Command Palette
Search for a command to run...
Stepping VLMs onto the Court: Benchmarking Spatial Intelligence in Sports
Stepping VLMs onto the Court: Benchmarking Spatial Intelligence in Sports
Abstract
Sports have long attracted broad attention as they push the limits of human physical and cognitive capabilities. Amid growing interest in spatial intelligence for vision-language models (VLMs), sports provide a natural testbed for understanding high-intensity human motion and dynamic object interactions. To this end, we present CourtSI, the first large-scale spatial intelligence dataset tailored to sports scenarios. CourtSI contains over 1M QA pairs, organized under a holistic taxonomy that systematically covers spatial counting, distance measurement, localization, and relational reasoning, across representative net sports including badminton, tennis, and table tennis. Leveraging well-defined court geometry as metric anchors, we develop a semi-automatic data engine to reconstruct sports scenes, enabling scalable curation of CourtSI. In addition, we introduce CourtSI-Bench, a high-quality evaluation benchmark comprising 3,686 QA pairs with rigorous human verification. We evaluate 25 proprietary and open-source VLMs on CourtSI-Bench, revealing a remaining human-AI performance gap and limited generalization from existing spatial intelligence benchmarks. These findings indicate that sports scenarios expose limitations in spatial intelligence capabilities captured by existing benchmarks. Further, fine-tuning Qwen3-VL-8B on CourtSI improves accuracy on CourtSI-Bench by 23.5 percentage points. The adapted model also generalizes effectively to CourtSI-Ext, an evaluation set built on a similar but unseen sport, and demonstrates enhanced spatial-aware commentary generation. Together, these findings demonstrate that CourtSI provides a scalable pathway toward advancing spatial intelligence of VLMs in sports.
One-sentence Summary
Researchers from Fudan University and Shanghai Artificial Intelligence Laboratory introduce CourtSI, the first large-scale spatial intelligence dataset for sports, which leverages a semi-automatic 3D reconstruction engine to generate over one million metric-accurate QA pairs for fine-grained human-centric reasoning in dynamic net sports scenarios.
Key Contributions
- Sports scenarios present a unique challenge for spatial intelligence due to high-intensity human motion and dynamic object interactions, which existing benchmarks fail to capture as they focus primarily on static scenes and rigid objects.
- The authors introduce CourtSI, a large-scale dataset with over 1M QA pairs, and CourtSI-Bench, a rigorously verified evaluation set, by leveraging a semi-automatic data engine that reconstructs 3D sports scenes using court geometry as metric anchors.
- Evaluations of 25 vision-language models reveal a significant human-AI performance gap, while fine-tuning Qwen3-VL-8B on CourtSI improves benchmark accuracy by 23.5 percentage points and demonstrates strong generalization to unseen sports like pickleball.
Introduction
Vision-language models are increasingly expected to reason about the 3D physical world, yet current benchmarks largely rely on static scenes and rigid objects, leaving a gap in understanding dynamic human motion and non-rigid interactions. Sports offer a high-intensity testbed for this challenge but have been underexplored due to the difficulty of obtaining metrically accurate spatial data from broadcast footage. To address this, the authors introduce CourtSI, the first large-scale dataset and benchmark for spatial intelligence in sports, which leverages the fixed geometry of court lines to reconstruct 3D scenes with centimeter-level accuracy. They further present CourtSI-Bench to rigorously evaluate model performance, revealing significant limitations in existing VLMs while demonstrating that fine-tuning on their data substantially improves spatial reasoning and generalization to unseen sports.
Dataset
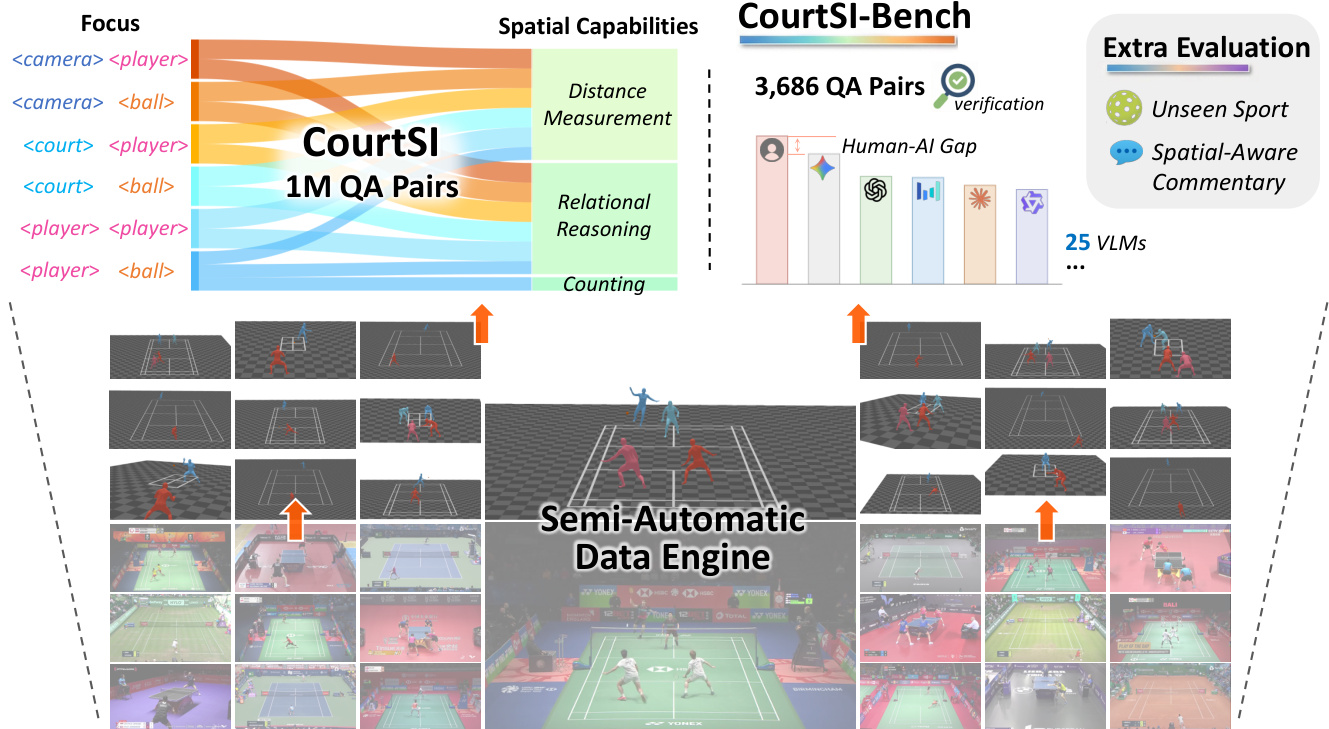
CourtSI Dataset Overview
-
Dataset Composition and Sources The authors construct CourtSI and its evaluation counterpart, CourtSI-Bench, using broadcast-view images sourced from RacketVision, a large-scale benchmark containing professional net sports clips. The data covers three specific sports: badminton, tennis, and table tennis. The pipeline relies on a semi-automatic data engine that leverages the standardized geometric layouts of sports courts to enable scalable, metric-accurate 3D scene reconstruction.
-
Key Details for Each Subset
- CourtSI (Training Set): This large-scale dataset comprises 1,008,941 question-answer pairs generated from 52,481 images spanning 1,057 unique scenes. It includes diverse question types such as spatial counting, distance measurement, localization, and relational reasoning.
- CourtSI-Bench (Evaluation Set): Designed to prevent information leakage, this benchmark contains 3,686 QA pairs sampled from 1,988 images across 382 distinct scenes that do not overlap with the training set. The authors ensure a balanced distribution across the three sports and task categories to facilitate reliable evaluation.
-
Data Usage and Processing Strategy The authors employ a deterministic pipeline to generate QA pairs. They first reconstruct 3D scenes and then automatically formulate questions and derive answers based on the recovered spatial states. The process involves:
- Metric-Aware Reconstruction: Using court geometry as anchors to solve for camera parameters via Perspective-n-Point (PnP) solvers, ensuring world-grounded coordinates.
- Object Localization: Converting depth estimation into ground projection estimation for balls and applying similarity transformations to human meshes to correct depth errors based on annotated lowest vertex heights.
- Question Generation: Utilizing 94 predefined templates to create questions that cover both numerical outputs (e.g., distances in meters, 3D coordinates) and multiple-choice options.
-
Quality Control and Metadata Construction To ensure reliability, the authors implement a rigorous quality control process. They validate the data engine using a purpose-built multi-view dataset, confirming that ball and player localization errors remain at the centimeter level. For CourtSI-Bench specifically, two annotators independently review all QA pairs with access to 3D visualizations to identify and remove instances with reconstruction failures or ambiguous spatial relationships. The final benchmark is resampled to maintain balance after this human verification step.
Method
The authors propose a semi-automatic data engine to generate a large-scale dataset for spatial understanding in sports. The overall framework transforms raw sports images into a structured dataset containing 1 million QA pairs, enabling the evaluation of spatial capabilities like distance measurement and relational reasoning.
The core of the method is a 3D scene reconstruction pipeline. It begins with raw images where player meshes are recovered using PromptHMR and SAM3 to generate bounding boxes, followed by a height correction step. Simultaneously, the court geometry is established through manual annotation of ground and height points. A PnP solver utilizes these points to estimate metric-aware camera parameters. Ball annotations are also performed by marking 2D locations and projecting them to ground positions. These components are integrated to create a fully reconstructed 3D scene.

