Command Palette
Search for a command to run...
PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
Abstract
Post-training for long-horizon agentic tasks has a tension between compute efficiency and generalization. While supervised fine-tuning (SFT) is compute efficient, it often suffers from out-of-domain (OOD) degradation. Conversely, end-to-end reinforcement learning (E2E RL) preserves OOD capabilities, but incurs high compute costs due to many turns of on-policy rollout. We introduce PivotRL, a novel framework that operates on existing SFT trajectories to combine the compute efficiency of SFT with the OOD accuracy of E2E RL. PivotRL relies on two key mechanisms: first, it executes local, on-policy rollouts and filters for pivots: informative intermediate turns where sampled actions exhibit high variance in outcomes; second, it utilizes rewards for functional-equivalent actions rather than demanding strict string matching with the SFT data demonstration. We theoretically show that these mechanisms incentivize strong learning signals with high natural gradient norm, while maximally preserving policy probability ordering on actions unrelated to training tasks. In comparison to standard SFT on identical data, we demonstrate that PivotRL achieves +4.17% higher in-domain accuracy on average across four agentic domains, and +10.04% higher OOD accuracy in non-agenetic tasks. Notably, on agentic coding tasks, PivotRL achieves competitive accuracy with E2E RL with 4× fewer rollout turns. PivotRL is adopted by NVIDIA's Nemotron-3-Super-120B-A12B, acting as the workhorse in production-scale agentic post-training.
One-sentence Summary
By identifying high-variance pivot turns and utilizing rewards for functional-equivalent actions, the PivotRL framework bridges the gap between efficient supervised fine-tuning and robust reinforcement learning to achieve higher in-domain and out-of-domain accuracy for long-horizon agentic tasks at a significantly lower computational cost.
Key Contributions
- The paper introduces PivotRL, a turn-level reinforcement learning framework that enables efficient post-training for long-horizon agentic tasks by converting existing supervised fine-tuning trajectories into on-policy optimization signals.
- The method utilizes two core mechanisms consisting of pivot filtering to identify informative intermediate turns with high outcome variance and the application of functional rewards that prioritize task success over strict string matching.
- Experimental results demonstrate that PivotRL achieves a 4.17% increase in average in-domain accuracy and a 10.04% improvement in out-of-domain accuracy compared to standard supervised fine-tuning, while matching the performance of end-to-end reinforcement learning with 4x fewer rollout turns in agentic coding tasks.
Introduction
Training large language models for long-horizon agentic tasks requires a careful balance between computational efficiency and the ability to generalize to new environments. While supervised fine-tuning (SFT) is computationally efficient, it often leads to out-of-domain degradation and catastrophic forgetting. Conversely, end-to-end reinforcement learning (RL) preserves generalization capabilities but incurs massive compute costs due to the high number of on-policy rollouts required. The authors leverage a novel framework called PivotRL to bridge this gap by operating on existing SFT trajectories. PivotRL utilizes two primary mechanisms: pivot filtering, which identifies informative intermediate turns with high outcome variance, and functional rewards, which reward actions that achieve the correct result rather than requiring strict string matching. This approach allows the model to achieve competitive accuracy with end-to-end RL while using significantly fewer rollout turns.
Dataset

The authors utilize a diverse set of domain-specific datasets to train their model, focusing on extracting and filtering pivot candidates from demonstration traces before Reinforcement Learning (RL) training.
-
Dataset Composition and Sources
- τ2-Bench: A synthetic SFT trajectory dataset containing 281,774 trajectories across 838 domains, generated using a pipeline inspired by ToolAce, Kimi-K2, and DeepSeek-V3.2.
- Terminal-Bench: A collection of approximately 20,000 resolved trajectories sourced from Qwen3-Coder-480B-A35B-Instruct and Kimi-K2-Instruct via Terminus agents.
- SWE-Bench Verified: An internal trajectory dataset generated using OpenHands, OpenCode, and Codex on tasks from SWE-Gym and R2E-Gym, utilizing the MiniMax-M2.5 model.
- BrowseComp: A dataset of 13,215 samples consisting of browsing trajectories generated by combining multi-hop question-answer sets with an online search engine and DeepSeek-V3.2.
-
Key Details and Processing
- Pivot Extraction: In all domains, the authors identify pivot candidates at model-call boundaries. For τ2-Bench, every assistant turn is a candidate. In Terminal-Bench, every assistant bash action is a candidate. For SWE-Bench, every non-error tool-call is a candidate. In BrowseComp, search-related assistant steps are treated as candidates.
