Command Palette
Search for a command to run...
Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
Ego2Web: A Web Agent Benchmark Grounded in Egocentric Videos
Shoubin Yu Lei Shu Antoine Yang Yao Fu Srinivas Sunkara Maria Wang Jindong Chen Mohit Bansal Boqing Gong
Abstract
Multimodal AI agents are increasingly automating complex real-world workflows that involve online web execution. However, current web-agent benchmarks suffer from a critical limitation: they focus entirely on web-based interaction and perception, lacking grounding in the user's real-world physical surroundings. This limitation prevents evaluation in crucial scenarios, such as when an agent must use egocentric visual perception (e.g., via AR glasses) to recognize an object in the user's surroundings and then complete a related task online (e.g., making a purchase related to that object). To address this gap, we introduce Ego2Web, the first benchmark designed to bridge egocentric video perception and web agent execution. Ego2Web pairs real-world first-person video recordings with web tasks that require visual understanding, web task planning, and interaction in an online environment for successful completion. We utilize an automatic data-generation pipeline combined with human verification and refinement to curate well-constructed, high-quality video-task pairs across diverse web task types, including e-commerce, navigation, media retrieval, knowledge lookup, etc. To facilitate accurate and scalable evaluation for our benchmark, we also develop a novel LLM-as-a-Judge automatic evaluation method, Ego2WebJudge, which achieves approximately 84% agreement with human judgment, substantially higher than existing evaluation methods. Experiments with diverse state-of-the-art agents on our Ego2Web benchmark show that their performance is still weak, with substantial headroom across all task categories. We also conduct a comprehensive ablation study on task design, highlighting the necessity of accurate video understanding in the proposed task and the limitations of current agents. We hope Ego2Web can be a critical new resource for developing truly capable AI assistants that can seamlessly see, understand, and act across the physical and digital worlds.
One-sentence Summary
To bridge the gap between egocentric video perception and web agent execution, researchers introduce Ego2Web, a benchmark that pairs real-world first-person recordings with online tasks across diverse categories such as e-commerce and navigation, and evaluates performance using Ego2WebJudge, an LLM-as-a-Judge method that achieves approximately 84% agreement with human judgment.
Key Contributions
- The paper introduces Ego2Web, the first benchmark designed to bridge egocentric video perception with online web agent execution by pairing real-world first-person video recordings with interactive web tasks.
- This work presents an automatic data-generation pipeline combined with human verification to curate high-quality video-task pairs across diverse categories such as e-commerce, navigation, and media retrieval.
- The study develops Ego2WebJudge, a novel multimodal LLM-as-a-Judge evaluation framework that utilizes grounded visual cues from egocentric videos to achieve approximately 84% agreement with human judgment.
Introduction
As multimodal AI agents move toward automating complex real-world workflows, there is a growing need for agents that can bridge the gap between physical perception and digital action. Current egocentric video benchmarks focus solely on perception and reasoning, while existing web-agent benchmarks remain purely digital and lack grounding in a user's physical surroundings. This disconnect prevents the evaluation of essential scenarios where an agent must use first-person visual input, such as from AR glasses, to inform online tasks like e-commerce or information retrieval. The authors address this gap by introducing Ego2Web, the first benchmark that pairs real-world egocentric video recordings with interactive web tasks. To ensure scalable and accurate assessment, they also contribute Ego2WebJudge, a novel LLM-as-a-Judge framework that incorporates grounded visual cues from the videos to evaluate task success.
