Command Palette
Search for a command to run...
ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
Fei Tang Zhiqiong Lu Boxuan Zhang Weiming Lu Jun Xiao Yueting Zhuang Yongliang Shen
Abstract
GUI agents drive applications through their visual interfaces instead of programmatic APIs, interacting with arbitrary software via taps, swipes, and keystrokes, reaching a long tail of applications that CLI-based agents cannot. Yet progress in this area is bottlenecked less by modeling capacity than by the absence of a coherent full-stack infrastructure: online RL training suffers from environment instability and closed pipelines, evaluation protocols drift silently across works, and trained agents rarely reach real users on real devices. We present ClawGUI, an open-source framework addressing these three gaps within a single harness. ClawGUI-RL provides the first open-source GUI agent RL infrastructure with validated support for both parallel virtual environments and real physical devices, integrating GiGPO with a Process Reward Model for dense step-level supervision. ClawGUI-Eval enforces a fully standardized evaluation pipeline across 6 benchmarks and 11+ models, achieving 95.8% reproduction against official baselines. ClawGUI-Agent brings trained agents to Android, HarmonyOS, and iOS through 12+ chat platforms with hybrid CLI-GUI control and persistent personalized memory. Trained end to end within this pipeline, ClawGUI-2B achieves 17.1% Success Rate on MobileWorld GUI-Only, outperforming the same-scale MAI-UI-2B baseline by 6.0%.
One-sentence Summary
ClawGUI is an open-source unified framework that addresses infrastructure gaps in GUI agent development by integrating ClawGUI-RL, which utilizes GiGPO with a Process Reward Model for reinforcement learning across virtual and physical devices; ClawGUI-Eval, which provides a standardized pipeline across six benchmarks with 95.8% reproduction accuracy; and ClawGUI-Agent, which enables cross-platform deployment on Android, HarmonyOS, and iOS.
Key Contributions
- The paper introduces ClawGUI-RL, an open-source reinforcement learning infrastructure that supports both parallel virtual environments and real physical devices by integrating GiGPO with a Process Reward Model for dense step-level supervision.
- The work establishes ClawGUI-Eval, a standardized evaluation pipeline covering 6 benchmarks and over 11 models that achieves a 95.8% reproduction rate against official baselines.
- The researchers develop ClawGUI-Agent to enable deployment across Android, HarmonyOS, and iOS via 12+ chat platforms using hybrid CLI-GUI control and persistent personalized memory.
Introduction
GUI agents are essential for automating digital tasks by interacting directly with visual interfaces rather than relying on programmatic APIs. While research in this field has improved element localization and navigation, progress is currently stalled by a lack of integrated infrastructure. Existing workflows suffer from unstable online reinforcement learning (RL) environments, inconsistent evaluation protocols that make cross-paper comparisons unreliable, and a significant gap between laboratory training and real-world device deployment.
The authors leverage a unified open-source framework called ClawGUI to bridge these gaps across the entire agent lifecycle. The framework introduces ClawGUI-RL, which provides scalable training support for both virtual emulators and physical devices using dense step-level supervision. It also includes ClawGUI-Eval, a standardized pipeline that ensures high reproducibility across multiple benchmarks, and ClawGUI-Agent, a deployment system that enables hybrid CLI and GUI control on Android, HarmonyOS, and iOS. To validate the framework, the authors trained ClawGUI-2B, which significantly outperforms existing models of similar scale on the MobileWorld benchmark.
Dataset

The authors introduce ClawGUI-Eval, a comprehensive evaluation framework designed to assess GUI grounding and navigation capabilities. The dataset details are as follows:
- Benchmark Composition: The evaluation suite covers six distinct benchmarks to ensure diverse scenario coverage: ScreenSpot-Pro, ScreenSpot-V2, UI-Vision, MMBench-GUI, OSWorld-G, and AndroidControl.
- Model Coverage: The framework is designed to evaluate over 11 different models, including various vision-language models such as Qwen3-VL, Qwen2.5-VL, UI-TARS, and Gemini, among others.
- Usage and Accessibility: The authors provide publicly released inference results and evaluation code to facilitate community reproduction and future extensions of their research.