- Filtering and Verification:
- Terminal-Bench uses a command-deduplication step and a local verifier that combines output-schema validation, normalized string similarity, and LLM-as-judge scoring to ensure command interchangeability.
- SWE-Bench Verified uses a coarse local verifier that only matches tool-call names (e.g., search, open, edit) to check if the correct operation type was selected.
- The authors specifically evaluate the impact of selecting low-reward-mean pivot sets, which in the case of SWE-Bench results in a final training set of 87,718 samples.
-
Training and Usage
- Model Training: The τ2-Bench training is performed on top of Qwen3-30B-A3B-Thinking-2507.
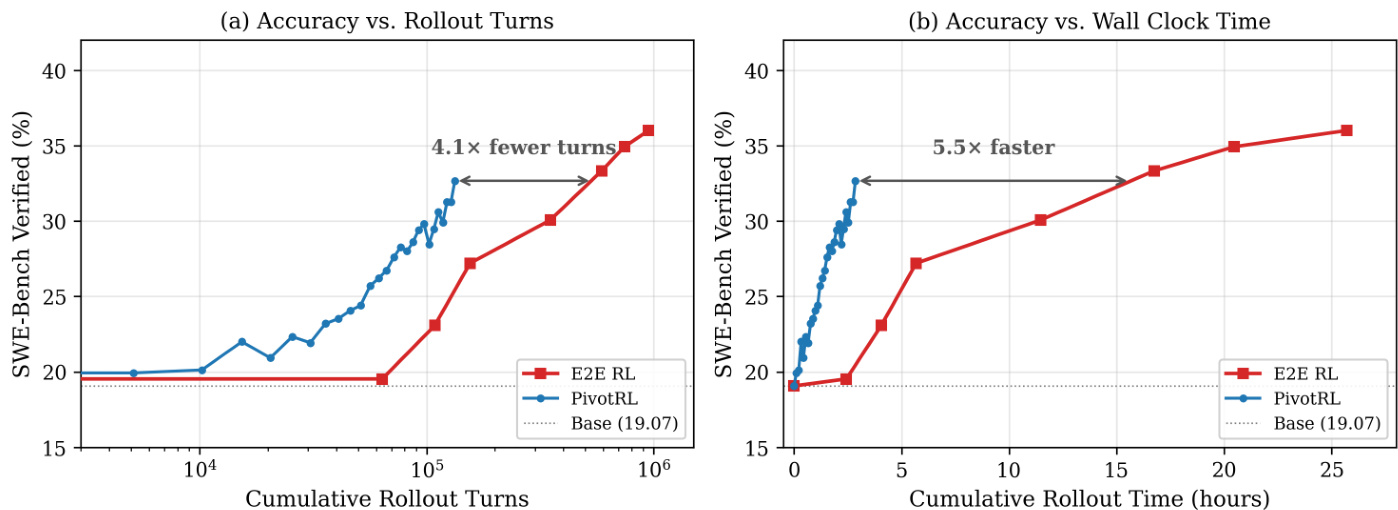
- RL Efficiency: For end-to-end RL comparisons, the authors use PivotRL with a batch size of 1024 (64 prompts by 16 generations) at 1 turn per sample. This approach achieves matched accuracy with significantly higher efficiency, requiring approximately 4 times fewer rollout turns and 5.5 times less wall-clock time compared to standard end-to-end RL baselines.
Method
The authors propose PivotRL, a local reinforcement learning framework designed to overcome the inefficiencies of standard turn-level agentic training. The method addresses two primary bottlenecks identified in naive local RL: the presence of uninformative turns that yield zero learning signals under group-normalized advantage estimation, and the excessive strictness of exact-match rewards in generative action spaces.
The PivotRL training pipeline consists of three core stages: offline turn profiling, local on-policy rollouts, and optimization via a verifier-based objective.
First, the authors perform offline turn selection to identify informative states. Starting from a candidate dataset Dcand extracted from SFT trajectories, the method estimates the informativeness of each turn using a frozen reference policy π0. For each state s, K local rollouts are sampled from π0(⋅∣s) and evaluated using a domain-specific verifier. The empirical reward mean μ^(s) and variance σ^2(s) are calculated as follows:
μ^(s)=K1∑k=1Krfunc(s,a(k)),σ^2(s)=K1∑k=1K(rfunc(s,a(k))−μ^(s))2.
