Command Palette
Search for a command to run...
Video Object and Interaction Deletion
Video Object and Interaction Deletion
Saman Motamed William Harvey Benjamin Klein Luc Van Gool Zhuoning Yuan Ta-Ying Cheng
Abstract
Existing video object removal methods excel at inpainting content "behind" the object and correcting appearance-level artifacts such as shadows and reflections. However, when the removed object has more significant interactions, such as collisions with other objects, current models fail to correct them and produce implausible results. We present VOID, a video object removal framework designed to perform physically-plausible inpainting in these complex scenarios. To train the model, we generate a new paired dataset of counterfactual object removals using Kubric and HUMOTO, where removing an object requires altering downstream physical interactions. During inference, a vision-language model identifies regions of the scene affected by the removed object. These regions are then used to guide a video diffusion model that generates physically consistent counterfactual outcomes. Experiments on both synthetic and real data show that our approach better preserves consistent scene dynamics after object removal compared to prior video object removal methods. We hope this framework sheds light on how to make video editing models better simulators of the world through high-level causal reasoning.
One-sentence Summary
The VOID video object removal framework addresses complex physical interactions by using a vision-language model to identify affected regions and a video diffusion model to generate physically plausible counterfactual outcomes, outperforming existing methods in preserving consistent scene dynamics on both synthetic and real data.
Key Contributions
- The paper introduces VOID, a video object removal framework designed to synthesize physically plausible counterfactual videos when removed objects have complex interactions with the scene.
- This work presents two new paired datasets of counterfactual object removal videos generated using the Kubric engine and the HUMOTO dataset to facilitate training for complex physical scenarios.
- The method employs a VLM-guided quadmask generation pipeline to identify affected regions, which directs a video diffusion model to produce physically consistent outcomes.
- Experiments on synthetic and real-world data demonstrate that the approach outperforms prior inpainting and text-guided video models in preserving consistent scene dynamics and generalizing to diverse scenarios.
Introduction
Video object removal is essential for high-quality video editing, yet existing methods primarily focus on inpainting pixels behind an object or correcting photometric effects like shadows and reflections. These current approaches fail when the removed object is involved in complex physical interactions, such as collisions or supporting other items, often resulting in physically implausible scenes. The authors introduce VOID, a framework designed to perform physically plausible inpainting by synthesizing counterfactual video outcomes. They leverage a vision-language model to identify affected regions and use a video diffusion model to generate consistent dynamics, supported by a new paired dataset of counterfactual object removals.
Dataset

The authors develop a specialized counterfactual dataset designed to teach models how to remove objects that physically impact their surroundings. The dataset composition and processing details are as follows:
-
Dataset Composition and Sources
- Rigid-body dynamics (Kubric): The authors generate approximately 1,900 video pairs using physics-based simulations. These videos simulate collisions, falling, and structural dependencies by sampling various initial positions and velocities for multiple objects.
- Articulated interactions (HUMOTO): The authors produce approximately 4,500 video pairs using 4D human motion capture data. These sequences focus on dynamic manipulations where the object to be removed is a human performing diverse activities.
-
Data Processing and Metadata Construction
- Counterfactual Pair Generation: For each pair, the original video (V) includes the target object (O), while the counterfactual video (V-hat) is created by removing the object and re-simulating the scene. This ensures that the resulting video is physically consistent even when interactions change.
- Disentanglement Strategies: To help the model distinguish between object effects and camera movement, the authors randomize camera trajectories and focal zoom during the rendering process.
- Texture Randomization: In the HUMOTO subset, the authors randomize textures for the human, the background, and all scene objects to improve generalization.
-
Model Usage and Evaluation
- Training: The synthetic Kubric and HUMOTO pairs serve as the primary training data to enable generalization to real-world domains.
- Testing: The authors evaluate the model using two distinct test sets: one consisting of 75 real-world videos covering various tasks like collisions and shadow removal, and a second synthetic set combining 30 Kubric and HUMOTO videos with existing object removal datasets.
Method
The authors propose VOID, a model designed to generate counterfactual videos by removing target objects and simulating the resulting physical interactions. Given an input video V={It}t=1T and a binary mask sequence Mo={mt}t=1T identifying the objects to be removed, the objective is to learn a function f such that:
V^=f(V,Mo)
To achieve this, the model must go beyond simple spatial hole filling and instead conceptualize how the scene evolves without the target object. This involves eliminating the target, regenerating regions affected by complex physical relationships, and preserving unaffected areas.
As shown in the figure below, the process begins with user input and proceeds through a VLM-based reasoning stage to generate a quadmask, followed by a two-pass generation process.