Method
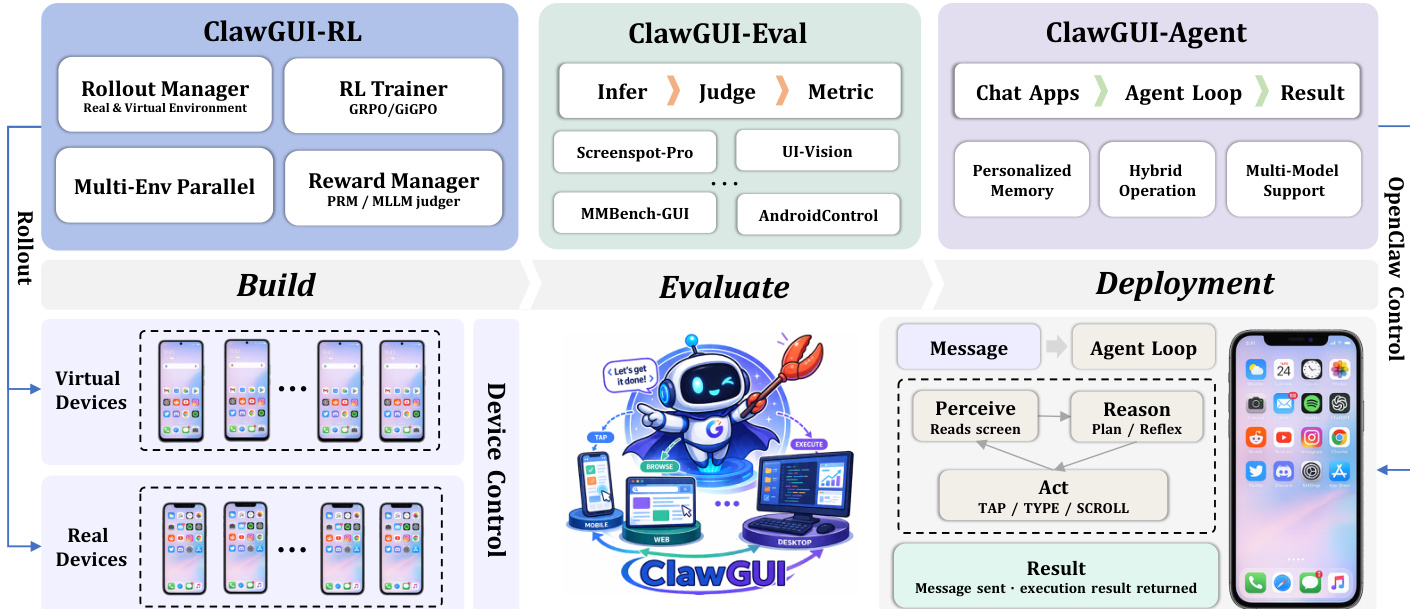
The authors introduce ClawGUI, a unified framework designed to support the complete lifecycle of GUI agent development, encompassing training, evaluation, and deployment. The overall architecture is structured into three primary modules: ClawGUI-RL for scalable online reinforcement learning (RL) training, ClawGUI-Eval for standardized and reproducible evaluation, and ClawGUI-Agent for real-device deployment and human interaction. These modules are interconnected through a pipeline that enables seamless transition from model development to real-world application.
ClawGUI-RL is responsible for scalable online RL training and is built upon the verl framework, supporting a suite of RL algorithms including Reinforce++, PPO, GSPO, GRPO, and GiGPO. The module leverages a two-level reward formulation to address the challenges of sparse reward signals in long-horizon GUI tasks. The primary reward signal is a binary outcome reward, assigned as 1 for task success and 0 for failure at the end of an episode. To mitigate the sparsity of this signal, ClawGUI-RL integrates a Process Reward Model (PRM) that generates a dense step-level reward after each action. The PRM evaluates whether the current action meaningfully contributes to task completion by analyzing the previous and current screenshots along with the full action history, producing a per-step score that is combined with the outcome reward. This dense feedback enables the optimizer to distinguish productive actions from dead ends throughout the episode.
The RL trainer within ClawGUI-RL employs advanced advantage estimation techniques to improve training efficiency. GRPO estimates advantages by normalizing returns within a group of rollouts sharing the same task, but its uniform episode-level advantage assignment is too coarse for long-horizon GUI interactions. In contrast, GiGPO addresses this limitation through a hierarchical advantage estimation approach. At the episode level, GiGPO preserves macro relative advantages across complete trajectories, while at the step level, it uses an anchor-state grouping mechanism to cluster steps that encounter the same intermediate environment state across different rollouts. Micro relative advantages are then estimated within each sub-group via discounted return normalization, enabling fine-grained per-step credit assignment without requiring a learned value network or additional rollouts.
