Command Palette
Search for a command to run...
MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
Haozhan Shen Shilin Yan Hongwei Xue Shuaiqi Lu Xiaojun Tang Guannan Zhang Tiancheng Zhao Jianwei Yin
Abstract
Multimodal Large Language Models (MLLMs) are increasingly used to carry out visual workflows such as navigating GUIs, where the next step depends on verified visual compositional conditions (e.g., "if a permission dialog appears and the color of the interface is green, click Allow") and the process may branch or terminate early. Yet this capability remains under-evaluated: existing benchmarks focus on shallow-compositions or independent-constraints rather than deeply chained compositional conditionals. In this paper, we introduce MM-CondChain, a benchmark for visually grounded deep compositional reasoning. Each benchmark instance is organized as a multi-layer reasoning chain, where every layer contains a non-trivial compositional condition grounded in visual evidence and built from multiple objects, attributes, or relations. To answer correctly, an MLLM must perceive the image in detail, reason over multiple visual elements at each step, and follow the resulting execution path to the final outcome. To scalably construct such workflow-style data, we propose an agentic synthesis pipeline: a Planner orchestrates layer-by-layer generation of compositional conditions, while a Verifiable Programmatic Intermediate Representation (VPIR) ensures each layer's condition is mechanically verifiable. A Composer then assembles these verified layers into complete instructions. Using this pipeline, we construct benchmarks across three visual domains: natural images, data charts, and GUI trajectories. Experiments on a range of MLLMs show that even the strongest model attains only 53.33 Path F1, with sharp drops on hard negatives and as depth or predicate complexity grows, confirming that deep compositional reasoning remains a fundamental challenge.
One-sentence Summary
Researchers from Alibaba Group and Zhejiang University introduce MM-CondChain, a benchmark for visually grounded deep compositional reasoning that employs a VPIR-based agentic pipeline to generate mechanically verifiable, multi-layer conditional chains, revealing that even state-of-the-art multimodal models struggle with complex visual workflows requiring precise step-by-step verification.
Key Contributions
- Existing benchmarks fail to evaluate deep compositional reasoning because they focus on shallow single-layer compositions or independent constraints rather than multi-layer visual workflows where each step determines the execution path.
- The authors introduce MM-CondChain, a benchmark featuring nested conditional chains grounded in visual evidence, constructed via an agentic synthesis pipeline that uses a Verifiable Programmatic Intermediate Representation to ensure mechanical verifiability.
- Experiments across natural images, data charts, and GUI trajectories reveal that even the strongest multimodal models achieve only 53.33 Path F1, demonstrating significant performance drops as reasoning depth and predicate complexity increase.
Introduction
Multimodal Large Language Models are increasingly deployed in complex visual workflows like GUI navigation, where subsequent actions depend on verifying chained visual conditions. However, existing benchmarks fail to evaluate this capability because they focus on shallow, single-layer compositions or independent constraints rather than deep, multi-step reasoning paths that branch or terminate based on visual evidence. To address this gap, the authors introduce MM-CondChain, a benchmark featuring multi-layer control flow with mechanically verified hard negatives. They achieve scalable and reliable data construction through an agentic synthesis pipeline that uses a Verifiable Programmatic Intermediate Representation to decouple logical condition generation from natural language rendering.
Dataset
-
Dataset Composition and Sources: The authors construct MM-CondChain from three distinct visual domains using publicly available datasets. The Natural domain includes 398 images from SAM and GQA, the Chart domain features 200 chart images from ChartQA, and the GUI domain comprises 377 interaction trajectories (totaling 3,421 screenshots) sourced from AITZ.
-
Key Details for Each Subset:
- Natural: Focuses on object attributes and spatial relations.
- Chart: Concentrates on numerical and structural statistics across bar, line, and pie charts.
- GUI: Emphasizes action, state, and trajectory-level metadata with fine-grained reasoning annotations.
- Total Volume: The benchmark contains 975 evaluation samples, where each sample consists of a paired True-path and False-path instance.
-
Data Usage and Processing:
- Synthesis Pipeline: The authors employ Gemini-3-Pro to instantiate all agents in the synthesis pipeline, including the Planner, Verifier, Fact Extractor, and Translator.
- Subject De-leakage: An MLLM-based rewriter modifies subject descriptions to remove condition-revealing attributes while ensuring the subject remains uniquely referential to the target object.
- Paired-Path Instantiation: Each control-flow skeleton generates two nearly isomorphic instances. The True-path follows all conditions to a terminal layer, while the False-path swaps a single condition at a randomly sampled divergence layer to trigger early termination.
- Instruction Compilation: The system merges subjects and conditions into fluent natural-language if-clauses to create nested instructions that serve as hard negatives.
-
Evaluation Strategy:
- Metrics: Performance is measured using True-path Accuracy, False-path Accuracy, and Path F1 (the harmonic mean of the two), with an overall score calculated as the average Path F1 across domains.
- Setup: Models are evaluated in a zero-shot setting using default API parameters, with answers extracted from multiple-choice outputs based on specific formatting rules.
