Command Palette
Search for a command to run...
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Kangsan Kim Yanlai Yang Suji Kim Woongyeong Yeo Youngwan Lee Mengye Ren Sung Ju Hwang
Abstract
As embodied models become powerful, humans will collaborate with multiple embodied AI agents at their workplace or home in the future. To ensure better communication between human users and the multi-agent system, it is crucial to interpret incoming information from agents in parallel and refer to the appropriate context for each query. Existing challenges include effectively compressing and communicating high volumes of individual sensory inputs in the form of video and correctly aggregating multiple egocentric videos to construct system-level memory. In this work, we first formally define a novel problem of understanding multiple long-horizon egocentric videos simultaneously collected from embodied agents. To facilitate research in this direction, we introduce MultiAgent-EgoQA (MA-EgoQA), a benchmark designed to systemically evaluate existing models in our scenario. MA-EgoQA provides 1.7k questions unique to multiple egocentric streams, spanning five categories: social interaction, task coordination, theory-of-mind, temporal reasoning, and environmental interaction. We further propose a simple baseline model for MA-EgoQA named EgoMAS, which leverages shared memory across embodied agents and agent-wise dynamic retrieval. Through comprehensive evaluation across diverse baselines and EgoMAS on MA-EgoQA, we find that current approaches are unable to effectively handle multiple egocentric streams, highlighting the need for future advances in system-level understanding across the agents. The code and benchmark are available at https://ma-egoqa.github.io.
One-sentence Summary
Researchers from KAIST, New York University, and collaborators introduce MA-EgoQA, a benchmark for answering questions across multiple long-horizon egocentric video streams, alongside EgoMAS, a baseline using shared memory and dynamic retrieval to outperform existing models in complex multi-agent scenarios.
Key Contributions
- The paper addresses the critical challenge of interpreting parallel sensory inputs from multiple embodied agents to enable effective human-AI communication and system-level memory aggregation.
- It introduces MultiAgent-EgoQA, a new benchmark featuring 1.7k questions across five categories like social interaction and temporal reasoning, derived from long-horizon egocentric video streams.
- The authors propose EgoMAS, a baseline model using shared memory and dynamic retrieval that outperforms existing approaches by 4.48% and demonstrates the limitations of current video LLMs on this task.
Introduction
As embodied AI agents become common in shared environments like homes and workplaces, the ability for humans to query these multi-agent systems for progress monitoring or anomaly detection is critical for transparency and control. Prior research has largely focused on task allocation and action execution, leaving a significant gap in systems that can integrate long-horizon egocentric video streams from multiple agents to answer complex questions. Existing video models struggle with the massive data volume generated over days and fail to effectively aggregate experiences across different agents to form a coherent system-level memory. To address this, the authors introduce MA-EgoQA, a new benchmark featuring 1.7k questions across five reasoning categories derived from six agents operating over seven days. They also propose EgoMAS, a baseline model that utilizes shared memory and agent-wise dynamic retrieval to efficiently locate relevant events, demonstrating that current state-of-the-art models cannot yet handle the complexities of multi-agent egocentric understanding.
Dataset
MA-EgoQA Dataset Overview
-
Dataset Composition and Sources The authors construct MA-EgoQA using the EgoLife dataset, which consists of super-long egocentric video recordings from six individuals wearing camera-equipped glasses over seven consecutive days in a shared house. This foundation allows the benchmark to evaluate reasoning across multiple, temporally aligned video streams rather than relying on single-agent assumptions found in prior work.
-
Key Details for Each Subset The benchmark contains 1,741 high-quality multiple-choice questions distributed across five distinct categories designed to capture unique multi-agent dynamics:
- Social Interaction (SI): Evaluates grounding of conversations and affiliative behaviors, including 15.9k generated single-span and multi-span samples.
- Task Coordination (TC): Focuses on role assignment and goal completion, featuring 16.3k multi-span samples alongside single-span variants.
- Theory of Mind (ToM): Assesses reasoning about the mental states, beliefs, and intentions of others.
- Temporal Reasoning (TR): Divided into concurrency and comparison subcategories to test timeline alignment across agents.
- Environmental Interaction (EI): Tracks object usage and environmental state changes distributed among agents.
-
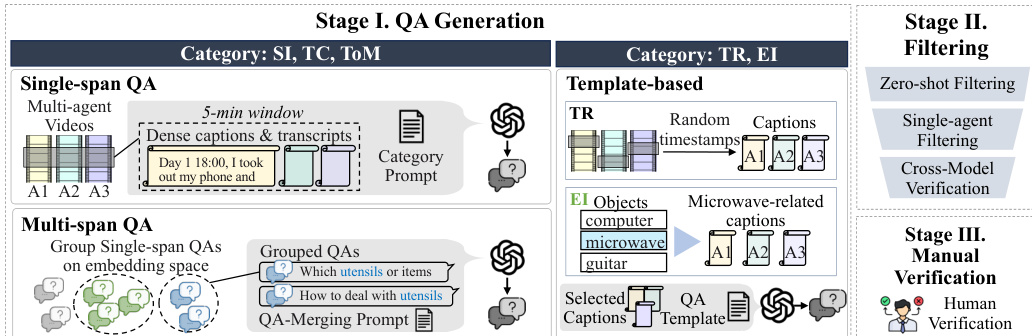
Data Usage and Generation Strategy The authors employ a hybrid generation pipeline to create the dataset, utilizing GPT-4o and GPT-5 for candidate creation followed by rigorous filtering.