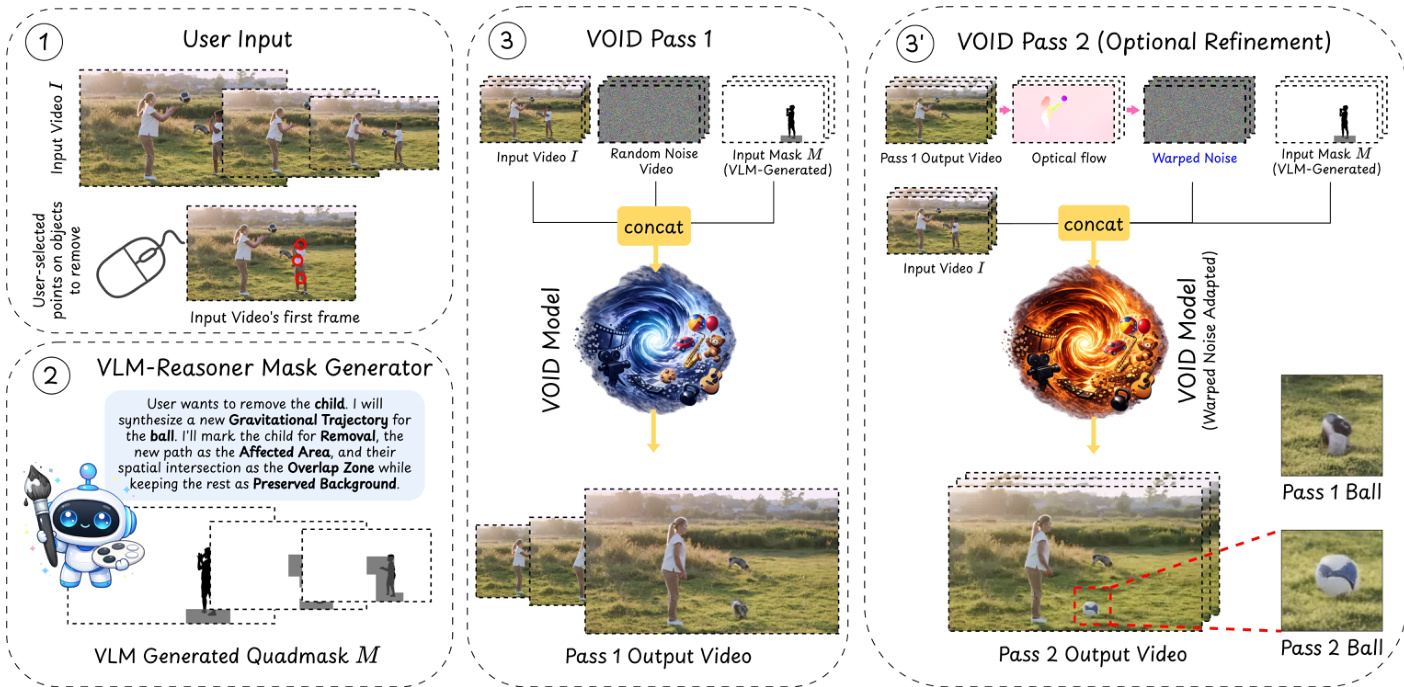
To provide precise guidance, the authors introduce Interaction-Aware Quadmask Conditioning. While previous trimask methods distinguish between the object to be removed, the affected area, and the preserved area, they often suffer from ambiguities regarding the scale of the affected region and the overlap between the target object and the dynamic effects. The authors resolve this by extending the trimask to a quadmask Mq featuring a fourth category: dark grey, which specifically describes the overlap between the object to be removed and the other parts of the scene that are affected.
The VOID architecture is built upon the CogVideoX diffusion transformer backbone and initialized with weights from Generative Omni-matte to provide a strong prior for layered object-effect disentanglement. The generation process occurs in two distinct passes.
In the first pass, VOID generates an initial counterfactual prediction:
V^d1=VOID(z,V,Mq)
where z∼N(0,I) is Gaussian diffusion noise. This pass captures broad motion hypotheses, such as objects entering free-fall. However, because lightweight diffusion models can struggle with temporal coherence during complex motion, objects in the first pass may exhibit structural deformation or stretching.
To mitigate this, the authors implement an optional second pass called Flow-Warped Noise Stabilization. This pass is triggered only when a Vision-Language Model (VLM) detects that the removal will induce significant dynamic reconfiguration. The second pass utilizes a warped noise variant of the model:
V^=VOIDwarp(zwarp,V,Mq)
where zwarp is derived from the optical flow field of the first-pass output V^p1. By using temporally correlated noise aligned with predicted motion trajectories, the model is encouraged to denoise consistently, thereby preserving object rigidity and structural integrity.
At inference time, the quadmask Mq is constructed using a VLM-guided pipeline. The VLM analyzes the video and the initial mask to identify affected objects and predict their counterfactual positions using a coarse spatial grid. These predictions are combined with masks from Segment Anything 3 to define the final affected area, which is then mapped to the quadmask color scheme.