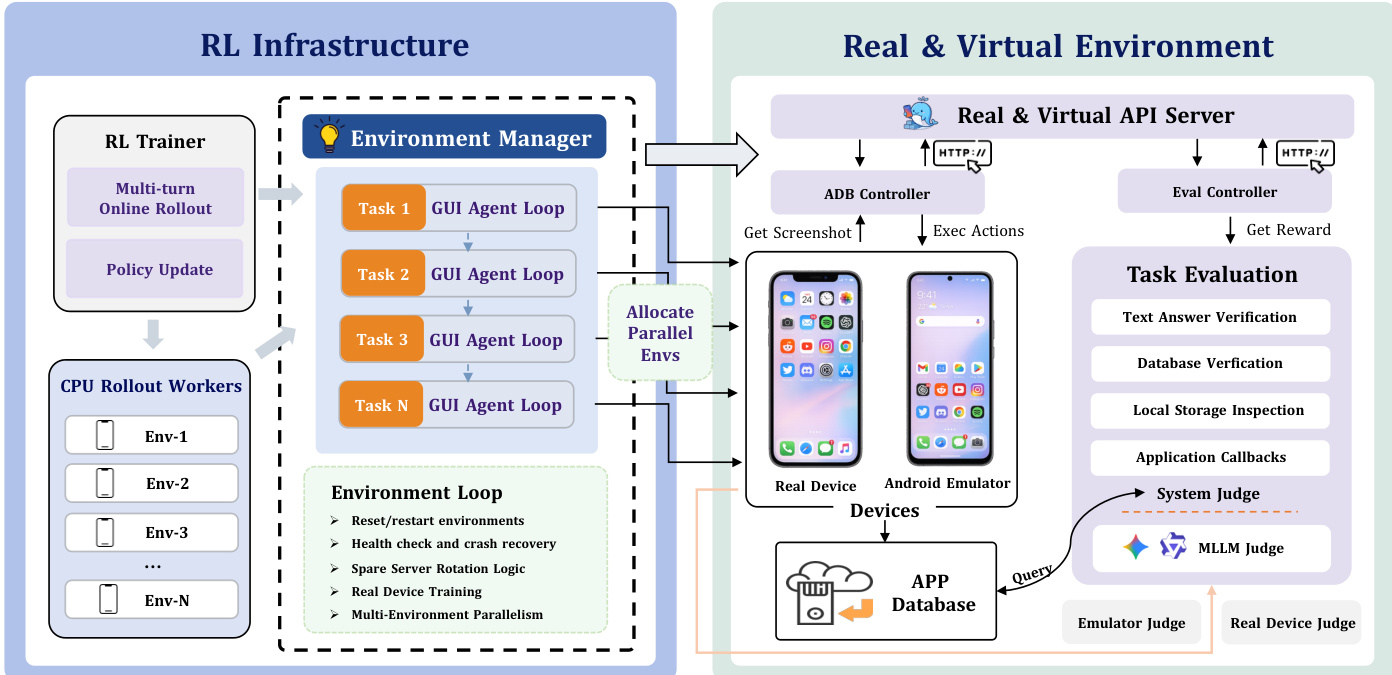
The environment management system within ClawGUI-RL abstracts all device backends behind a unified interface, allowing virtual environments and physical devices to be used interchangeably within the same training loop. Virtual environments are launched in parallel via MobileWorld using Docker-based Android emulators, each exposing a backend URL for training workers. These environments follow a four-stage lifecycle: task reset, task evaluation, spare server rotation, and teardown. Task reset ensures a clean starting condition for each episode, while task evaluation leverages system-level root access for reliable completion verification through direct inspection of app state and database records, complemented by an MLLM-as-judge for assessing the final screen state. Spare server rotation maintains training stability by automatically replacing unhealthy containers, and periodic teardown prevents state accumulation.
For real-device training, ClawGUI-RL supports physical Android devices or cloud phones through the same unified interface. This introduces challenges such as the need for manually authored tasks to ensure executability and verifiability on physical hardware, and the absence of system-level root access for automated state verification. To address this, the system relies on the MLLM-as-judge to assess task completion by evaluating the final screen state against the task instruction. The environment manager also includes logic for health checks, crash recovery, and real-device training, ensuring robust operation across diverse hardware.