- Open-ended Categories (SI, TC, ToM): The team generates large pools of samples by providing 5-minute video segments with dense captions and transcripts to the model, instructing it to create questions grounded by at least two agents.
- Structured Categories (TR, EI): The authors use predefined templates and specific temporal windows (30 seconds to 1 hour) to generate queries regarding event ordering and object interaction frequency.
- Multi-span Construction: For SI and TC, the authors group semantically similar single-span questions using cosine similarity on text embeddings to synthesize complex questions requiring reasoning across non-contiguous time windows.
-
Processing and Quality Control To ensure the benchmark is challenging and strictly multi-agent, the authors implement a multi-stage filtering and verification process:
- LLM Filtering: Candidates undergo zero-shot testing to remove trivial questions and single-agent filtering to eliminate samples answerable by one person's memory.
- Cross-model Validation: External models (Gemini-2.5-Flash and Claude-Sonnet-4) verify correctness and option validity to prevent model-specific biases.
- Human Verification: Four human reviewers manually inspect 3,436 candidates against full video and transcript context, ultimately selecting the final 1,741 samples for the benchmark.
Method
The authors propose EgoMAS (Egocentric Multi-Agent System), a centralized, training-free baseline designed to address the challenges of multi-agent egocentric reasoning. The system operates through a two-stage architecture comprising an event-based shared memory and an agent-wise dynamic retrieval mechanism.
Event-based Shared Memory To achieve a system-level global understanding, the system aggregates fragmented events from multiple agents. At every 10-minute interval, each embodied agent provides a caption summarizing its observations. A centralized manager then integrates these individual captions into a system-level summary. Rather than producing a flat textual condensation, the manager identifies key events across agents and explicitly records the corresponding 4W1H fields: When, What, Where, Who, and How. This produces a coherent global memory that aligns agent perspectives while preserving critical details for reasoning.
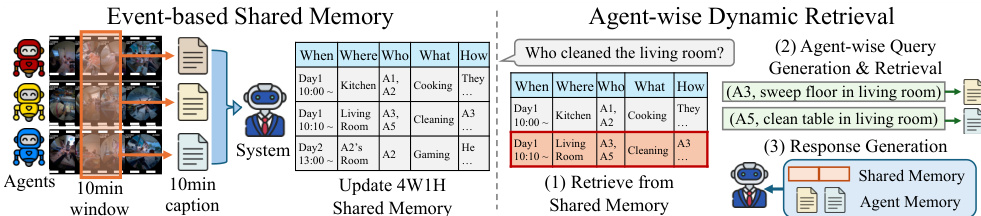
Agent-wise Dynamic Retrieval Given a query q, EgoMAS employs a hierarchical retrieval strategy to ensure fine-grained reasoning across multiple perspectives. First, the system retrieves the top-n system-level memories from the shared memory Mshared using BM25 ranking:
Rsvs(q)=Top⋅n{(m,s(m,q))∣m∈Mshared},where s(m,q) denotes the BM25 score between memory m and query q. From the retrieved system-level context, EgoMAS generates a set of agent-specific retrieval requests Qagent={(aj,qj)}j=1J, where each request consists of an agent identifier aj and a sub-query qj. For each (aj,qj), the system performs agent-level retrieval from the specific agent's memory Mai:
Rai(qj)=Top\textsl−k{(m,s(m,qj))∣m∈Mai}.To ensure relevance, memories with scores below a threshold τ are filtered out:
Rai(qj)={(m,s(m,qj))∈Rai(qj)∣s(m,qj)≥τ}.Finally, the system generates the final response by conditioning on both the retrieved system-level context Rsys(q) and the aggregated agent-level results R=⋃i=1JRai(qj):
y^=F(q,Rsys(q),R),where y^ and F denote the response and response generation function.
Benchmark Generation Process To support this research, the authors also establish a rigorous data generation pipeline. This process involves three stages: QA Generation, Filtering, and Manual Verification. In Stage I, questions are generated based on categories such as Single-span QA, Multi-span QA, and Template-based queries (TR, EI). Stage II applies zero-shot filtering, single-agent filtering, and cross-model verification to ensure quality. Finally, Stage III involves human verification to validate the dataset.
Experiment
- Evaluation on the MA-EgoQA benchmark demonstrates that current models struggle with multi-agent egocentric video understanding, with even top proprietary models achieving low accuracy, highlighting the task's difficulty.
- Experiments comparing input strategies reveal that concatenating all captions or frames without retrieval introduces noise and high computational costs, whereas retrieval-based approaches significantly improve efficiency and performance.
- The EgoMAS framework outperforms all baselines by effectively aggregating memories from multiple agents, proving that multi-agent memory access is essential for accurate reasoning.
- Analysis of sub-categories shows that performance degrades as the number of required agents or time spans increases, and Theory of Mind tasks remain the most challenging due to the need for inferring latent mental states.
- Ablation studies confirm that EgoMAS benefits from combining shared memory construction with agent-wise dynamic retrieval, and that an event-based memory structure is superior to alternative methods.
- Sensitivity analysis indicates that accuracy improves with the number of available agents, while modality experiments suggest that visual frames are crucial for specific queries but can distract models if not selected adaptively.