Command Palette
Search for a command to run...
MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
Abstract
Recent progress in deep research systems has been impressive, but evaluation still lags behind real user needs. Existing benchmarks predominantly assess final reports using fixed rubrics, failing to evaluate the underlying research process. Most also offer limited multimodal coverage, rely on synthetic tasks that do not reflect real-world query complexity, and cannot be refreshed as knowledge evolves. To address these gaps, we introduce MiroEval, a benchmark and evaluation framework for deep research systems. The benchmark comprises 100 tasks (70 text-only, 30 multimodal), all grounded in real user needs and constructed via a dual-path pipeline that supports periodic updates, enabling a live and evolving setting. The proposed evaluation suite assesses deep research systems along three complementary dimensions: adaptive synthesis quality evaluation with task-specific rubrics, agentic factuality verification via active retrieval and reasoning over both web sources and multimodal attachments, and process-centric evaluation audits how the system searches, reasons, and refines throughout its investigation. Evaluation across 13 systems yields three principal findings: the three evaluation dimensions capture complementary aspects of system capability, with each revealing distinct strengths and weaknesses across systems; process quality serves as a reliable predictor of overall outcome while revealing weaknesses invisible to output-level metrics; and multimodal tasks pose substantially greater challenges, with most systems declining by 3 to 10 points. The MiroThinker series achieves the most balanced performance, with MiroThinker-H1 ranking the highest overall in both settings. Human verification and robustness results confirm the reliability of the benchmark and evaluation framework. MiroEval provides a holistic diagnostic tool for the next generation of deep research agents.
One-sentence Summary
The MiroMind Team introduces MiroEval, a dynamic benchmark for deep research agents that uniquely evaluates adaptive synthesis, agentic factuality, and research processes across text and multimodal tasks, revealing that process quality predicts outcomes while exposing significant challenges in multimodal reasoning.
Key Contributions
- The paper introduces MiroEval, a benchmark comprising 100 tasks grounded in real user needs and constructed through curated authentic queries and an automated pipeline based on real-time web trends to ensure temporal relevance.
- A multi-layered evaluation framework is presented that assesses deep research agents through adaptive synthesis quality rubrics, agentic factuality verification against live sources, and process-centric audits of research trajectories across five intrinsic dimensions.
- Experiments across 13 leading systems demonstrate that process quality serves as a reliable predictor of overall outcomes while revealing weaknesses invisible to output-level metrics, such as insufficient analytical depth and significant traceability gaps.
Introduction
The rapid shift from passive text generation to agentic systems capable of autonomous deep research has created a critical need for reliable evaluation in high-stakes domains like finance and healthcare. Current benchmarks fall short because they primarily assess final reports without auditing the underlying research process, lack robust multimodal support, and rely on synthetic queries that fail to capture real-world complexity. To address these gaps, the authors introduce MiroEval, a dynamic benchmark featuring 100 real-world tasks that evaluates systems across three layers: adaptive synthesis quality, agentic factuality verification against live sources, and a process-centric audit of research trajectories.
Dataset
-
Dataset Composition and Sources The authors introduce MiroEval, a benchmark of 100 deep research tasks grounded in real user needs. The dataset is constructed via a dual-path pipeline to ensure diversity and temporal relevance, comprising 70 text-only queries and 30 multimodal queries that span 12 domains and 10 task types.
-
Key Details for Each Subset
- User-Derived Subset (65 queries): This set includes 35 text-only and 30 multimodal tasks inspired by patterns from internal system testing. It covers all 8 evaluation features with balanced difficulty tiers (Easy, Medium, Hard) and requires handling attachments like images, PDFs, and spreadsheets.
- Automated Subset (35 queries): This set consists entirely of text-only tasks generated through a trend-grounded pipeline using real-time web data. It targets 12 topics and 36 subtopics to ensure the queries reflect current events and require external investigation beyond parametric knowledge.
