Command Palette
Search for a command to run...
ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
Songlin Yang Zhe Wang Xuyi Yang Songchun Zhang Xianghao Kong Taiyi Wu Xiaotong Zhao Ran Zhang Alan Zhao Anyi Rao
Abstract
Text-driven video generation has democratized film creation, but camera control in cinematic multi-shot scenarios remains a significant block. Implicit textual prompts lack precision, while explicit trajectory conditioning imposes prohibitive manual overhead and often triggers execution failures in current models. To overcome this bottleneck, we propose a data-centric paradigm shift, positing that aligned (Caption, Trajectory, Video) triplets form an inherent joint distribution that can connect automated plotting and precise execution. Guided by this insight, we present ShotVerse, a "Plan-then-Control" framework that decouples generation into two collaborative agents: a VLM (Vision-Language Model)-based Planner that leverages spatial priors to obtain cinematic, globally aligned trajectories from text, and a Controller that renders these trajectories into multi-shot video content via a camera adapter. Central to our approach is the construction of a data foundation: we design an automated multi-shot camera calibration pipeline aligns disjoint single-shot trajectories into a unified global coordinate system. This facilitates the curation of ShotVerse-Bench, a high-fidelity cinematic dataset with a three-track evaluation protocol that serves as the bedrock for our framework. Extensive experiments demonstrate that ShotVerse effectively bridges the gap between unreliable textual control and labor-intensive manual plotting, achieving superior cinematic aesthetics and generating multi-shot videos that are both camera-accurate and cross-shot consistent.
One-sentence Summary
Researchers from HKUST and Tencent Video AI Center propose ShotVerse, a Plan-then-Control framework that uses a VLM-based planner to automate cinematic trajectory generation. By introducing a novel calibration pipeline and the ShotVerse-Bench dataset, it enables precise, consistent multi-shot video creation without manual trajectory plotting.
Key Contributions
- Current text-driven video generation struggles with precise camera control in multi-shot scenarios due to the lack of precision in implicit prompts and the high manual overhead of explicit trajectory conditioning.
- ShotVerse introduces a "Plan-then-Control" framework that decouples generation into a VLM-based Planner for automated cinematic trajectory plotting and a Controller for precise multi-shot video rendering.
- The authors establish a data foundation by designing an automated calibration pipeline to create ShotVerse-Bench, a high-fidelity dataset that enables the framework to achieve superior camera accuracy and cross-shot consistency.
Introduction
Text-driven video generation has empowered users to create cinematic content, yet controlling camera movements across multiple shots remains a major hurdle. Prior approaches struggle with the imprecision of implicit text prompts or the prohibitive manual effort and execution failures associated with explicit trajectory conditioning. To address these challenges, the authors introduce ShotVerse, a "Plan-then-Control" framework that decouples cinematic planning from video synthesis. They leverage a Vision-Language Model as a Planner to automatically generate unified 3D camera trajectories from text descriptions and a Controller to render high-fidelity multi-shot videos based on these precise paths. Central to this work is the creation of ShotVerse-Bench, a new dataset featuring disjoint shots aligned into a global coordinate system via an automated calibration pipeline, which enables the model to learn the spatial logic required for professional cinematography.
Dataset
-
Dataset Composition and Sources: The authors introduce ShotVerse-Bench, a dataset designed to align semantic descriptions with globally unified camera trajectories. It comprises 20,500 clips sourced from high-production cinema to ensure professional cinematography standards and a balanced taxonomy of camera controls.
-
Key Details for Each Subset:
- Multi-Shot Sequences: The training subset consists of 1,000 scenes, while the test subset contains 100 scenes with no overlap.
- Structure: These scenes are formed by grouping 2,750 representative single-shot clips into sequences of 249 frames.
- Shot Distribution: Each multi-shot scene contains 2, 3, or 4 shots, distributed according to a 6:3:1 ratio.
-
Data Usage and Processing:
- Preprocessing: The authors remove embedded subtitles and standardize all video resolution to 843 × 480 pixels.
- Training Split: The 1,000 scenes are allocated for model training, and the remaining 100 scenes serve as the test set.
-
Calibration and Alignment Strategy: To unify disjoint single-shot trajectories into a global coordinate system, the authors employ a four-step pipeline:
- Dynamic Foreground Removal: They use SAM to mask foreground objects, retaining only static background regions for robust pose estimation.
- Local Reconstruction: Each shot is independently reconstructed using PI3 on the static background to create locally consistent trajectories.
- Global Reconstruction: Keyframes across disjoint shots are sampled and jointly reconstructed via PI3 to generate a unified static scene and global poses.
- Anchor-Based Alignment: The authors identify anchor frames present in both local and global reconstructions to estimate a similarity transformation. This aligns local frames to the global system and resolves scale ambiguity by comparing relative displacements of start and end keyframes.
Method
The authors propose ShotVerse, a framework designed to decouple the multi-shot camera control task into distinct planning and controlling phases. This "Plan-then-Control" architecture bridges the gap between unreliable textual camera control and labor-intensive manual plotting by modeling the joint distribution of aligned triplets consisting of captions, trajectories, and videos. The overall workflow is illustrated in the figure below, which outlines the three core components: Dataset Curation, the Planner for trajectory plotting, and the Controller for trajectory injection.
