Command Palette
Search for a command to run...
Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation
Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation
Brian Chao Lior Yariv Howard Xiao Gordon Wetzstein
Abstract
Diffusion and flow matching models have unlocked unprecedented capabilities for creative content creation, such as interactive image and streaming video generation. The growing demand for higher resolutions, frame rates, and context lengths, however, makes efficient generation increasingly challenging, as computational complexity grows quadratically with the number of generated tokens. Our work seeks to optimize the efficiency of the generation process in settings where the user's gaze location is known or can be estimated, for example, by using eye tracking. In these settings, we leverage the eccentricity-dependent acuity of human vision: while a user perceives very high-resolution visual information in a small region around their gaze location (the foveal region), the ability to resolve detail quickly degrades in the periphery of the visual field. Our approach starts with a mask modeling the foveated resolution to allocate tokens non-uniformly, assigning higher token density to foveal regions and lower density to peripheral regions. An image or video is generated in a mixed-resolution token setting, yielding results perceptually indistinguishable from full-resolution generation, while drastically reducing the token count and generation time. To this end, we develop a principled mechanism for constructing mixed-resolution tokens directly from high-resolution data, allowing a foveated diffusion model to be post-trained from an existing base model while maintaining content consistency across resolutions. We validate our approach through extensive analysis and a carefully designed user study, demonstrating the efficacy of foveation as a practical and scalable axis for efficient generation.
One-sentence Summary
By leveraging human visual acuity through non-uniform token allocation, the proposed Foveated Diffusion method optimizes image and video generation efficiency by assigning higher token density to foveal regions and lower density to the periphery, achieving perceptually indistinguishable results while significantly reducing computational complexity and generation time.
Key Contributions
- The paper introduces Foveated Diffusion, a perceptually motivated framework that optimizes visual generation efficiency by allocating tokens non-uniformly based on a foveation mask. This method concentrates computational resources in high-acuity foveal regions while sparsifying peripheral regions to mimic human visual perception.
- A principled mechanism is developed to construct mixed-resolution tokens directly from high-resolution data, enabling a foveated diffusion model to be post-trained from an existing base model. This approach maintains content consistency across varying resolutions without the need for complex multi-stage pipelines or brittle re-noising strategies.
- Extensive analysis and user studies demonstrate that the framework achieves significant computational savings and reduced generation time while producing results that are perceptually indistinguishable from full-resolution generation. The method also supports saliency-guided image and video generation, where salient objects align with the high-resolution foveal area.
Introduction
As demands for higher resolution and longer context lengths in image and video generation grow, the quadratic computational complexity of Diffusion Transformer (DiT) attention mechanisms becomes a major bottleneck. Prior efficiency methods often treat all spatial regions uniformly or rely on brittle multi-stage pipelines that can cause structural inconsistencies and artifacts. The authors leverage the eccentricity-dependent acuity of human vision to introduce Foveated Diffusion, a framework that allocates higher token density to the foveal region and lower density to the periphery. By developing a principled mixed-resolution tokenization scheme and a post-training strategy, they enable existing models to generate content that is perceptually indistinguishable from full-resolution outputs while achieving significant speedups in both image and video synthesis.
Method
The authors introduce Foveated Diffusion, a framework designed to enable generative models to produce spatially foveated images and videos while significantly reducing token complexity. This approach leverages the principle of foveated rendering, where computational resources are concentrated in high-resolution (HR) foveal regions while peripheral regions are represented at a lower resolution.
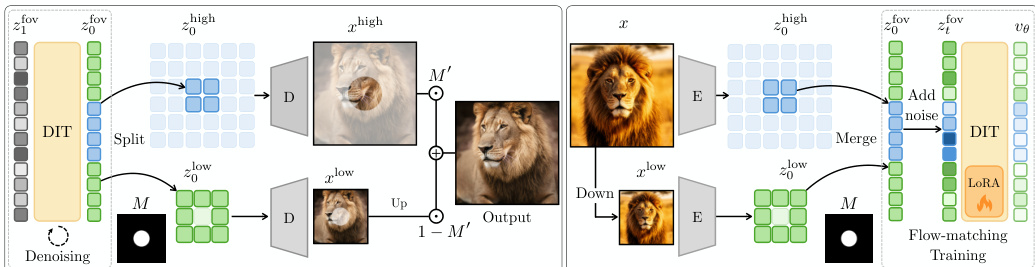
The core of the method lies in Foveated Tokenization. Instead of processing a uniform grid of tokens as standard Diffusion Transformers (DiTs) do, the authors utilize a foveation mask M to define a variable-length token sequence. In this setup, high-resolution tokens are retained in the foveal regions, whereas peripheral regions are represented by a reduced set of tokens. Specifically, a single low-resolution token represents a 2×2 block of high-resolution tokens, resulting in a total sequence length L=m+(h⋅w−m)/4, where m is the number of effective tokens in the mask.
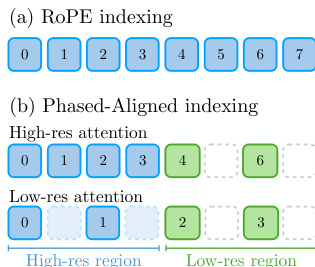
To facilitate this mixed-resolution structure, the authors implement Mixed-Resolution Rotary Positional Embedding (RoPE). Standard RoPE assumes a uniform grid, which is incompatible with the varying token densities in foveated layouts. The authors adapt the indexing by aligning the key RoPE phases with query RoPE phases based on their respective resolutions. As shown in the figure below, when performing high-resolution query attention, low-resolution key tokens are sub-sampled, and for low-resolution queries, high-resolution key tokens are sub-sampled and their indices are normalized to the low-resolution grid.
The generation process, referred to as Foveated Generation, begins by sampling Gaussian noise z1fov in the reduced foveated token space. This sequence is iteratively denoised to produce a clean foveated token sequence z0fov. To reconstruct the final image, the sequence is split into high- and low-resolution components, which are then decoded separately by a VAE decoder. The resulting images are blended using an upsampled foveation mask M′. The complete pipeline for this generation process is illustrated in the framework diagram.