ClawGUI-Eval provides a standardized and reproducible evaluation framework, decomposing the evaluation process into three decoupled stages: Infer, Judge, and Metric. The inference stage generates raw predictions from a target model using either local GPU inference via transformers or remote API inference via any OpenAI-compatible endpoint. Multi-GPU parallel inference is handled automatically through Python multiprocessing, with shard-level checkpointing allowing interrupted runs to resume without recomputation. The judge stage parses raw model outputs and evaluates them against ground truth using benchmark-specific judges, such as a point-in-box judge for standard GUI grounding benchmarks or a polygon and refusal-aware judge for OSWorld-G. Each judge produces a per-sample correctness label. The metric stage aggregates these labels into final accuracy scores, providing breakdowns by platform, UI element type, and task category for fine-grained analysis. This modular design allows any single stage to be rerun independently, facilitating efficient updates and debugging.
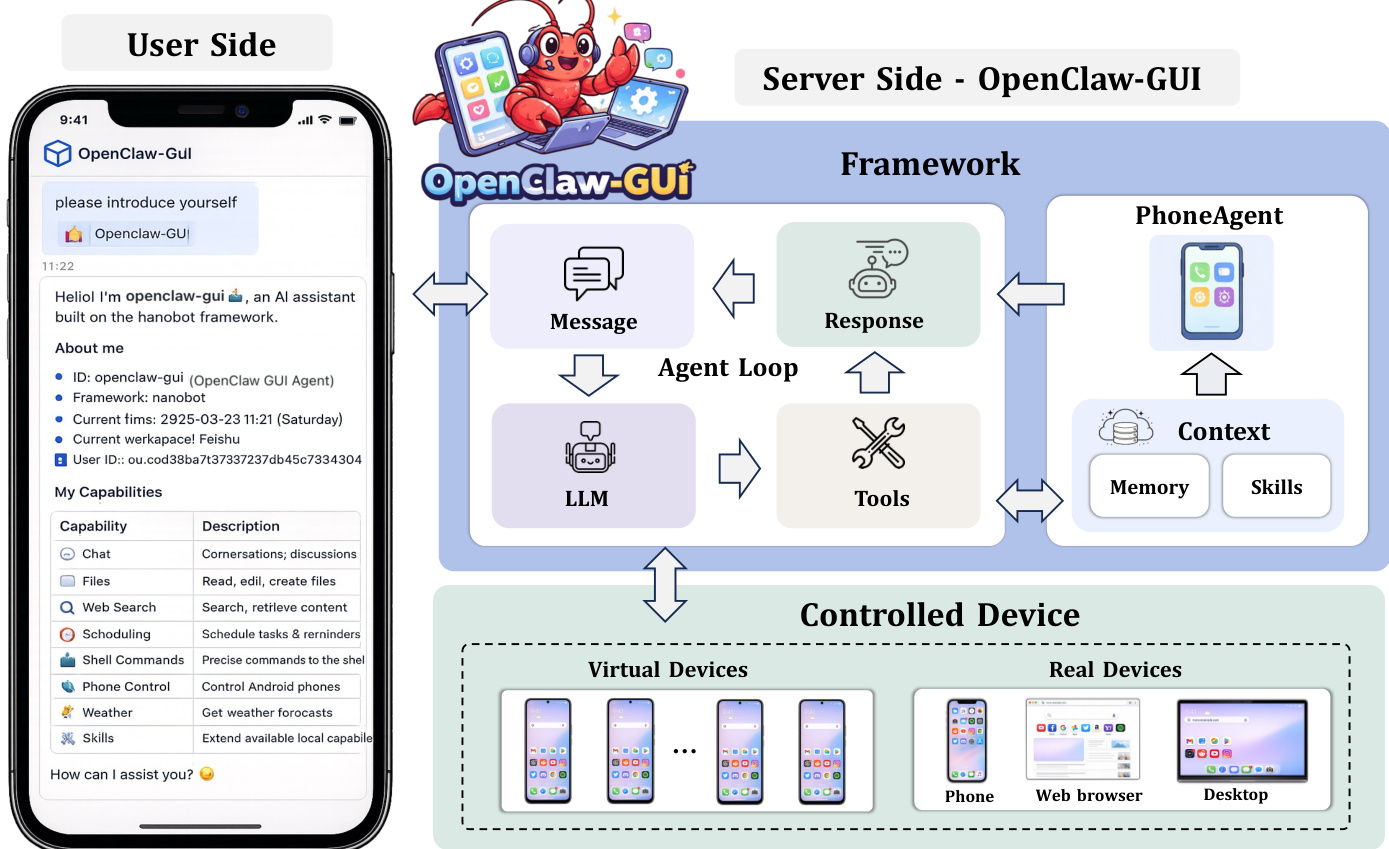
ClawGUI-Agent enables real-device deployment and human interaction through a message-driven agent loop with persistent memory and skills. The agent supports two deployment modes: remote control, where users issue tasks from 12+ chat platforms including Feishu, DingTalk, Telegram, Discord, Slack, and QQ to control a target phone remotely, and local control, where users send instructions directly from a chat application running on the phone itself, allowing the agent to take over the local device without additional hardware or cloud relay. The agent incorporates a persistent personalized memory system that automatically extracts structured facts from interactions, such as contact names, frequently used applications, and user habits, storing them as vector embeddings. On subsequent tasks, the top-k most semantically similar memories are retrieved and injected into the system context, enabling the agent to recognize recurring entities and adapt to individual user patterns over time.