The authors then filter these turns to create a pivot dataset Dpivot. A turn is retained only if it exhibits non-zero reward variance and a reward mean below a difficulty threshold λdiff:
Dadv={(s,a∗)∈Dcand : σ^2(s)>0, μ^(s)<λdiff}.
This selection process ensures that the online rollout budget is concentrated on mixed-outcome turns that provide a meaningful gradient signal.
Second, the method employs a verifier-based local reward to provide more permissive credit assignment. Instead of requiring an exact match with the expert demonstration, the reward rfunc(s,a) is defined by a set of locally acceptable actions M(s) determined by a verifier:
rfunc(s,a)=1[a∈M(s)].
Finally, the policy is optimized using a GRPO-style objective tailored for these local rollouts. For a sampled state s∈Dpivot, a group of G actions is sampled from the current policy πθold. The advantage A^i for each action is computed by normalizing the verifier rewards across the group. The objective function JPivotRL(θ) incorporates a KL divergence penalty relative to the reference policy π0 to ensure stable updates:
JPivotRL(θ)=Es∼Dpivot{ai}i=1G∼πθold(⋅∣s)[G1∑i=1Gmin(wi(θ)A^i,clip(wi(θ),1−ϵ,1+ϵ)A^i)−DKL],
where wi(θ)=πold(ai∣s)πθ(ai∣s) and DKL=βKL(πθ(⋅∣s)∥π0(⋅∣s)). This approach allows the model to explore functionally correct actions that may differ from the expert string, thereby expanding the effective training signal while maintaining the structural integrity of the reference policy.
Experiment
