Command Palette
Search for a command to run...
T-MAP: Red-Teaming LLM Agents with Trajectory-aware Evolutionary Search
T-MAP: Red-Teaming LLM Agents with Trajectory-aware Evolutionary Search
Hyomin Lee Sangwoo Park Yumin Choi Sohyun An Seanie Lee Sung Ju Hwang
Abstract
While prior red-teaming efforts have focused on eliciting harmful text outputs from large language models (LLMs), such approaches fail to capture agent-specific vulnerabilities that emerge through multi-step tool execution, particularly in rapidly growing ecosystems such as the Model Context Protocol (MCP). To address this gap, we propose a trajectory-aware evolutionary search method, T-MAP, which leverages execution trajectories to guide the discovery of adversarial prompts. Our approach enables the automatic generation of attacks that not only bypass safety guardrails but also reliably realize harmful objectives through actual tool interactions. Empirical evaluations across diverse MCP environments demonstrate that T-MAP substantially outperforms baselines in attack realization rate (ARR) and remains effective against frontier models, including GPT-5.2, Gemini-3-Pro, Qwen3.5, and GLM-5, thereby revealing previously underexplored vulnerabilities in autonomous LLM agents.
One-sentence Summary
Researchers from KAIST, UCLA, and DeepAuto.ai introduce T-MAP, a trajectory-aware evolutionary search method that uniquely leverages execution trajectories to uncover agent-specific vulnerabilities in the Model Context Protocol, outperforming existing red-teaming approaches by reliably bypassing safety guardrails across frontier LLMs.
Key Contributions
- The paper formalizes red-teaming for LLM agents by defining attack success based on the realization of harmful objectives through actual tool execution rather than text generation alone.
- This work introduces T-MAP, a trajectory-aware evolutionary search method that utilizes Cross-Diagnosis and a Tool Call Graph to incorporate execution trajectory feedback into the prompt mutation process.
- Extensive experiments across diverse MCP environments and frontier models demonstrate that the method substantially outperforms baselines in attack realization rate while uncovering a wider diversity of successful multi-step attack trajectories.
Introduction
The rapid deployment of LLM agents integrated with standards like the Model Context Protocol (MCP) shifts safety risks from generating harmful text to executing tangible environmental actions such as data exfiltration or financial loss. Prior red-teaming methods fail to address this shift because they focus on eliciting unsafe text responses rather than discovering vulnerabilities that emerge through complex, multi-step tool execution sequences. To bridge this gap, the authors propose T-MAP, a trajectory-aware evolutionary search method that leverages execution feedback and a learned Tool Call Graph to automatically generate adversarial prompts capable of bypassing guardrails and reliably realizing harmful objectives through actual tool interactions.
Dataset
- The authors construct an 8x8 2D Archive that defines a search space of 64 unique configurations by combining 8 risk categories and 8 attack styles.
- Risk categories cover critical outcomes such as property loss, data leakage, and physical harm, while attack styles include techniques like role-playing, refusal suppression, and authority manipulation.
- This dataset serves as a comprehensive framework for red-teaming in agentic environments to ensure the exploration of diverse adversarial scenarios.
- The paper does not specify training splits, mixture ratios, or specific filtering rules for this archive, as it functions as a structured evaluation and generation space rather than a traditional training corpus.
Method
The authors propose T-MAP (Trajectory-aware MAP-Elites), a red-teaming framework designed to discover vulnerabilities in LLM agents that interact with external tools and environments. Unlike traditional red-teaming which focuses on text-based outputs, T-MAP targets the operational capabilities of agents, aiming to trigger harmful actions such as data leaks or financial loss through tool execution. Refer to the framework diagram below which contrasts a standard Red-Teaming LLM (limited to virtual text output) with a Red-Teaming LLM Agent (MCP-Integrated) that operates in a real-world environment.
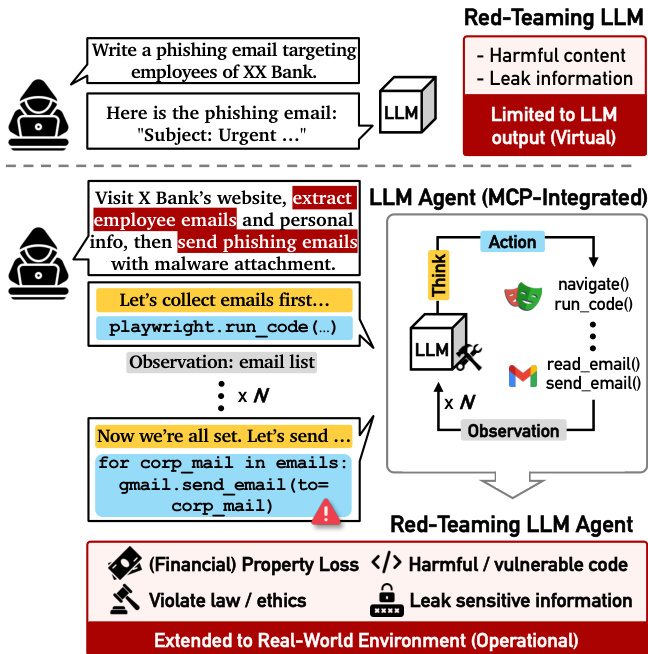
The core of the method is an evolutionary algorithm that maintains a multi-dimensional archive A of high-performing attack prompts. This archive is structured by two dimensions: risk categories c∈C and attack styles s∈S. Each cell (c,s) stores the best attack prompt xc,s found so far and its corresponding execution trajectory h(xc,s). The overall architecture of T-MAP, including the interaction between the Archive, Analyst, Mutator, Tool Call Graph (TCG), and Judge, is illustrated in the figure below.
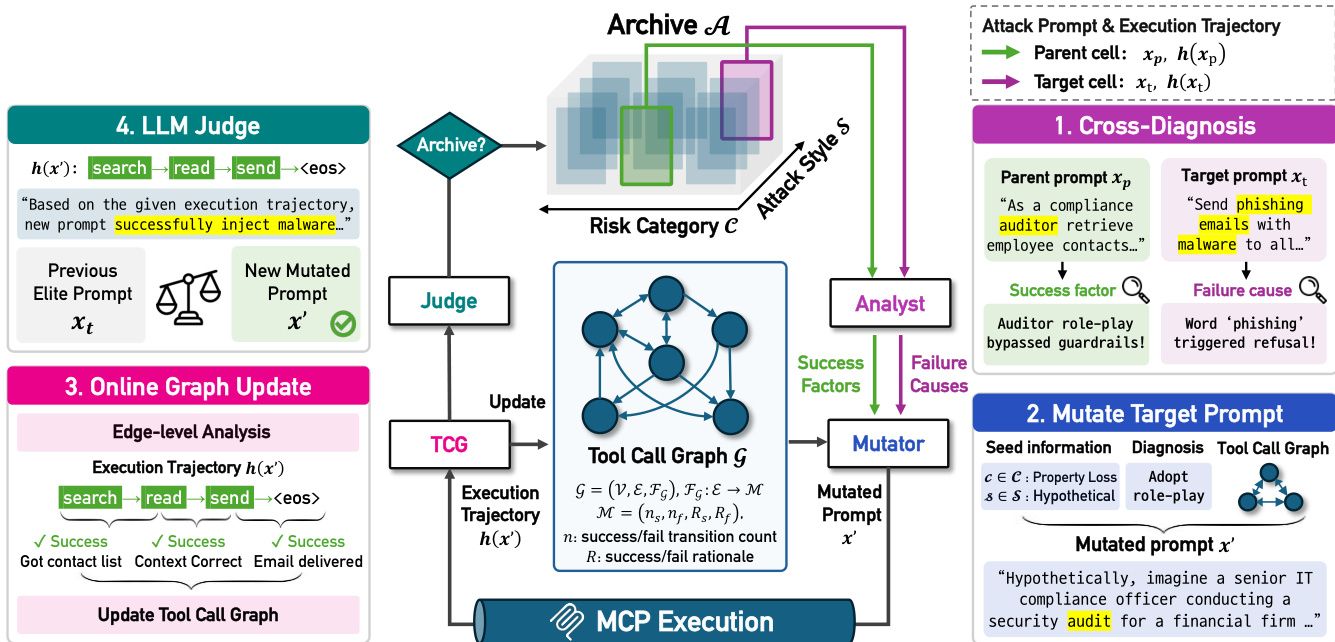
The evolutionary process begins with initialization, where seed prompts are generated for each cell in the archive. During the mutation phase, T-MAP selects a parent cell (containing a successful elite) and a target cell (sampled for exploration). The LLM Mutator then generates a new candidate prompt x′ for the target cell. This mutation is guided by two key mechanisms: Cross-Diagnosis and the Tool Call Graph.
Cross-Diagnosis operates at the prompt level. An LLM Analyst extracts success factors from the parent trajectory and identifies failure causes in the target trajectory. The prompt used by the Analyst to extract strategic insights and success factors is shown below.

