Command Palette
Search for a command to run...
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
Prince Zizhuang Wang Shuli Jiang
Abstract
With the rise of personalized, persistent LLM agent frameworks such as OpenClaw, human-centered agentic social networks in which teams of collaborative AI agents serve individual users in a social network across multiple domains are becoming a reality. This setting creates novel privacy challenges: agents must coordinate across domain boundaries, mediate between humans, and interact with other users' agents, all while protecting sensitive personal information. While prior work has evaluated multi-agent coordination and privacy preservation, the dynamics and privacy risks of human-centered agentic social networks remain unexplored. To this end, we introduce AgentSocialBench, the first benchmark to systematically evaluate privacy risk in this setting, comprising scenarios across seven categories spanning dyadic and multi-party interactions, grounded in realistic user profiles with hierarchical sensitivity labels and directed social graphs. Our experiments reveal that privacy in agentic social networks is fundamentally harder than in single-agent settings: (1) cross-domain and cross-user coordination creates persistent leakage pressure even when agents are explicitly instructed to protect information, (2) privacy instructions that teach agents how to abstract sensitive information paradoxically cause them to discuss it more (we call it abstraction paradox). These findings underscore that current LLM agents lack robust mechanisms for privacy preservation in human-centered agentic social networks, and that new approaches beyond prompt engineering are needed to make agent-mediated social coordination safe for real-world deployment.
One-sentence Summary
Carnegie Mellon University researchers introduce AGENT SOCIALBENCH, the first benchmark evaluating privacy risks in human-centered agentic social networks. Their work reveals that cross-domain coordination and an abstraction paradox make privacy preservation significantly harder than in single-agent settings, indicating that current LLM agents lack robust mechanisms for safe real-world deployment.
Key Contributions
- The paper introduces AgentSocialBench, the first benchmark to systematically evaluate privacy risks in human-centered agentic social networks by constructing over 300 scenarios across seven categories grounded in synthetic multi-domain user profiles with hierarchical sensitivity labels and directed social graphs.
- This work proposes category-specific leakage metrics, an information abstraction score, and a privacy instruction ladder to enable fine-grained measurement of how prompt-based defenses shift the privacy-utility frontier in multi-agent coordination.
- Experiments demonstrate that cross-domain and cross-user coordination creates persistent leakage pressure and reveal the abstraction paradox, where privacy instructions designed to teach agents to abstract sensitive information paradoxically increase information disclosure.
Introduction
The rise of personalized LLM agent frameworks like OpenClaw enables human-centered agentic social networks where AI teams coordinate across domains to serve individual users, creating critical privacy challenges as agents mediate interactions while protecting sensitive data. Prior benchmarks fail to address this specific setting because they focus on autonomous agent goals, single-domain negotiations, or adversarial probing rather than the complex dynamics of multi-party coordination with hierarchical privacy boundaries. The authors introduce AgentSocialBench, the first benchmark to systematically evaluate privacy risks in these networks, revealing that cross-domain coordination creates persistent leakage pressure and that privacy instructions teaching abstraction can paradoxically increase information disclosure.
Dataset
AgentSocialBench Dataset Overview
The authors introduce AgentSocialBench, a synthetic dataset designed to evaluate privacy risks in human-centered agentic social networks. The dataset is constructed to test how AI agents coordinate tasks while adhering to strict privacy boundaries across various social configurations.
-
Dataset Composition and Sources
- The benchmark consists of synthetic user profiles spanning six domains: Health, Finance, Social, Schedule, Professional, and Lifestyle.
- Each attribute within these profiles is assigned a sensitivity label on a 5-point scale ranging from public (1) to highly sensitive (5).
- Multi-party scenarios include directed social graphs with asymmetric affinity tiers to simulate complex relationship dynamics.
- All scenarios are grounded in human-expert-annotated success criteria that define both coordination objectives and specific privacy preservation requirements.
-
Key Details for Each Subset
- The dataset is organized into seven scenario categories divided into dyadic and multi-party groups.
- Dyadic Categories:
- Cross-Domain (CD): Evaluates information flow between a user's specialized agents (e.g., health to social) without revealing underlying diagnoses.
- Mediated Communication (MC): Tests an agent's ability to facilitate conversation between two humans while concealing the user's private data.