Dataset

-
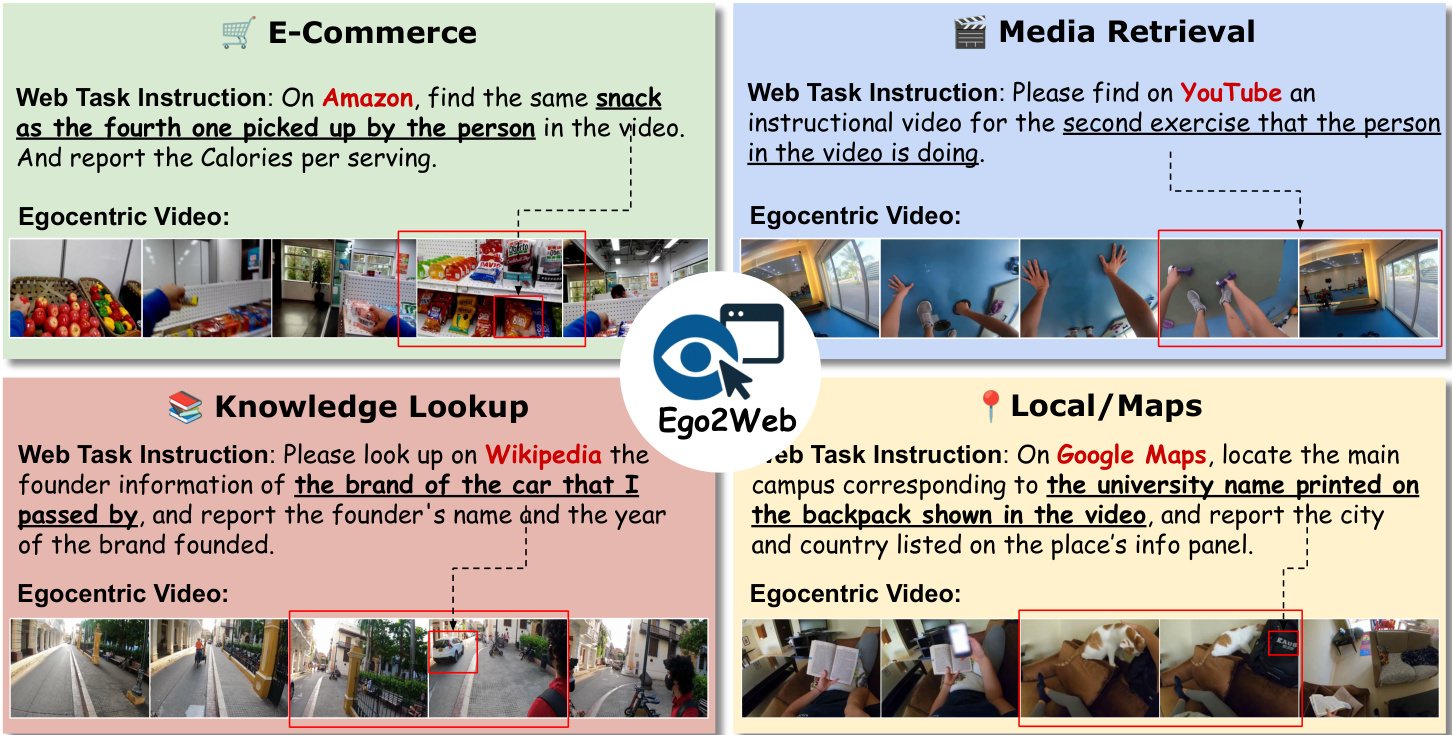
Dataset Composition and Sources: The authors developed Ego2Web, a benchmark consisting of 500 verified video-task pairs. The dataset is built from a curated pool of egocentric videos sourced from public datasets, covering diverse environments such as households, shopping centers, travel locations, and offices.
-
Key Details and Subsets: The dataset spans multiple popular website domains, including e-commerce, media retrieval, knowledge bases, and local or map services. To ensure task relevance, the authors specifically selected active, popular websites like Amazon, Wikipedia, and YouTube for task synthesis.
-
Data Processing and Metadata Construction: The authors employed a semi-automatic pipeline to link physical perception with digital actions:
- Visual Parsing: A frozen Multimodal Large Language Model (Qwen3-VL) processes video clips to extract structured, detailed visual metadata, creating a comprehensive video profile.
- Task Synthesis: An LLM (GPT-5) uses the extracted visual metadata and predefined websites to generate realistic task instructions that require mapping visual cues (such as a specific brand or color) to web-based actions.
- Human Refinement: Human annotators verify and edit the generated pairs based on three criteria: visual grounding (the task must depend on video content), web feasibility (the task must be executable on the site), and instruction quality.
-
Usage and Task Design: The dataset is designed to evaluate multimodal agents on two primary fronts: visual perceptual understanding (extracting semantic information like brands or colors from the video) and web execution reasoning (planning and executing browser actions like searching, scrolling, or clicking). Success is determined by whether the agent's final web state matches the intended goal, as verified by human annotators or an LLM-based evaluator.