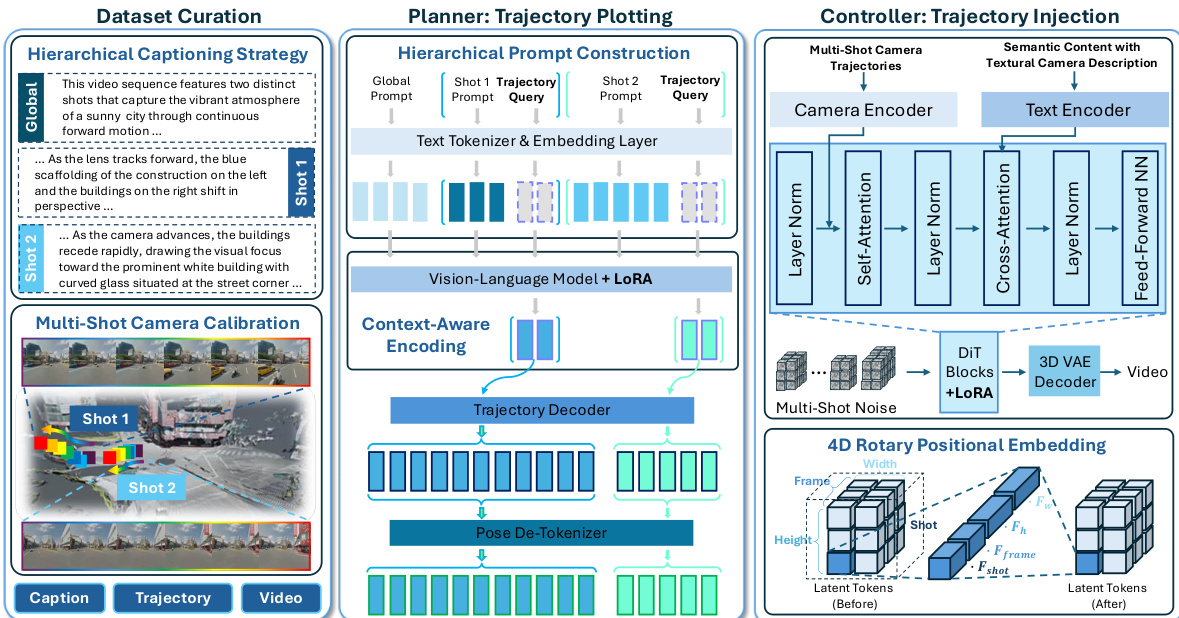
Dataset Curation The foundation of the framework relies on a curated dataset where multi-shot trajectories are aligned into a unified global coordinate system via camera calibration. This process pairs the visual data with hierarchical captions, including a global description and specific per-shot narratives, ensuring the model learns the relationship between semantic content and geometric camera movement.
Planner: Trajectory Plotting The Planner module is responsible for synthesizing cinematic, globally unified trajectories from hierarchical textual descriptions. It operates by modeling the conditional probability P(Trajectory∣Caption). The process begins with Hierarchical Prompt Construction, where the input sequence interleaves a global prompt with per-shot prompts and learnable trajectory query tokens. These tokens act as placeholders for the Vision-Language Model (VLM) to fill with shot-specific camera plans.
The VLM backbone, fine-tuned with LoRA, performs context-aware encoding. Through self-attention mechanisms, the hidden states of the trajectory query tokens aggregate information from the global context and previous shots. These encoded representations, referred to as camera codes, are then passed to a Trajectory Decoder. This decoder expands the fixed number of camera codes into a variable-length sequence of trajectory tokens. Finally, a Pose De-Tokenizer maps these generated tokens back to continuous values, recovering the explicit camera poses in the unified global coordinate system. The Planner is trained end-to-end to maximize the log-likelihood of the ground-truth trajectory tokens.
Controller: Trajectory Injection The Controller module renders the plotted trajectories into high-fidelity multi-shot videos by modeling P(Video∣Caption,Trajectory). It utilizes a holistic Diffusion Transformer (DiT) backbone. To ensure precise adherence to the camera paths, the authors implement a Camera Encoder that projects the extrinsic matrix of each frame into a feature vector. This camera embedding is directly added to the intermediate visual features before the self-attention layer, enforcing geometric adherence without disrupting pre-trained priors.
To handle the hierarchical temporal structure of multi-shot videos, the architecture employs a 4D Rotary Positional Embedding strategy. Unlike standard 3D embeddings, this approach partitions the attention head dimension into four subspaces corresponding to shot index, frame index, height, and width. This explicitly informs the model of shot boundaries, enforcing intra-shot consistency while maintaining fine-grained temporal dynamics. The Controller is optimized using a Flow Matching objective, predicting the velocity field between clean video latents and Gaussian noise samples conditioned on both text and camera embeddings.
Experiment
- A three-track evaluation protocol was established to assess text-to-trajectory planning, trajectory-to-video execution fidelity, and end-to-end multi-shot generation quality, addressing the lack of systematic benchmarks for cinematic video creation.
- The proposed Planner outperforms existing trajectory generation methods by leveraging vision-language priors to better align complex narrative prompts with camera sequences.
- The Controller demonstrates superior execution fidelity and cross-shot consistency compared to single-shot baselines, effectively maintaining subject orientation and geometric alignment across cuts.
- End-to-end results show that the integrated system achieves higher temporal coherence and aesthetic quality than both open-source and commercial models, which often fail to execute complex camera movements without explicit geometric guidance.
- Ablation studies confirm that the VLM encoder, dedicated trajectory decoder, 4D positional encoding, and unified camera calibration are critical components for achieving stable shot transitions and cinematic pacing.
- Training on real cinematic data rather than synthetic triplets is essential for preserving visual quality and temporal stability in the final output.