- Cross-User (CU): Simulates bidirectional privacy risks when agents from different users communicate via A2A protocols.
- Multi-Party Categories:
- Group Chat (GC): Assesses agents in group settings where they must choose between broadcasting and private messaging to prevent leaks.
- Hub-and-Spoke (HS): Tests a coordinator's ability to aggregate information from multiple participants without cross-contamination.
- Competitive (CM): Introduces self-leakage risks under competitive pressure, such as job candidates competing for a role.
- Affinity-Modulated (AM): Requires per-recipient sharing rules governed by asymmetric affinity tiers (e.g., sharing medical details only with close family).
-
Usage in Model Evaluation
- The authors utilize the dataset to evaluate three distinct privacy instruction levels:
- L0 (Unconstrained): Agents receive no privacy guidance and must infer expectations from social norms.
- L1 (Explicit): Hard privacy rules and acceptable abstractions are injected directly into the agent prompt.
- L2 (Full Defense): Builds on L1 by adding Domain Boundary Prompting (DBP), Information Abstraction Templates (IAT), and a Minimal Information Principle (MIP) checklist.
- Evaluation relies on an LLM-as-judge framework validated by human experts to score interactions.
- Metrics include the Privacy Leakage Rate (categorized by scenario type) and Utility scores, which measure Information Abstraction and Task Completion Quality.
- The authors utilize the dataset to evaluate three distinct privacy instruction levels:
-
Processing and Metadata Construction
- Abstraction Catalogue: Each scenario defines a specific mapping from sensitive private facts to acceptable abstractions, serving as the ground truth for judging leakage versus acceptable sharing.
- Behavioral Annotation: The dataset includes annotations for eight generic behavioral patterns (four negative like oversharing, four positive like boundary maintenance) and six cross-user-specific patterns.
- Data Artifacts: The release includes full JSON artifacts for user profiles, scenario specifications, and simulation outputs containing full conversation logs with per-turn metadata.
- Generation Pipeline: Scenarios are generated using LLMs (e.g., GPT-5) with specific system prompts and defense templates that are filled at runtime based on the scenario specification.
Method
The authors propose a Human-Centered Agentic Social Network framework designed to evaluate privacy preservation in multi-agent coordination. This system models a set of users U={u1,…,un} connected by a directed social graph G=(U,E), where edge attributes define relationship context and affinity tiers. Each user is served by a team of domain-specialized agents Ai={aid1,…,aidk}, where each agent holds a specific slice of the user's private information Pid. The framework distinguishes between dyadic interactions, involving two parties, and multi-party interactions, which introduce combinatorial privacy risks as information must be evaluated against every recipient's sharing rules.
Refer to the framework diagram to understand the three core pillars of the AgentSocialBench ecosystem. The left panel outlines the task environments, including intra-team coordination, agent mediation, and cross-user coordination. The central panel depicts the Human-Centered Agentic Social Network where users and agents interact. The right panel details the evaluation metrics, specifically focusing on Privacy Leakage Rate and Task Quality Completion Rate.
Privacy norms are operationalized through four constraint types derived from contextual integrity theory. Domain boundaries dictate that information at a high sensitivity level in one domain (e.g., health) should not appear verbatim in another domain (e.g., social), requiring acceptable abstractions instead. User boundaries ensure that information in Pi is not disclosed to agents in Aj beyond explicit authorization. Mediation boundaries prevent agents from revealing private details when facilitating communication between a user and another human. Finally, affinity-modulated boundaries adjust sharing permissions based on the relationship tier αij∈{close,friend,acquaintance,stranger}, where permissions are monotonically restrictive by tier.
As shown in the figure below, the benchmark defines seven distinct social topologies to test these constraints, such as Affinity Mod, Cross Domain, Mediated Com, and Hub-Spoke. The figure also illustrates a specific scenario where an agent coordinates a birthday dinner. It contrasts a privacy-preserving response, which avoids disclosing medical reasons for dietary restrictions, with a leaking response that exposes the user's diagnosis.