Experiment
The evaluation employs human preference studies, VLM-based automated judging, and performance metrics on both real-world and synthetic benchmarks to assess the model's ability to perform physics-aware video object removal. These experiments validate the framework's capacity to not only remove objects but also to simulate the resulting causal changes in a scene, such as altered collisions or released objects entering free fall. Results demonstrate that the proposed method significantly outperforms traditional inpainting and text-guided editing models by achieving superior physical plausibility and generalization to unseen interactive effects.
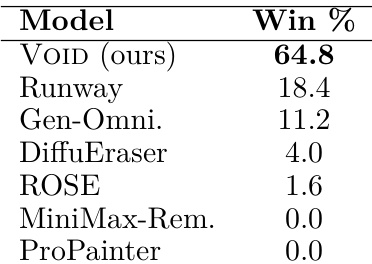
The authors conduct a human preference study to evaluate how realistically different models handle video object removal and its subsequent physical effects. Results show that the proposed VOID model is preferred by participants significantly more often than all other tested baselines. VOID achieves the highest win rate among all evaluated models in real-world scenarios The proposed method outperforms commercial text-guided editing systems Traditional inpainting and removal models receive minimal preference in comparison
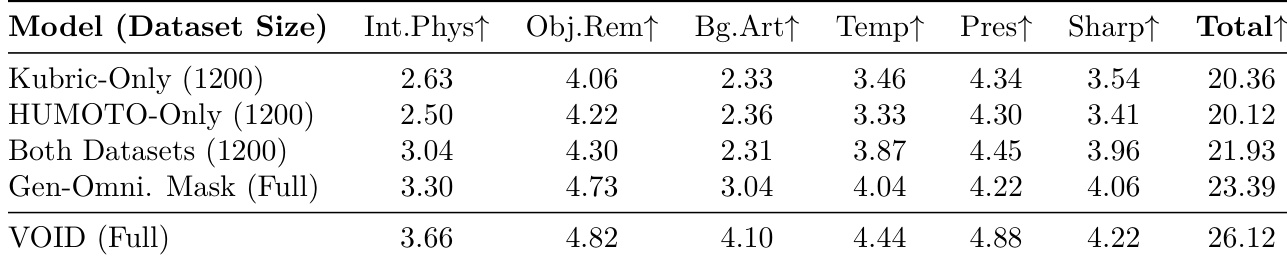
The authors conduct an ablation study to evaluate the impact of a two-pass video appearance refiner. Results show that applying a second pass improves performance across most evaluated criteria, including interaction and physics, object removal, and temporal consistency. The second pass leads to higher total scores compared to the first pass Improvements are observed in the model's ability to handle interaction and physics The second pass enhances object removal and temporal consistency

The authors conduct an ablation study to evaluate the impact of dataset composition and masking strategies on model performance. Results show that combining multiple datasets and utilizing a detailed quadmask strategy significantly improves scores across all evaluated categories. Training on both Kubric and HUMOTO datasets yields better performance than using either dataset alone. The quadmask strategy outperforms the use of less detailed trimasks across all scoring criteria. The full VOID framework achieves the highest total score among all tested configurations.
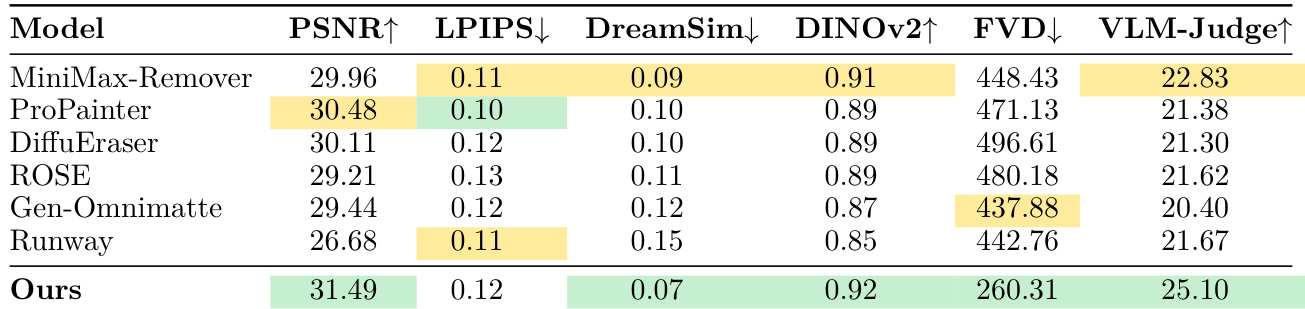
The authors evaluate their model against several baselines on a synthetic benchmark featuring shadow, reflection, and dynamic interaction removal. Results show that the proposed method achieves superior performance across most metrics, particularly in video-level and semantic evaluations. The proposed model demonstrates significant improvements in FVD and VLM-Judge scores compared to all baseline methods. The model achieves the highest scores in DINOv2 and PSNR among the compared approaches. While the model excels in most categories, it does not achieve the lowest LPIPS score, which the authors attribute to the metric's sensitivity to local spatial translations.