The experiments evaluate PivotRL across various agentic domains, including conversational tool use, software engineering, terminal control, and web browsing, comparing it against supervised fine-tuning (SFT) and end-to-end reinforcement learning (E2E RL). Results demonstrate that PivotRL achieves superior in-domain accuracy compared to SFT while effectively preventing the catastrophic out-of-domain performance degradation typically seen with fine-tuning. Furthermore, PivotRL provides competitive accuracy to E2E RL on complex benchmarks like SWE-Bench but with significantly higher computational efficiency, requiring far fewer rollout turns and less training time.
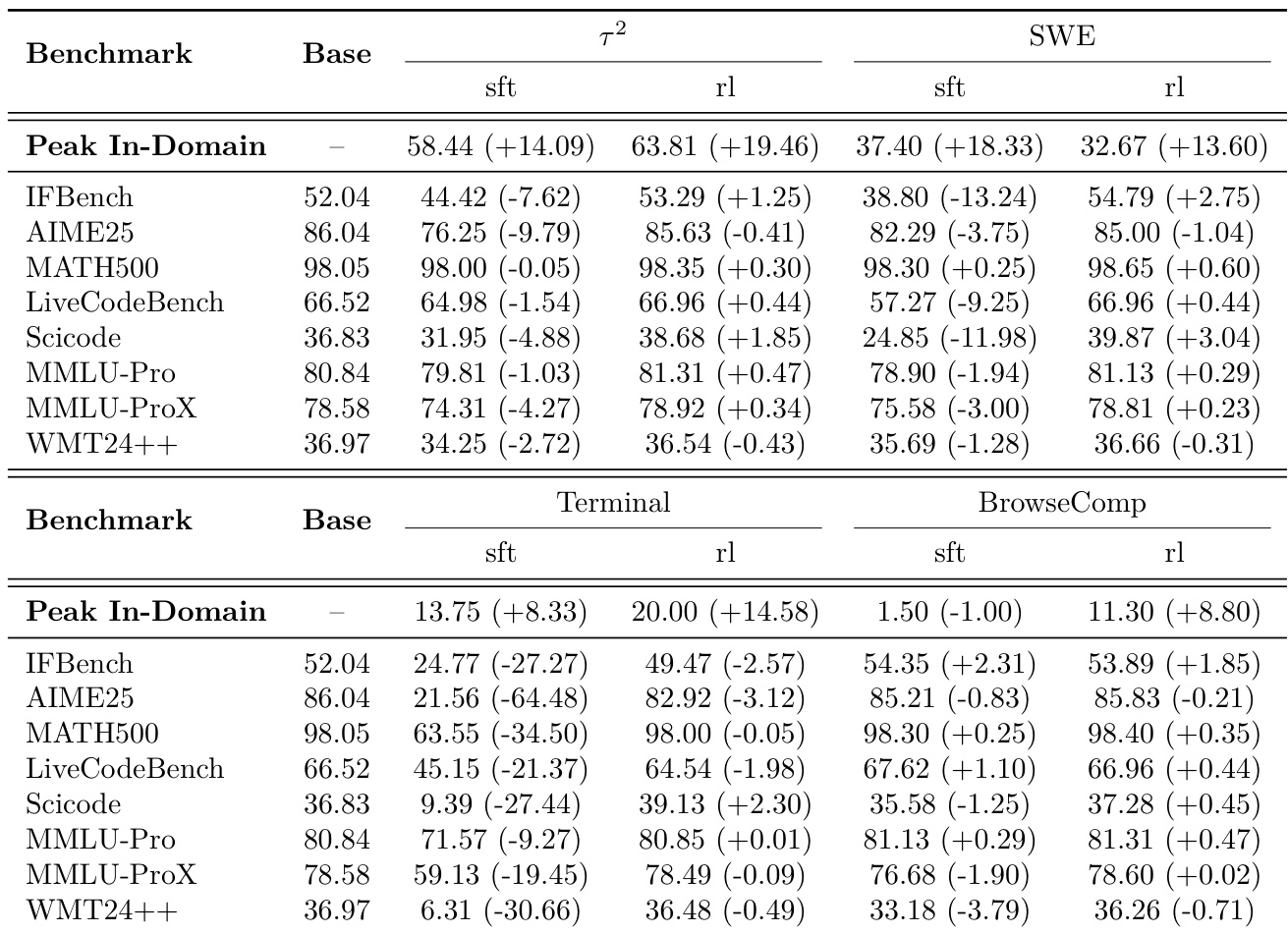
The results compare the performance of supervised fine-tuning (SFT) and PivotRL (rl) against a base model across various agentic and out-of-domain benchmarks. While SFT often leads to significant performance degradation in non-agentic tasks, PivotRL maintains stability across different domains. PivotRL achieves higher in-domain accuracy compared to SFT in both the tau-2 and terminal training scenarios. SFT causes substantial performance drops in out-of-domain benchmarks, particularly in the terminal training domain. PivotRL demonstrates superior OOD retention by maintaining performance levels near the base model across most evaluated benchmarks.
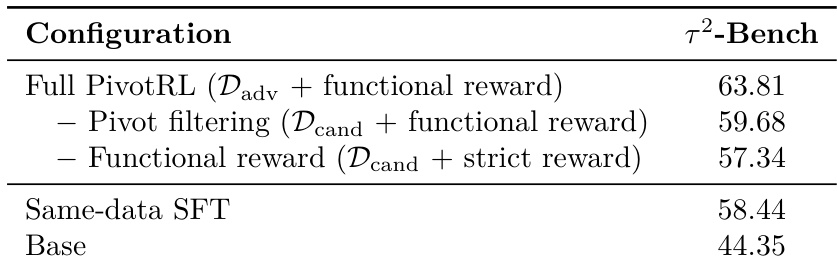
The authors conduct an ablation study on the tau^2-Bench to evaluate the necessity of different PivotRL components. The results demonstrate that the complete framework outperforms both the base model and standard supervised fine-tuning. The full PivotRL configuration achieves the highest performance on the benchmark. Removing pivot filtering or switching to strict rewards leads to decreased accuracy compared to the full method. Both pivot filtering and functional rewards are necessary to exceed the performance of same-data SFT.