-
Data Usage and Processing The benchmark serves as a holistic evaluation framework rather than a training set, assessing 13 systems across three dimensions: adaptive synthesis quality, agentic factuality verification, and process-centric auditing. The authors employ a three-stage filtering process for the automated subset, including search validation, deep-research necessity checks, and inverse quality assessment to ensure queries cannot be answered by the model alone.
-
Privacy, Metadata, and Construction Strategies
- Privacy-Preserving Rewriting: No original user queries are used directly. The authors apply strict anonymization to replace all named entities with realistic substitutes and filter out sensitive content before rewriting.
- Metadata Construction: Each query is annotated with domain labels, task types, and source-specific metadata such as feature vectors, difficulty tiers, and baseline quality scores.
- Temporal Refresh: The dual-path design allows for periodic re-execution, enabling the benchmark to incorporate new user patterns and latest web trends to prevent staleness.
Method
The MiroEval framework establishes a multi-layered, agentic evaluation pipeline to provide a rigorous diagnostic of deep research systems. This methodology decouples the research artifact from the underlying investigative procedure, allowing for a holistic assessment across three critical dimensions. The framework dynamically constructs evaluation rubrics tailored to the specific constraints and modalities of each task.
The evaluation pipeline is structured into three main components as illustrated in the figure below:
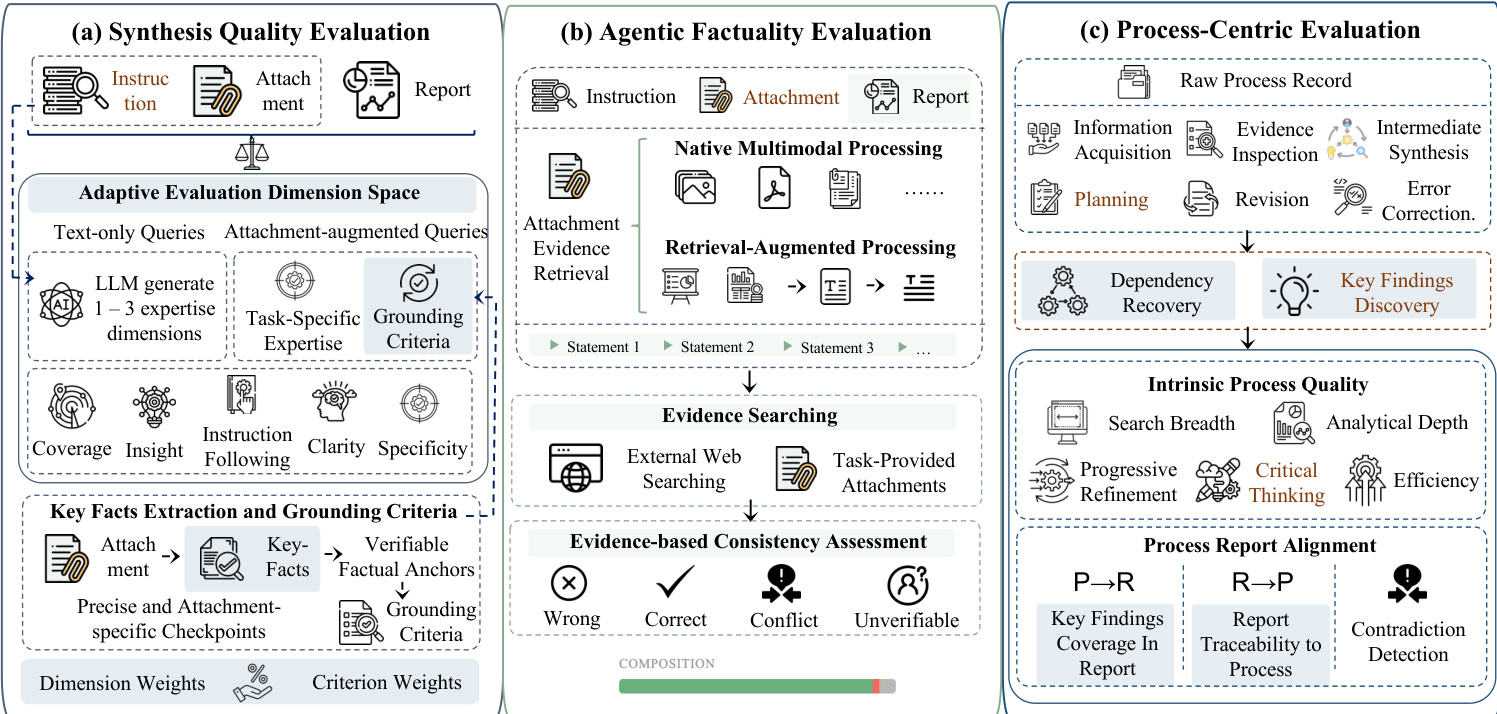
Comprehensive Adaptive Synthesis Quality Evaluation Deep research systems generate long-form reports through multi-step retrieval and reasoning. To capture synthesis quality across varying domains and modalities, the framework employs an adaptive evaluation dimension space D=Dfixed∪Ddynamic(Q). The fixed component includes universal aspects such as Coverage, Insight, and Clarity. The dynamic component adapts to the query type. For text-only queries, an LLM generates 1–3 task-specific expertise dimensions. For attachment-augmented queries, a Grounding dimension is added to assess whether reports faithfully leverage provided materials. An upstream module extracts key facts from attachments to form verifiable factual anchors, which guide the generation of precise grounding criteria. The evaluator derives dimension-level weights Wd and criterion-level weights wd,c to compute the final quality score: Squality=∑d∈DWd∑cwd,csd,c where sd,c is the score assigned by the LLM for a specific criterion.
