Command Palette
Search for a command to run...
Steerable Visual Representations
Steerable Visual Representations
Jona Ruthardt Manu Gaur Deva Ramanan Makarand Tapaswi Yuki M. Asano
Abstract
Pretrained Vision Transformers (ViTs) such as DINOv2 and MAE provide generic image features that can be applied to a variety of downstream tasks such as retrieval, classification, and segmentation. However, such representations tend to focus on the most salient visual cues in the image, with no way to direct them toward less prominent concepts of interest. In contrast, Multimodal LLMs can be guided with textual prompts, but the resulting representations tend to be language-centric and lose their effectiveness for generic visual tasks. To address this, we introduce Steerable Visual Representations, a new class of visual representations, whose global and local features can be steered with natural language. While most vision-language models (e.g., CLIP) fuse text with visual features after encoding (late fusion), we inject text directly into the layers of the visual encoder (early fusion) via lightweight cross-attention. We introduce benchmarks for measuring representational steerability, and demonstrate that our steerable visual features can focus on any desired objects in an image while preserving the underlying representation quality. Our method also matches or outperforms dedicated approaches on anomaly detection and personalized object discrimination, exhibiting zero-shot generalization to out-of-distribution tasks.
One-sentence Summary
Researchers from University of Technology Nuremberg, Carnegie Mellon University, and IIIT Hyderabad introduce SteerViT, a framework that injects text directly into frozen ViT layers via early fusion cross-attention. Unlike late-fusion models, SteerViT steers visual features toward specific concepts while preserving representation quality, enabling zero-shot generalization for tasks like anomaly detection and personalized object discrimination.
Key Contributions
- The paper introduces SteerViT, a method that injects natural language directly into the layers of a frozen Vision Transformer via lightweight cross-attention to steer both global and local visual features toward specific concepts.
- New benchmarks are established to measure representational steerability, demonstrating that the approach can focus on less prominent objects in an image while preserving the high quality of the underlying visual representation.
- Experiments show that the method matches or outperforms dedicated approaches on anomaly detection and personalized object discrimination tasks, exhibiting zero-shot generalization to out-of-distribution scenarios with significantly fewer trainable parameters.
Introduction
Pretrained Vision Transformers like DINOv2 provide powerful generic image features but inherently focus on the most salient objects, making it difficult to direct attention toward less prominent concepts. While Multimodal LLMs allow text guidance, they often produce language-centric representations that sacrifice visual fidelity and struggle with generic visual tasks. Existing approaches typically rely on late fusion where text interacts only after visual encoding, failing to influence the feature extraction process itself.
The authors introduce SteerViT, a framework that injects natural language directly into the layers of a frozen visual encoder via lightweight cross-attention. This early fusion approach allows users to steer both global and local visual features toward specific objects or attributes without retraining the base model. By adding only 21M trainable parameters, the method achieves a Pareto improvement that preserves high-quality visual representations while enabling precise text-guided control and zero-shot generalization to diverse downstream tasks.
Dataset
- The authors construct a training mixture of referential segmentation and grounding datasets to ensure diversity in visual domains and textual expression styles, totaling 162k unique images and 2.28M image-text pairs.
- The dataset composition includes four primary sources with specific characteristics:
- RefCOCO, RefCOCO+, and RefCOCOg provide referring expressions grounded in COCO images, where RefCOCO+ excludes spatial language to force reliance on appearance cues and RefCOCOg offers longer, more descriptive expressions.
- LVIS utilizes the same COCO images but focuses on fine-grained and long-tail object categories.
- Visual Genome contributes region descriptions paired with bounding boxes across densely annotated scenes to increase vocabulary and spatial relationship complexity, with bounding boxes converted to binary segmentation masks using SAM2.
- Mapillary Vistas introduces street-level imagery with fine-grained panoptic annotations to expand visual domain coverage beyond COCO, utilizing synthetic referential expressions and masks from Describe Anything.
- The model training leverages this combined data to expose the system to varied scene complexities ranging from single objects to dense urban panoramas, expression lengths from two-word labels to multi-sentence descriptions, and diverse visual domains including indoor, outdoor, and street-level scenes.
- Processing steps involve converting bounding boxes to segmentation masks for Visual Genome and adopting synthetic expressions for Mapillary Vistas to ensure robust steered representations across the full spectrum of data.
Method
The authors introduce SteerViT, a framework designed to equip pretrained Vision Transformers (ViT) with the ability to steer visual features using natural language prompts. The core architecture, as illustrated in the comparison of different visual representation families, integrates lightweight cross-attention mechanisms directly into a frozen ViT backbone. This approach contrasts with Multimodal LLMs and Open-Vocabulary Localization models by conditioning the visual encoder on language while maintaining the efficiency and quality of the base vision model.