The authors evaluate their model against several baselines using three different vision-language model judges on real-world video editing tasks. Results show that the proposed method achieves the highest total scores across all judges, demonstrating superior performance in handling physical interactions and object removal. The proposed model outperforms all baselines in the total score category across all three vision-language judges. The model shows significant advantages in modeling physical interactions and object removal compared to existing methods. The performance gains are consistent across different automated judges, including Gemini Pro, GPT-5.2, and Qwen-3.5-32B.
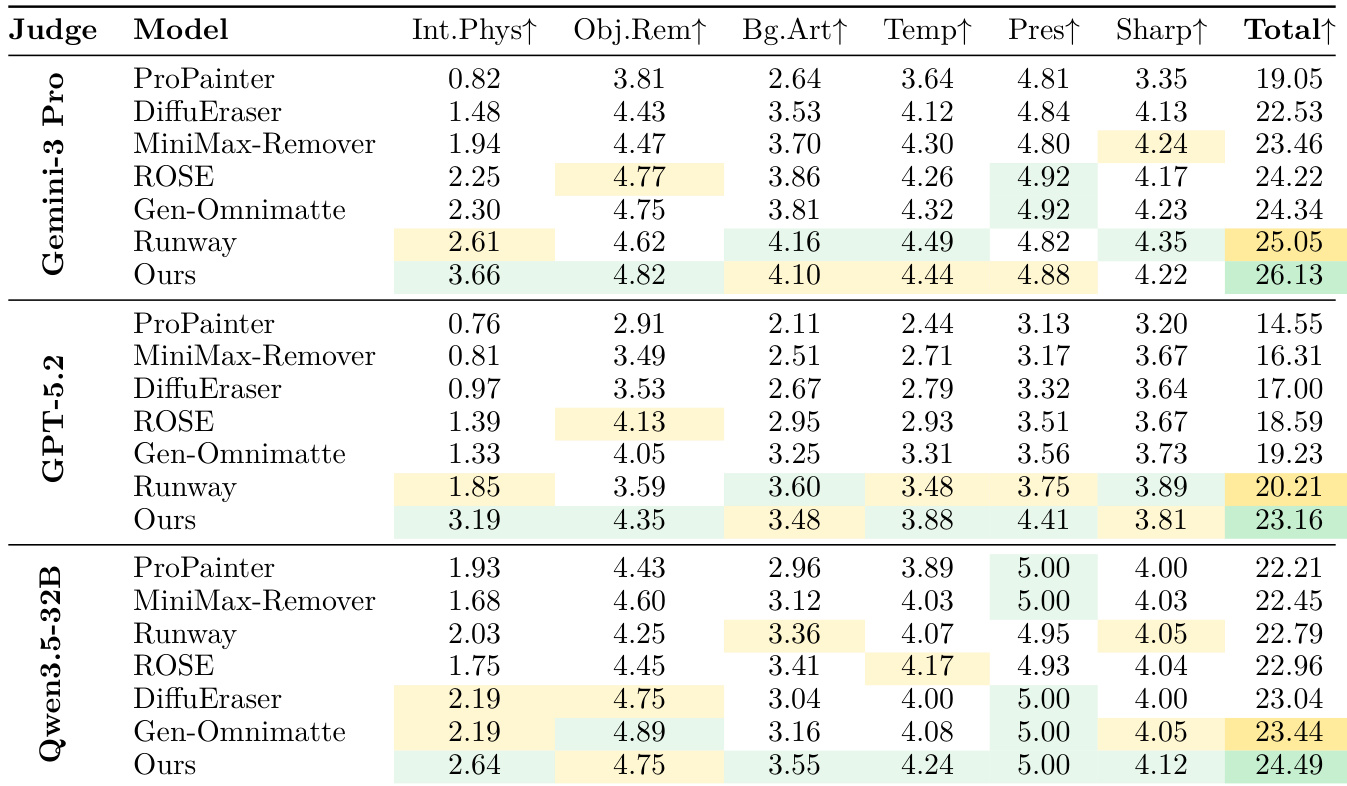
Through human preference studies, ablation experiments, and automated benchmarks, the authors evaluate the effectiveness of the VOID model in handling video object removal and physical interactions. The results demonstrate that the proposed framework significantly outperforms existing baselines and commercial systems by maintaining superior temporal consistency and realistic physical effects. Key architectural components, such as the two-pass appearance refiner, diverse dataset composition, and detailed quadmask strategies, are shown to be essential for achieving high-quality, semantically accurate video editing.