Method
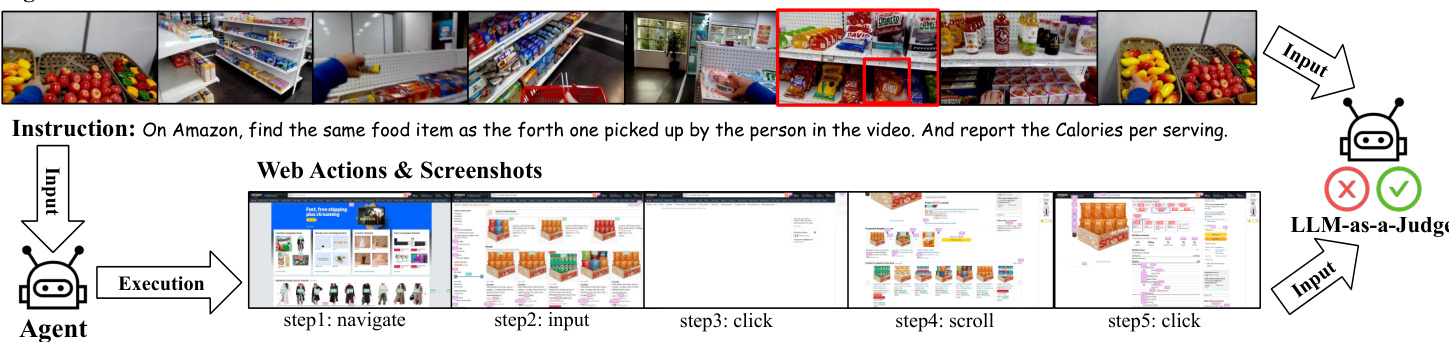
To evaluate the performance of agents in complex web-based tasks derived from egocentric videos, the authors introduce Ego2WebJudge. This evaluation framework performs a binary classification to determine the outcome O∈{Success,Failure}, represented by the following equation:
O=Ego2WebJudge(I,v,A,S)As shown in the figure below, the dataset consists of various web task instructions paired with egocentric video segments, covering domains such as e-commerce, media retrieval, and knowledge lookup.
The Ego2WebJudge pipeline operates through three distinct stages to ensure a robust and context-aware assessment.
The first stage is Key-Point Identification. Given a task instruction I, a Large Language Model (LLM) is utilized to extract critical key points. These key points define the specific requirements for success, such as identifying a particular item, location, or attribute. Since Ego2Web instructions often require multi-step reasoning, distilling the instruction into explicit key points provides the necessary prior knowledge for the subsequent evaluation steps.
The second stage is Key Screenshot Selection. Because web trajectories can be lengthy and contain many irrelevant steps, such as loading pages or UI errors, the authors implement a selection mechanism to prevent context overflow in Multimodal LLMs (MLLMs). An MLLM summarizes each screenshot si and assigns a relevance score on a scale of 1 to 5. Only screenshots that exceed a predefined relevance threshold δ are retained. This ensures the model focuses on essential intermediate steps.
The third and final stage is Final Outcome Judgment. In this stage, the MLLM-judge integrates several information streams: the original task instruction, the selected key screenshots, the agent's action history, and the LLM-generated key points. Crucially, the judge also incorporates annotated keyframes extracted from the original egocentric video. These keyframes provide the essential visual perception required to solve the task.
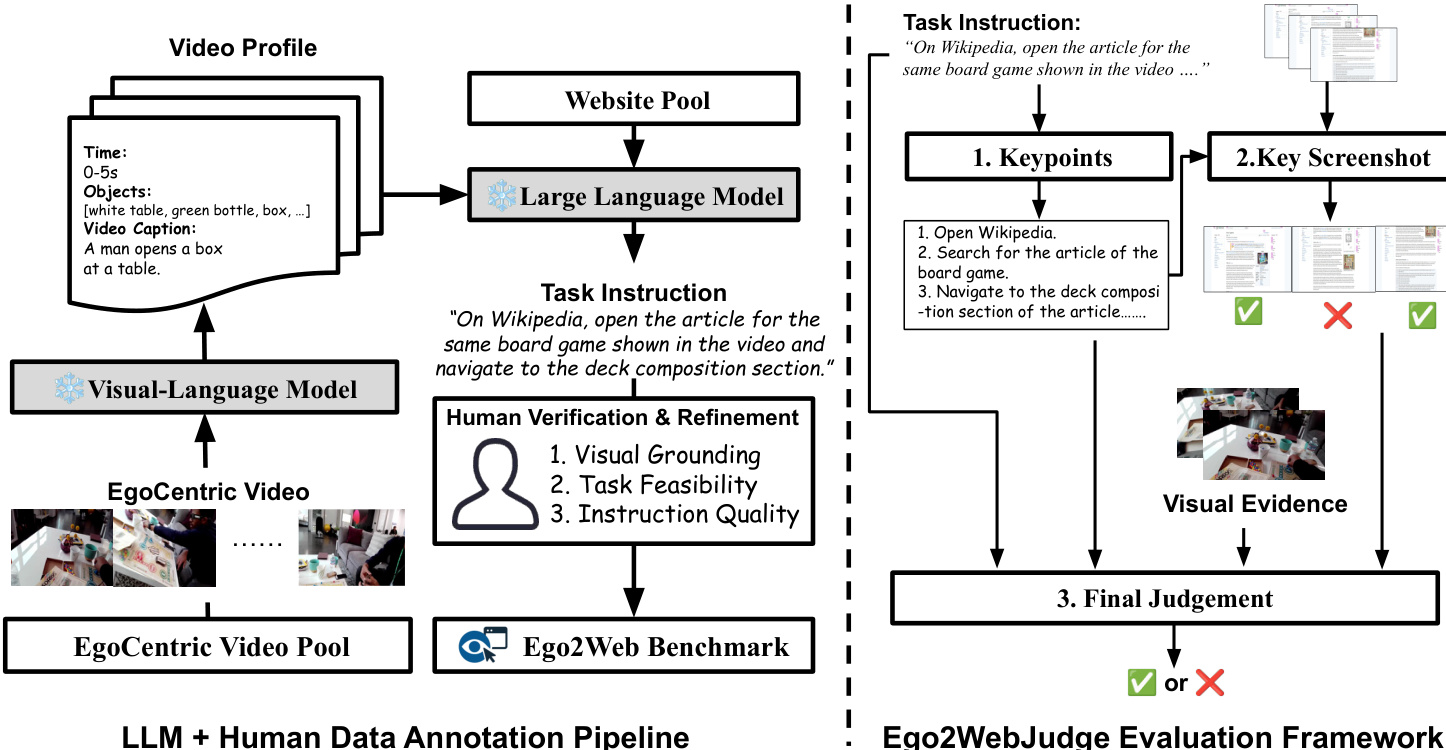
By synthesizing these inputs, the Ego2WebJudge determines whether the agent's final outcome satisfies all identified key points. Furthermore, it verifies whether the web results are visually consistent with the real-world content observed in the video, such as ensuring that objects, scenes, or brands match the environment.

Experiment