ClawGUI-Agent exposes ClawGUI-Eval as a built-in tool skill, allowing users to trigger a complete benchmark evaluation pipeline through a single natural-language command. Upon receiving an instruction, the agent automatically performs environment verification, launches multi-GPU parallel inference, runs the judge, computes metrics, and returns a structured result report with comparisons against official baselines. The agent operates through a message-driven loop that includes perceiving the screen, reasoning and planning, acting (e.g., tap, type, scroll), and returning the result. The framework supports hybrid operation across mobile, web browser, and desktop devices, and includes multi-model support for integrating various language models.
Experiment
The ClawGUI framework is evaluated through an end-to-end pipeline comprising scalable reinforcement learning infrastructure, a standardized evaluation suite, and a deployment-ready agent system. Training experiments demonstrate that dense step-level credit assignment and robust environment management allow small models to outperform significantly larger untrained models. Furthermore, the evaluation module achieves a high reproduction rate across multiple benchmarks, confirming that standardized protocols can resolve the current lack of comparability in GUI agent research.
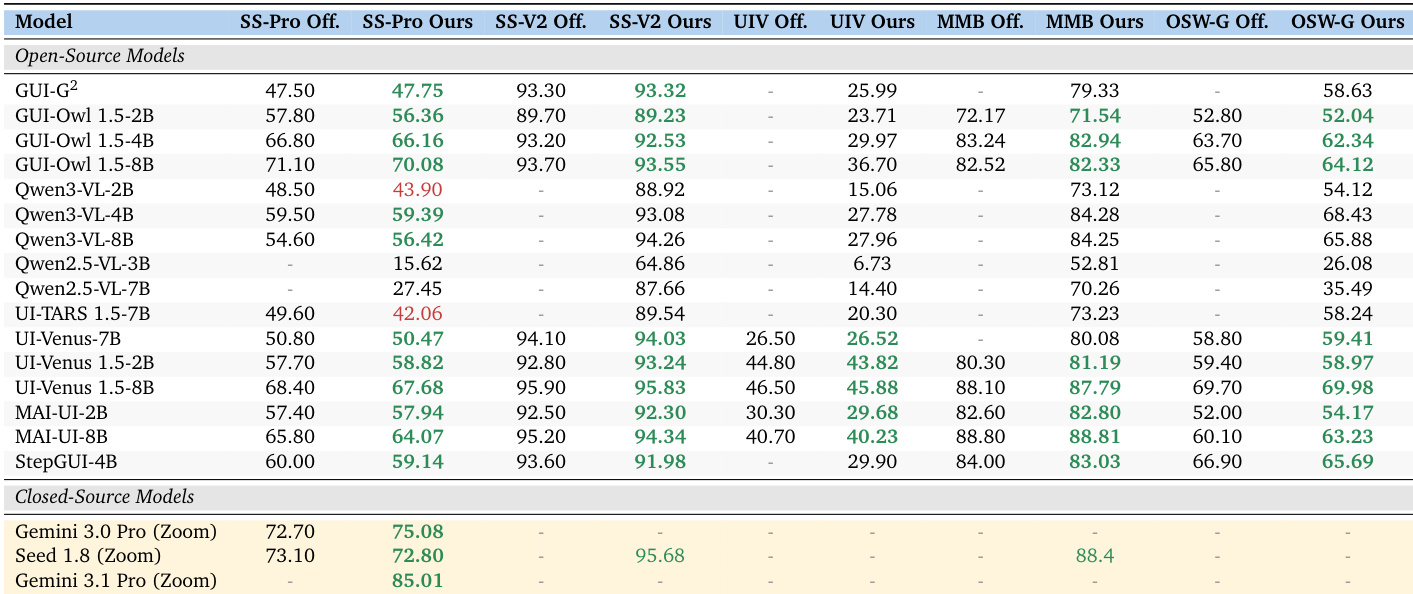
The authors present a framework that enables reproducible evaluation of GUI agents across multiple benchmarks and models. Results show high reproduction rates for both open-source and closed-source models, demonstrating that evaluation discrepancies stem from infrastructure rather than inherent limitations. A standardized evaluation pipeline achieves 95.8% reproduction rate across 6 benchmarks and 11+ models. Open-source models achieve 95.7% reproduction rate, while frontier models reach 100% on ScreenSpot-Pro. Closed-source models are evaluated using a two-stage Zoom paradigm to recover official performance without model access.