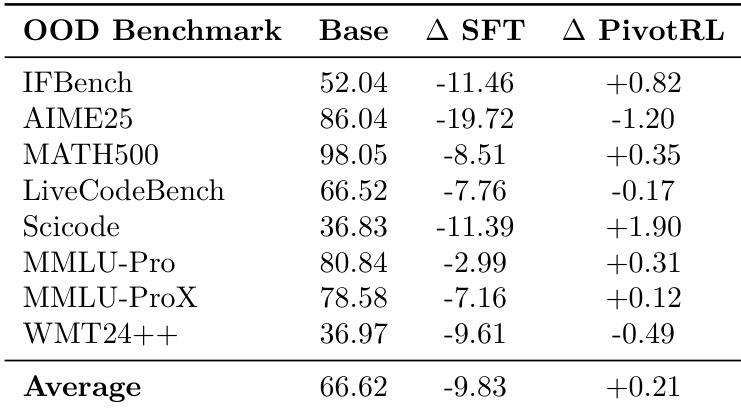
The authors compare the impact of supervised fine-tuning (SFT) and PivotRL on out-of-domain (OOD) performance across various benchmarks. Results show that while SFT leads to a broad decline in performance across all tested benchmarks, PivotRL maintains performance levels close to the base model. SFT causes a consistent decrease in accuracy across all evaluated OOD benchmarks. PivotRL demonstrates much higher OOD retention, with average changes remaining near zero. PivotRL avoids the significant performance regressions seen in SFT, particularly in specialized reasoning and coding benchmarks.
The authors evaluate different pivot selection strategies for training on the τ2-Bench across three specific domains. Results show that more selective filtering of pivot candidates leads to higher average performance compared to both the base model and standard supervised fine-tuning. The low-reward-mean pivot strategy achieves the highest average performance across the tested domains. Using random pivots provides an improvement over supervised fine-tuning. All pivot-based methods outperform the base model in the tested agentic tasks.
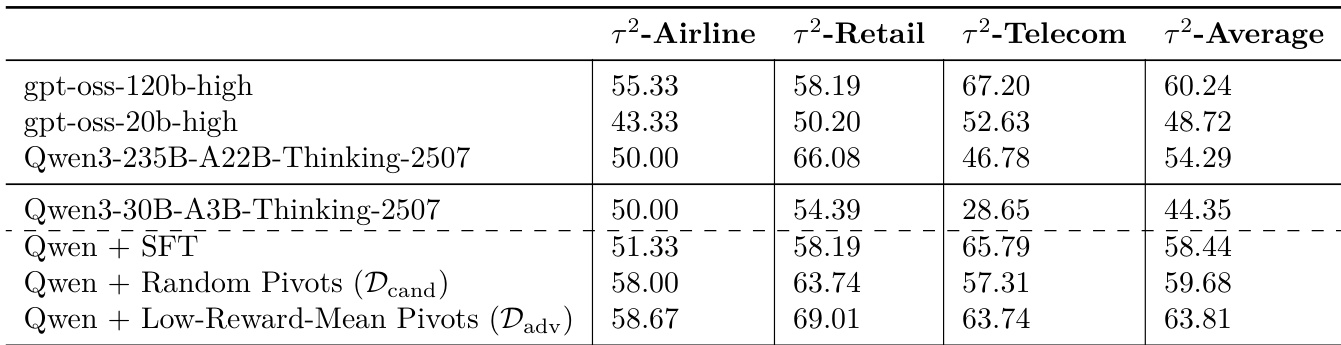
The authors compare the performance of PivotRL, SFT, and a Base model across several agentic benchmarks. Results show that PivotRL achieves higher accuracy than SFT in most tested domains, particularly in web browsing and terminal control. PivotRL outperforms SFT on the tau-2-Bench and Terminal-Bench benchmarks. The largest performance gain for PivotRL compared to SFT is observed on the BrowseComp benchmark. In the SWE-Bench Verified task, SFT demonstrates higher accuracy than PivotRL.
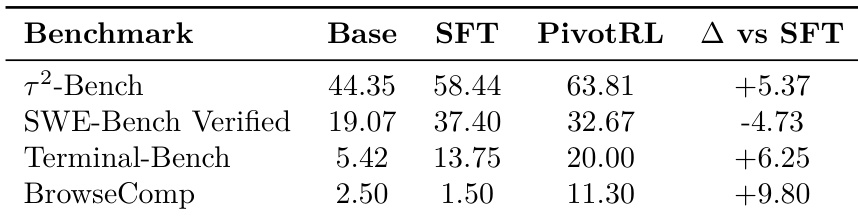
The experiments compare PivotRL against supervised fine-tuning (SFT) and base models across various agentic and out-of-domain benchmarks to evaluate task performance and knowledge retention. The results demonstrate that while SFT often causes significant performance degradation in non-agentic and out-of-domain tasks, PivotRL maintains stability and achieves superior accuracy in agentic domains. Ablation and selection studies further reveal that the full PivotRL framework, particularly when utilizing selective pivot filtering and functional rewards, is essential for maximizing performance and preventing regression.