The Ego2Web benchmark evaluates the ability of multimodal web agents to perform online tasks that require grounding digital actions in real-world egocentric video context. Experiments across several mainstream agents reveal that direct raw video perception is significantly more effective than relying on textual captions or sparse keyframes, which often lead to information loss. Overall, the results highlight a substantial performance gap in current models due to difficulties in temporal reasoning, object misidentification, and aligning visual cues with web-based information.
The authors evaluate the success rates of various web agents using both human evaluation and an automated framework called Ego2WebJudge with different multimodal LLM backbones. The results demonstrate that the Gemini-based agent achieves the highest performance across all evaluation settings. BU-Gemini-3-Flash consistently outperforms all other tested agents in both human and automatic assessments. Different automatic judges maintain consistent relative rankings of the agents despite varying absolute scores. The performance gap between the top agent's automatic evaluation and human evaluation remains minimal.

The authors evaluate the performance of several web agents across five distinct task domains to assess their ability to handle visually grounded web tasks. Results show that agents utilizing Gemini-based multimodal capabilities consistently achieve higher success rates compared to other tested models. BU-Gemini-3-Flash achieves the highest success rate across all individual task domains and the overall average. Knowledge Lookup emerges as the domain where agents perform most effectively. E-Commerce and Local/Maps tasks present greater challenges for the evaluated agents.

The authors compare the agreement rate between human evaluation and various automatic evaluation methods across several web agents. Results show that the proposed Ego2WebJudge achieves higher agreement with human judgments compared to existing methods like WebVoyager and WebJudge, regardless of the underlying multimodal large language model used. The proposed evaluation framework consistently outperforms prior automatic methods in aligning with human judgments. Higher agreement rates are observed across all tested web agents when using the new evaluation framework. The performance advantage of the new method remains consistent across different base multimodal large language models.

The authors evaluate web agent performance across various task domains using both human assessment and the automated Ego2WebJudge framework. Results indicate that agents powered by Gemini-based multimodal capabilities, specifically BU-Gemini-3-Flash, consistently achieve superior success rates compared to other models. Furthermore, the proposed Ego2WebJudge framework demonstrates a high degree of alignment with human judgments, outperforming existing automated evaluation methods across different model backbones.