The the the table compares two reward types in GUI agent training, showing that dense step-level supervision leads to higher success rates than episode-level rewards. Results indicate that fine-grained credit assignment significantly improves performance in long-horizon GUI tasks. Dense step-level reward improves success rate compared to episode-level reward Fine-grained credit assignment enhances policy training in GUI tasks Step-level supervision yields a substantial improvement over coarse episode-level rewards

The authors compare the success rates of various GUI agents on the MobileWorld GUI-Only benchmark, highlighting the performance of their proposed model against existing systems. Results show that their model achieves competitive success rates, outperforming several baseline models while demonstrating the effectiveness of their training and evaluation framework. The proposed model achieves a success rate that surpasses several baseline models on the MobileWorld GUI-Only benchmark. The framework enables reproducible evaluation, achieving a high reproduction rate across multiple benchmarks and models. The success rate of the proposed model is competitive with larger models despite its smaller scale, indicating the importance of effective training infrastructure.
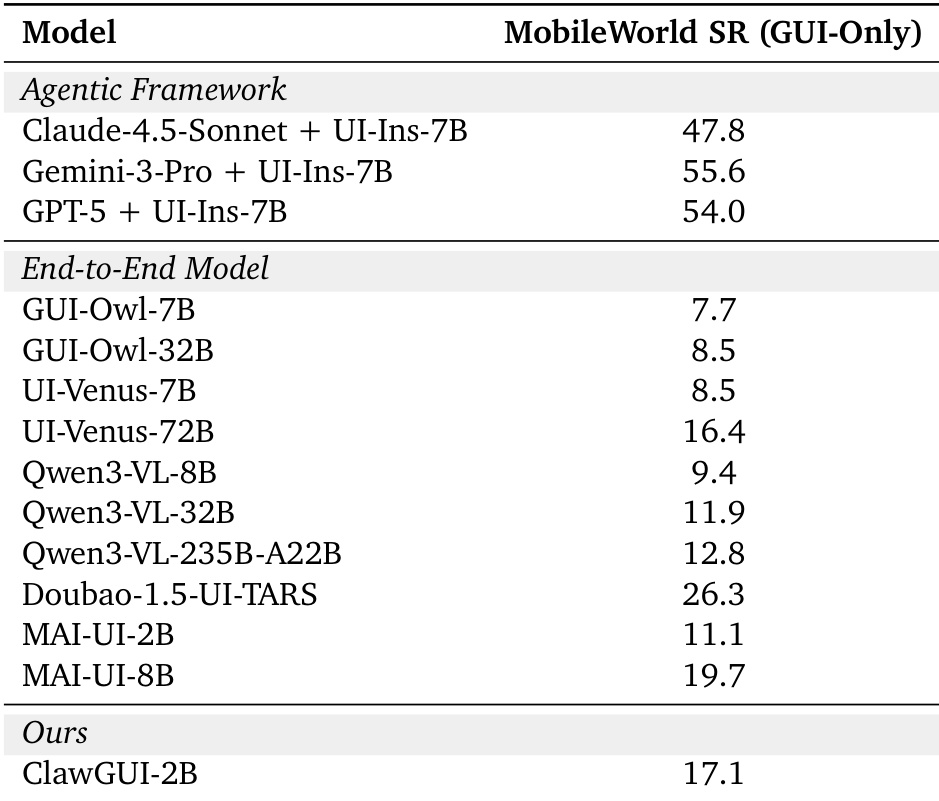
The authors evaluate a reproducible framework for GUI agents across multiple benchmarks and compare different reward structures and agent performances. The results demonstrate that a standardized evaluation pipeline ensures high reproduction rates across various models, while dense step-level supervision significantly outperforms coarse episode-level rewards in long-horizon tasks. Furthermore, the proposed model achieves competitive success rates on the MobileWorld benchmark, outperforming several baselines and highlighting the effectiveness of the training infrastructure.