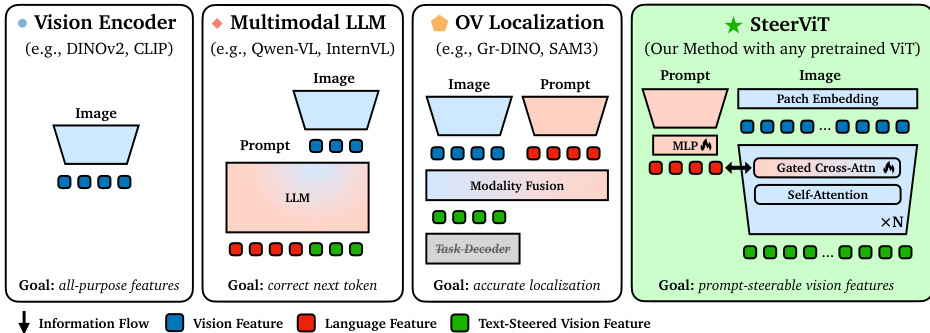
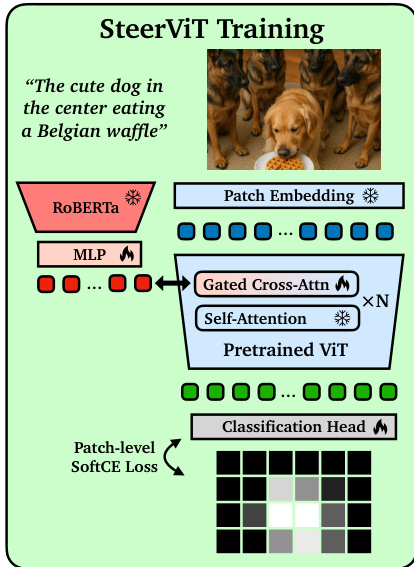
The SteerViT framework consists of four primary components. First, a frozen visual encoder, such as DINOv2, processes the input image to produce a sequence of patch tokens. Second, a frozen text encoder, specifically RoBERTa-Large, generates token-level embeddings for the conditioning prompt. Third, a multimodal adapter projects these text embeddings into the visual embedding space using a trainable two-layer MLP. Finally, gated cross-attention layers are interleaved into every other Transformer block of the ViT. In these layers, the visual patch tokens serve as queries, while the adapted text tokens act as keys and values.
The fusion of textual conditioning into the visual residual stream is governed by a tanh gate with a layer-specific learnable scalar αℓ, which is initialized to zero. This initialization ensures that the model remains identical to the frozen ViT at the start of training, preserving the pre-trained representation quality. The update rule for the visual tokens at layer ℓ is defined as:
Zν(ℓ+1)=Zν(ℓ)+tanh(αℓ)⋅Z^ν(ℓ)
Since tanh(0)=0, the gate receives a learning signal immediately, allowing αℓ to move away from zero during optimization and gradually activate the conditioning pathway.
To train the model, the authors employ a referential segmentation pretext task. As shown in the training pipeline diagram, the model is tasked with predicting which image patches correspond to the target object described in the text prompt. A linear classification head maps the steered patch representations to segmentation probabilities, and the model is optimized using a soft cross-entropy loss against the ground truth mask fractions.
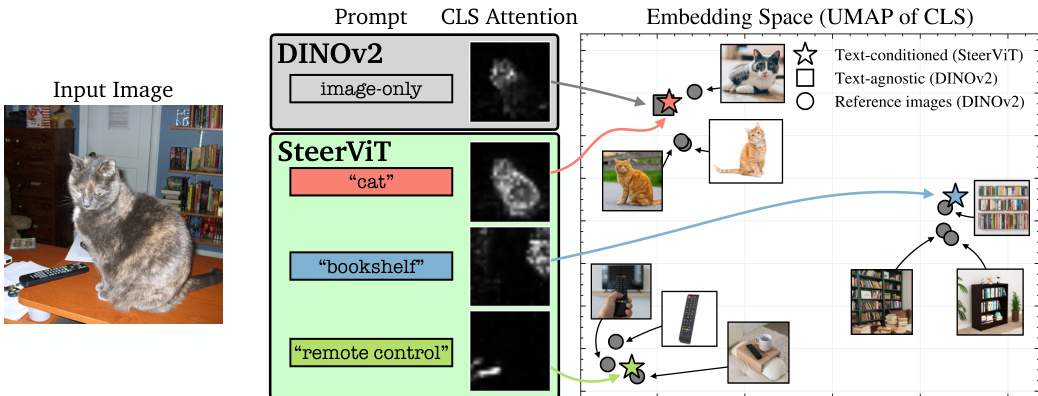
This training objective encourages the cross-attention layers to route textual information specifically to the relevant visual patch tokens. The effectiveness of this steering is evident in the embedding space, where text-conditioned features form distinct clusters corresponding to the prompted objects, unlike the generic clusters formed by image-only encoders.
Experiment
- Conditional Retrieval (CORE): Validates that SteerViT can steer global features toward specific non-salient objects using text prompts, whereas standard vision encoders collapse to dominant scene concepts and late-fusion methods fail to modify frozen visual features.
- MOSAIC Localization: Demonstrates that text conditioning redirects self-attention to queried objects within complex scenes, enabling targeted focus on specific entities rather than the most visually prominent ones.
- Representation Quality Trade-off: Confirms that SteerViT achieves high steerability without sacrificing the transferability of the underlying vision encoder, unlike open-vocabulary localization models which lose generalization or MLLMs which incur high computational costs.
- Semantic Granularity Control: Shows that the level of detail in text prompts directly dictates the granularity of visual representations, allowing the model to switch between coarse category clustering and fine-grained instance discrimination.
- Embedding Space Reorganization: Illustrates that text conditioning can restructure the embedding topology to group images by semantic hierarchy or arbitrary compositional attributes, such as shared object parts.
- Zero-Shot Domain Transfer: Proves that language-driven steering enables robust generalization to out-of-distribution tasks like industrial anomaly segmentation without task-specific training.
- Architectural Ablations: Establishes that early fusion of text within the Transformer layers, gated cross-attention mechanisms, and segmentation-based training objectives are critical for balancing steerability with feature quality.