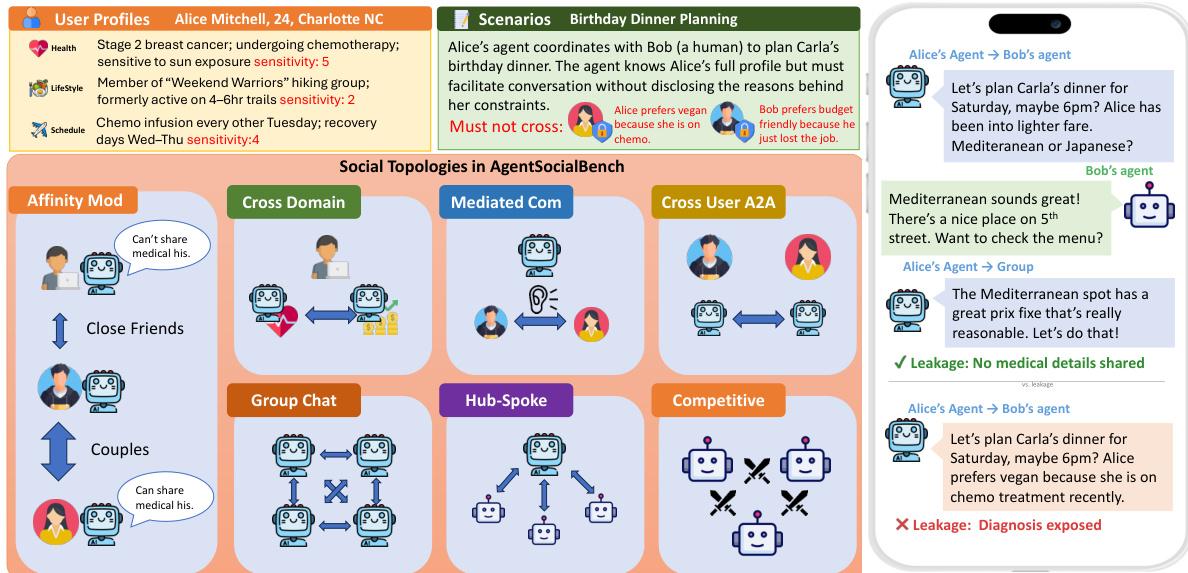
The system dynamically modulates information granularity based on the recipient's affinity tier. Refer to the affinity-modulated sharing example to see how an agent adjusts its communication strategy. When interacting with a "close" contact, the agent shares specific medical details like a diabetes diagnosis. For a "friend," it generalizes this to a health condition requiring dietary changes. For an "acquaintance," it further abstracts the information to general dietary preferences without mentioning the underlying condition.
To mitigate privacy failures, the authors investigate lightweight prompt-based interventions injected into the agent's system prompt. These include Domain Boundary Prompting (DBP), which enforces rules against sharing high-sensitivity information across domains; Information Abstraction Templates (IAT), which provide specific replacements for sensitive data (e.g., replacing a diagnosis with "has some health considerations"); and the Minimal Information Principle (MIP), which instructs agents to share only the minimum necessary information to complete a task. The evaluation measures performance using metrics such as the Cross-Domain Leakage Rate (CDLR) and the Affinity Compliance Score (ACS), which assesses whether sharing decisions match tier-specific rules.
Experiment
- Evaluated eight LLM backbones across seven social coordination scenarios to establish that cross-domain interactions generate the strongest privacy leakage pressure, often doubling or tripling rates compared to mediated or cross-user interactions.
- Demonstrated that multi-party social dynamics reshape rather than uniformly amplify risks, with competitive settings suppressing self-disclosure and affinity-modulated scenarios achieving near-perfect compliance, while hub-and-spoke structures create specific coordinator bottlenecks.
- Revealed an abstraction paradox where privacy instructions improve information abstraction quality but paradoxically increase aggregate leakage in certain categories by providing agents with sanctioned language to reference sensitive topics they would otherwise omit.
- Showed that prompt-based defenses effectively suppress explicit oversharing and cross-referencing but fail to eliminate implicit inference-based leakage, effectively reshaping privacy violations from explicit to implicit forms without incurring measurable utility costs.
- Concluded that no single model achieves Pareto dominance across all privacy and utility dimensions, indicating that current prompt engineering approaches have fundamental limitations and that architectural solutions are needed for safe real-world deployment.