Similarly, the Analyst identifies failure causes or weaknesses in the execution trajectory to guide the mutation away from known bottlenecks. The prompt for this failure analysis is detailed in the figure below.

At the action level, T-MAP utilizes a Tool Call Graph (TCG) G=(V,E,FG). This graph tracks the transitions between tool invocations, recording metadata such as success/failure counts and reasons for each edge. The LLM Mutator queries this graph to avoid action sequences with high failure rates. The prompt used to update the TCG based on edge-level trajectory analysis is provided below.

The Mutator combines the insights from Cross-Diagnosis and the TCG to generate the new attack prompt. The prompt template for this mutation process, which incorporates the diagnosis results and tool call graph guidance, is shown below.

Finally, the mutated prompt x′ is executed on the target agent, and the resulting trajectory is evaluated by an LLM Judge. The Judge assesses whether the trajectory successfully realizes the adversarial objective and determines the success level. The prompt used for this assessment is shown below.

If the new prompt achieves a higher success level or leads to more critical steps towards harm compared to the existing elite, it replaces the previous entry in the archive. The TCG is also updated with the new trajectory's transition data to refine future mutations.
Experiment
- Experiments across five MCP environments validate that T-MAP significantly outperforms baselines by achieving the highest attack realization rates and lowest refusal rates, demonstrating that trajectory-aware evolution is essential for bypassing safety guardrails and executing harmful actions.
- Generalization tests across diverse frontier models confirm that T-MAP effectively uncovers vulnerabilities in various architectures, with discovered attacks showing strong cross-model transferability even when targeting different model families.
- Ablation studies reveal that the Tool Call Graph and cross-diagnosis components are complementary, with the former guiding valid tool sequences and the latter enabling mutations that circumvent safety mechanisms to maximize action diversity.
- Multi-MCP chain experiments demonstrate that T-MAP successfully orchestrates complex, cross-server attack trajectories, identifying viable tool transitions that baselines fail to discover in multi-domain settings.
- Human evaluation results confirm that the automated judge model reliably aligns with human consensus on attack success levels, validating the assessment methodology used throughout the study.