The court annotation process specifically involves defining 3D bounding boxes or planes for different sports, such as badminton, tennis, and table tennis, to ensure accurate spatial grounding.

To standardize spatial reasoning, the system adopts a specific coordinate system where the origin (0,0,0) is located at the intersection of the far baseline and the left doubles sideline (or the top-left corner of the table surface). The X-axis extends along the sideline towards the camera, the Y-axis extends along the far baseline to the right, and the Z-axis is vertical.
Based on these reconstructed 3D scenes, the authors generate a diverse set of question-answer pairs. These include numerical questions regarding distances and coordinates, multiple-choice questions (MCQs) for relational reasoning, and counting tasks.

Experiment
- Evaluation of 25 vision-language models on CourtSI-Bench reveals that while proprietary models approach human performance, they often struggle with instruction compliance and require post-processing to extract answers, whereas most open-source models fail significantly on metric-sensitive tasks like distance measurement.
- Human evaluators outperform all models overall but show notable limitations in estimating absolute distances and localization, highlighting the need for advanced 3D perception capabilities in sports scenarios.
- Fine-tuning on the CourtSI dataset yields substantial improvements in spatial intelligence, particularly for distance measurement, demonstrating the effectiveness of the curated data for enhancing model reasoning.
- Error analysis identifies perspective projection and 3D-to-2D ambiguity as primary failure modes, causing performance degradation as the discrepancy between 3D reality and 2D image appearance increases.
- Cross-sport evaluation on an unseen pickleball dataset confirms that while fine-tuning improves generalization, significant challenges remain in transferring spatial reasoning across different sports.
- Application testing on spatial-aware commentary generation shows that fine-tuned models successfully transfer learned spatial capabilities to downstream tasks, producing more accurate and contextually relevant descriptions without sacrificing linguistic quality.
- Comparisons with monocular scene reconstruction methods indicate that leveraging court geometry leads to superior camera calibration and player localization accuracy compared to standard depth estimation pipelines.