Method
The authors propose a VPIR-based agentic benchmark construction pipeline that decouples logical construction from language rendering to address logical inconsistencies in multi-layer compositional reasoning. The core framework accepts multimodal inputs, including natural images, chart images with metadata, and GUI trajectories with annotations. Refer to the framework diagram for the overall architecture.
The pipeline operates through an iterative, multi-layer reasoning chain coordinated by a Planner. At each layer t, the Planner selects a relational strategy rt to determine how the reasoning chain evolves, choosing between actions such as EXTEND, FINISH, or ROLLBACK. This control mechanism ensures that the chain depth remains within a target interval while maintaining coherence.
Once a layer is initiated, the system executes a four-stage synthesis workflow. First, a Fact Extractor grounds the generation in visual evidence by selecting a subject St and producing structured facts Ft as a typed key-value mapping. This structured representation prevents hallucination and defines a programmatic namespace. Second, the VPIR Generator synthesizes a Verifiable Programmatic Intermediate Representation, consisting of a true-logic predicate pt and a counterfactual false-logic p~t. These predicates are executable Python-like code evaluated in a sandboxed environment to ensure mechanical verifiability.
As shown in the figure below:
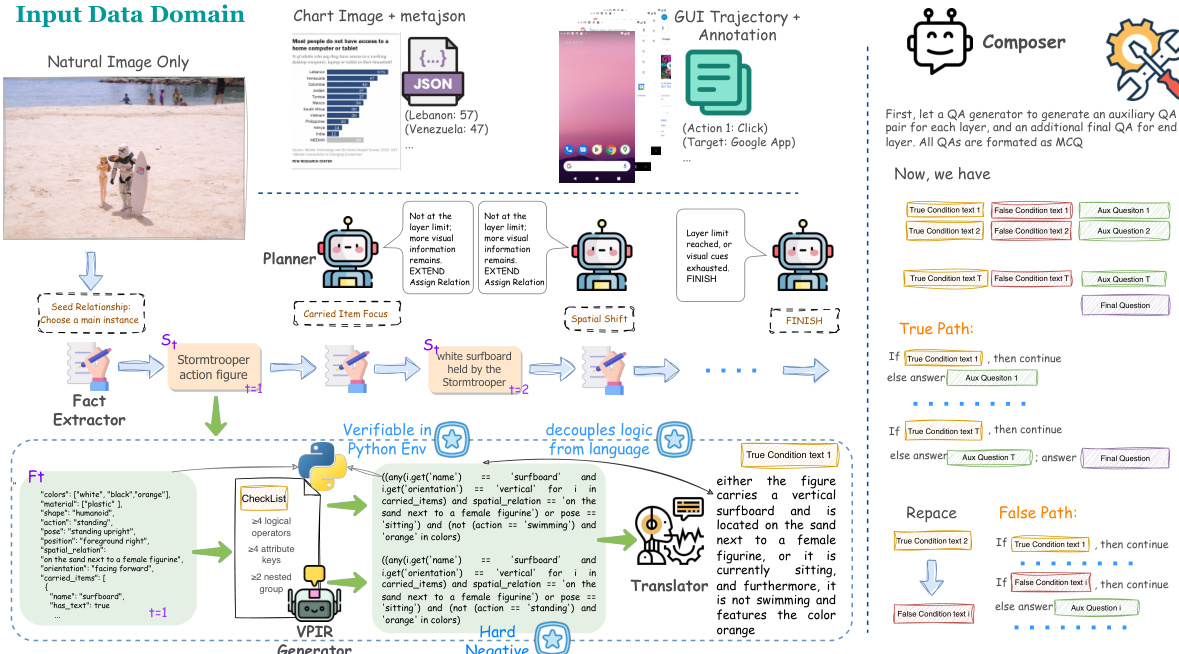
Third, a Translator renders the verified executable logic into natural language condition texts ct and c~t. This step ensures that truth values are anchored in code execution rather than linguistic generation. Finally, a Composer compiles the verified chain into paired benchmark instances. It constructs a True-path where all conditions hold and a False-path where a single condition is replaced by a minimally perturbed counterfactual, creating hard negatives that require precise visual grounding and deep compositional reasoning.
Experiment
- Main evaluation on MM-CondChain reveals that current multimodal large language models struggle with visually grounded deep compositional reasoning, with even top performers achieving only slightly above 50% average Path F1.
- Experiments comparing true versus false paths show a significant bias where models over-assume conditions hold, leading to high accuracy on valid paths but poor performance on invalid ones, which poses risks in real-world workflows.
- Domain analysis indicates that GUI tasks are the most challenging due to the need for multi-frame trajectory and state transition reasoning, whereas chart tasks are comparatively easier as they often reduce to deterministic numerical comparisons.
- Ablation studies on chain depth demonstrate that performance degrades consistently as the number of sequential verification layers increases, confirming that errors compound across layers rather than remaining isolated.
- Tests on predicate complexity reveal that increasing the logical operators and nesting within a single condition causes substantial performance drops, highlighting that models struggle with both sequential and intra-layer compositional reasoning.
- Overall, the findings establish that chain depth and predicate complexity are two orthogonal axes of difficulty that jointly define the limits of current models, making the benchmark a valuable diagnostic tool for identifying specific reasoning failures.