To ensure the model can handle the structural inconsistencies that arise from mixed-resolution denoising, the authors propose a Foveated Training procedure. This post-training method uses Low-Rank Adaptation (LoRA) to adapt pretrained DiTs. During training, a high-resolution token sequence z0high is obtained from the original image, and a low-resolution sequence z0low is obtained by encoding a downsampled version of the image. These are merged into a single, coherent foveated target sequence z0fov based on the mask. The model is then optimized using the standard flow-matching objective, ensuring that the learned velocity field is consistent across both resolution scales.
Experiment
The researchers evaluated the Foveated Diffusion framework through quantitative metrics and a perceptual user study to compare its performance against full-resolution and naïve mixed-resolution baselines in image and video generation. The results demonstrate that the proposed method achieves significant computational speedups while maintaining visual quality and structural consistency comparable to full-resolution generation. Furthermore, the framework shows strong generalization capabilities, successfully adapting to various foveation patterns and enabling saliency-guided or bounding-box-guided generation for applications like immersive gaming and robotics simulation.
The authors compare their foveated video generation method against full high-resolution generation and a naïve mixed-resolution baseline. Results show that the proposed method achieves performance comparable to or better than the full high-resolution baseline across most evaluated metrics. The proposed method outperforms the naïve mixed-resolution baseline in subject consistency, background consistency, motion smoothness, aesthetic quality, and image quality. The framework maintains high levels of consistency and quality that are nearly indistinguishable from full high-resolution generation. The naïve mixed-resolution baseline exhibits higher dynamic degree but lower performance in almost all other key generative metrics.

The authors conducted a perceptual user study using a Two-Alternative Forced Choice paradigm to compare their method against full high-resolution generation and a naïve mixed-resolution baseline. Results indicate that the proposed method is perceptually indistinguishable from full high-resolution generation while being significantly preferred over the naïve baseline. The proposed method achieves perceptual parity with full high-resolution generation, as evidenced by the lack of statistical significance in preference between them. The method is strongly preferred over the naïve mixed-resolution baseline due to the latter's visual artifacts. Statistical tests confirm that the preference for the proposed method over the naïve baseline is highly significant.

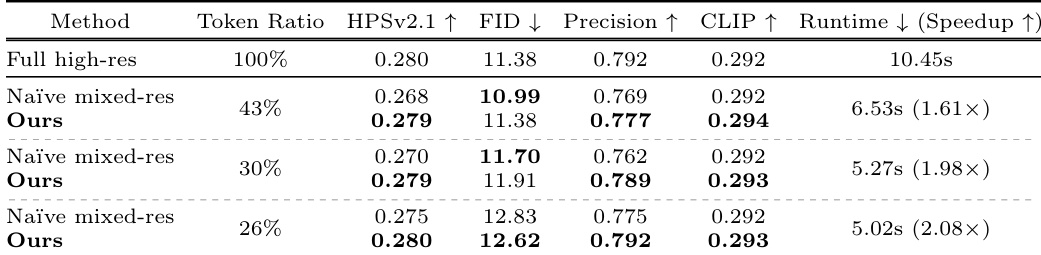
The authors compare their Foveated Diffusion method against a naïve mixed-resolution baseline and full high-resolution generation across various token ratios. Results show that the proposed method maintains high perceptual quality and prompt alignment while significantly reducing runtime compared to full-resolution generation. The proposed method achieves performance comparable to full high-resolution generation in terms of human preference and precision. Foveated Diffusion provides substantial speedups over full-resolution generation as the token ratio decreases. The method consistently outperforms the naïve mixed-resolution baseline in human preference and prompt alignment metrics.
The authors evaluate their foveated video generation method against full high-resolution generation and a naïve mixed-resolution baseline through quantitative metrics, perceptual user studies, and varying token ratio analyses. The results demonstrate that the proposed method achieves visual quality and consistency nearly indistinguishable from full high-resolution generation while significantly outperforming the naïve baseline. Furthermore, the framework provides substantial computational speedups and maintains high prompt alignment across different token ratios.