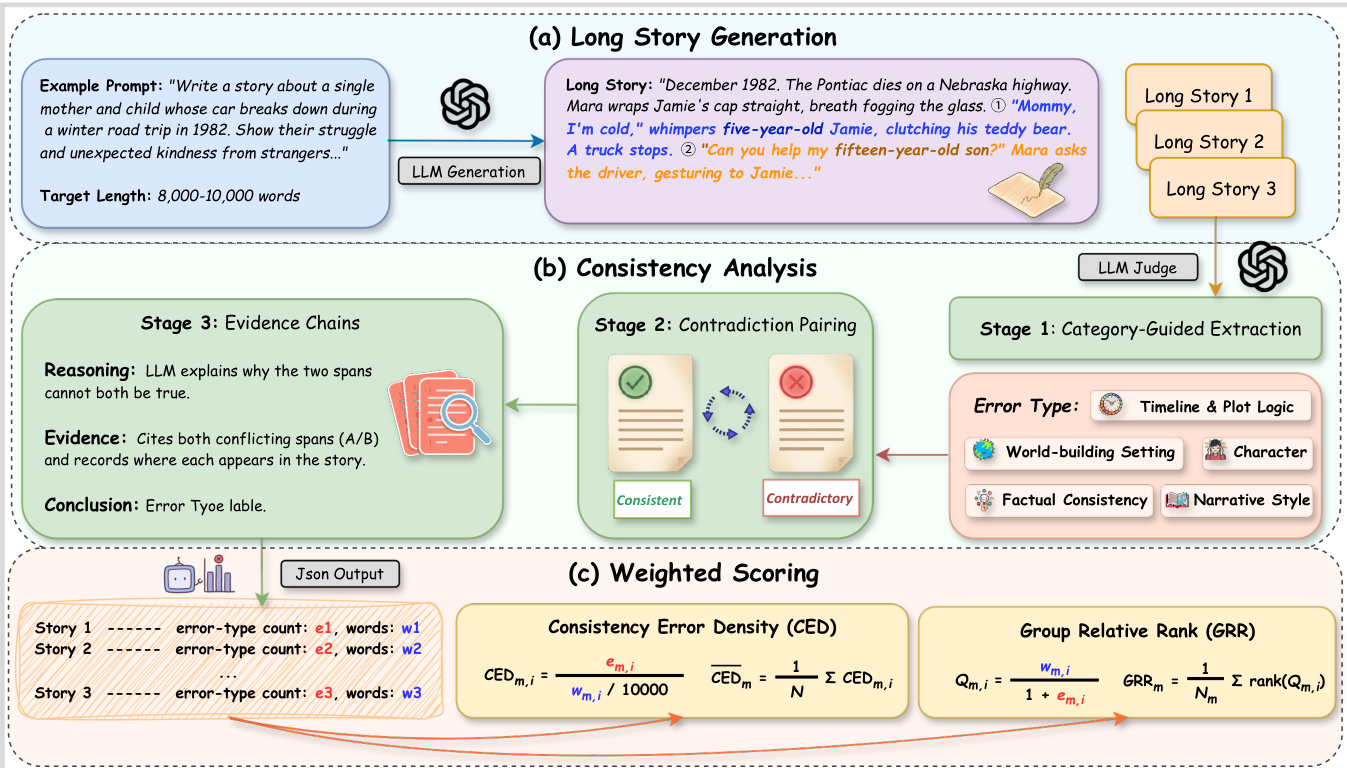
The consistency analysis phase is divided into three core stages. Stage 1 involves Category-Guided Extraction, where narratives are scanned using specific prompts across five dimensions: Timeline & Plot Logic, Characterization, World-building & Setting, Factual & Detail Consistency, and Narrative Style. This stage extracts contradiction-prone spans based on detailed taxonomies.
As shown in the figure below, the Timeline & Plot Logic category focuses on extracting sentences with conflicting calendar information, duration contradictions, simultaneity issues, and causal logic violations.

Similarly, the Characterization category targets memory contradictions, knowledge inconsistencies, and skill fluctuations within the narrative.

The World-building & Setting category evaluates core rules violations, social norms, and geographical contradictions to ensure the internal logic of the story world remains stable.

Finally, the Factual & Detail Consistency category addresses appearance mismatches, nomenclature confusions, and quantitative mismatches to verify specific details.

Following extraction, Stage 2 performs Contradiction Pairing, where extracted spans are compared pairwise and classified as Consistent or Contradictory to reduce false positives. Stage 3 generates Evidence Chains, recording the reasoning, specific evidence quotes with positions, and the conclusion for each identified error. The output is standardized into JSON reports in Stage 4, capturing quotations, positions, pairings, and error categories anchored to precise character-level offsets.
To evaluate performance, the authors employ two complementary metrics to address length bias and prompt difficulty. First, Consistency Error Density (CED) normalizes errors by output length, measuring errors per ten thousand words for model m on story i:
CEDm,i=wm.i/10000em,i
where em,i denotes the error count and wm,i the word count. Model-level scores are averaged over all stories. Second, to control for instance-level difficulty, the Group Relative Rank (GRR) ranks models within each prompt group. For each story i, a length-aware quality score Qm,i is defined as:
Qm,i=1+em.iwm,i
Models are ranked by Qm,i within the same story, and the GRR is computed as:
GRRm=Nm1∑i∈Imranki(Qm,i)
This framework allows for a robust comparison of narrative consistency across different models and generation strategies.
Experiment
- Evaluation across proprietary, open-source, capability-enhanced, and agentic systems using ConStory-Bench and ConStory-Checker confirms that current large language models systematically produce narrative inconsistencies, particularly in factual tracking and temporal reasoning.
- Analysis of output length reveals that consistency errors accumulate linearly as story length increases, though models vary significantly in their generation preferences, creating diverse trade-offs between narrative completeness and error density.
- Investigation into error origins demonstrates that consistency failures occur in regions of high model uncertainty, where token-level entropy and perplexity are elevated, suggesting these metrics can serve as reliable early-warning signals for triggering verification routines.
- Correlation studies show that factual and detail errors act as a central hub, frequently co-occurring with characterization and world-building mistakes, while narrative and style inconsistencies arise independently through distinct mechanisms.
- Positional analysis indicates that errors are not uniformly distributed; facts are typically established in the early-to-mid narrative while contradictions emerge later, with temporal and geographical errors exhibiting large gaps that require robust long-range memory, whereas perspective confusions stem from local context failures.
- Task type evaluation highlights that open-ended story generation poses the greatest consistency challenge compared to continuation or completion tasks.