Agentic Factuality Evaluation This component assesses whether claims in the generated report are supported by reliable evidence from heterogeneous sources. The system decomposes the report into a set of verifiable statements S(Q,R). For each statement, an evaluation agent retrieves supporting or refuting evidence from external web resources and task-provided attachments. The framework supports multimodal attachment querying through Native Multimodal Processing for directly interpretable formats and Retrieval-Augmented Processing for formats requiring segmentation. The agent evaluates the consistency between each statement and its evidence set, assigning a factuality label ψ(s)∈{RIGHT,WRONG,CONFLICT,UNKNOWN}. The CONFLICT label explicitly captures cases where evidence from different sources leads to inconsistent conclusions.
Process-Centric Evaluation Beyond the final artifact, the framework evaluates the quality of the underlying research process. The raw process record is transformed into a structured representation of atomic units, such as information acquisition and planning. Intrinsic process quality is evaluated along dimensions including Search Breadth, Analytical Depth, Progressive Refinement, Critical Thinking, and Efficiency. Furthermore, the framework evaluates the alignment between process-level key findings and report-level key findings. This includes Process→Report (P→R) checks to ensure findings are realized in the report, Report→Process (R→P) checks to verify report conclusions are supported by the process, and Contradiction Detection to assess how conflicts are handled. The overall process score is defined as: Sprocess=αSintrinsic(P)+(1−α)Salign(P,R) where Sintrinsic denotes the intrinsic process quality score and Salign denotes the alignment score.
Experiment
- Evaluated 13 deep research systems across text-only and multimodal settings to validate that process quality reliably predicts overall outcome, revealing that strong research processes correlate with better synthesis and factuality.
- Demonstrated that synthesis quality and factuality are distinct capabilities, showing that polished reports do not guarantee factual accuracy and that systems often trade analytical depth for factual precision or vice versa.
- Identified that multimodal tasks significantly degrade performance, particularly in synthesis and process dimensions, while factual precision remains relatively stable, highlighting visual understanding as a primary bottleneck.
- Revealed that current systems struggle with analytical depth and efficiency, often retrieving broadly but failing to investigate deeply, and exhibit a traceability gap where report content frequently cannot be traced back to the research process.
- Confirmed that the MiroThinker series achieves consistent competitiveness across all dimensions by balancing high claim volume with low error rates and maintaining robust performance in both text-only and multimodal environments.
- Validated the evaluation framework through robustness checks and human studies, confirming that automated rankings align with expert judgment and remain stable across different judge models and prompt configurations.