Command Palette
Search for a command to run...
Poly-EPO: Training Exploratory Reasoning Models
Poly-EPO: Training Exploratory Reasoning Models
Ifdita Hasan Orney Jubayer Ibn Hamid Shreya S Ramanujam Shirley Wu Hengyuan Hu Noah Goodman Dorsa Sadigh Chelsea Finn
Abstract
Exploration is a cornerstone of learning from experience: it enables agents to find solutions to complex problems, generalize to novel ones, and scale performance with test-time compute. In this paper, we present a framework for post-training language models (LMs) that explicitly encourages optimistic exploration and promotes a synergy between exploration and exploitation. The central idea is to train the LM to generate sets of responses that are collectively accurate under the reward function and exploratory in their reasoning strategies. We first develop a general recipe for optimizing LMs with set reinforcement learning (set RL) under arbitrary objective functions, showing how standard RL algorithms can be adapted to this setting through a modification to the advantage computation. We then propose Polychromatic Exploratory Policy Optimization (POLY-EPO), which instantiates this framework with an objective that explicitly synergizes exploration and exploitation. Across a range of reasoning benchmarks, we show that POLY-EPO improves generalization, as evidenced by higher pass@k coverage, preserves greater diversity in model generations, and effectively scales with test-time compute.
One-sentence Summary
The authors propose POLY-EPO, a post-training framework for language models utilizing set reinforcement learning with modified advantage computation to generate response sets that are collectively accurate under the reward function and employ exploratory reasoning, thereby synergizing exploration and exploitation to improve generalization via higher pass@k coverage, preserve generation diversity, and scale effectively with test-time compute across reasoning benchmarks.
Key Contributions
- A framework for post-training language models is presented to explicitly encourage optimistic exploration while promoting synergy between exploration and exploitation. This approach trains models to generate sets of responses that are collectively accurate under the reward function and exploratory in their reasoning strategies.
- The work develops a general recipe for optimizing language models with set reinforcement learning under arbitrary objective functions by adapting standard algorithms through a modification to the advantage computation. This shows how standard reinforcement learning algorithms can be adapted to this setting.
- Polychromatic Exploratory Policy Optimization (POLY-EPO) is introduced as an instantiation of the framework that encodes synergy directly in the advantage function through covariance between average reward and diversity. Experiments across reasoning benchmarks demonstrate improved generalization, higher pass@k coverage, and effective scaling with test-time compute.
Introduction
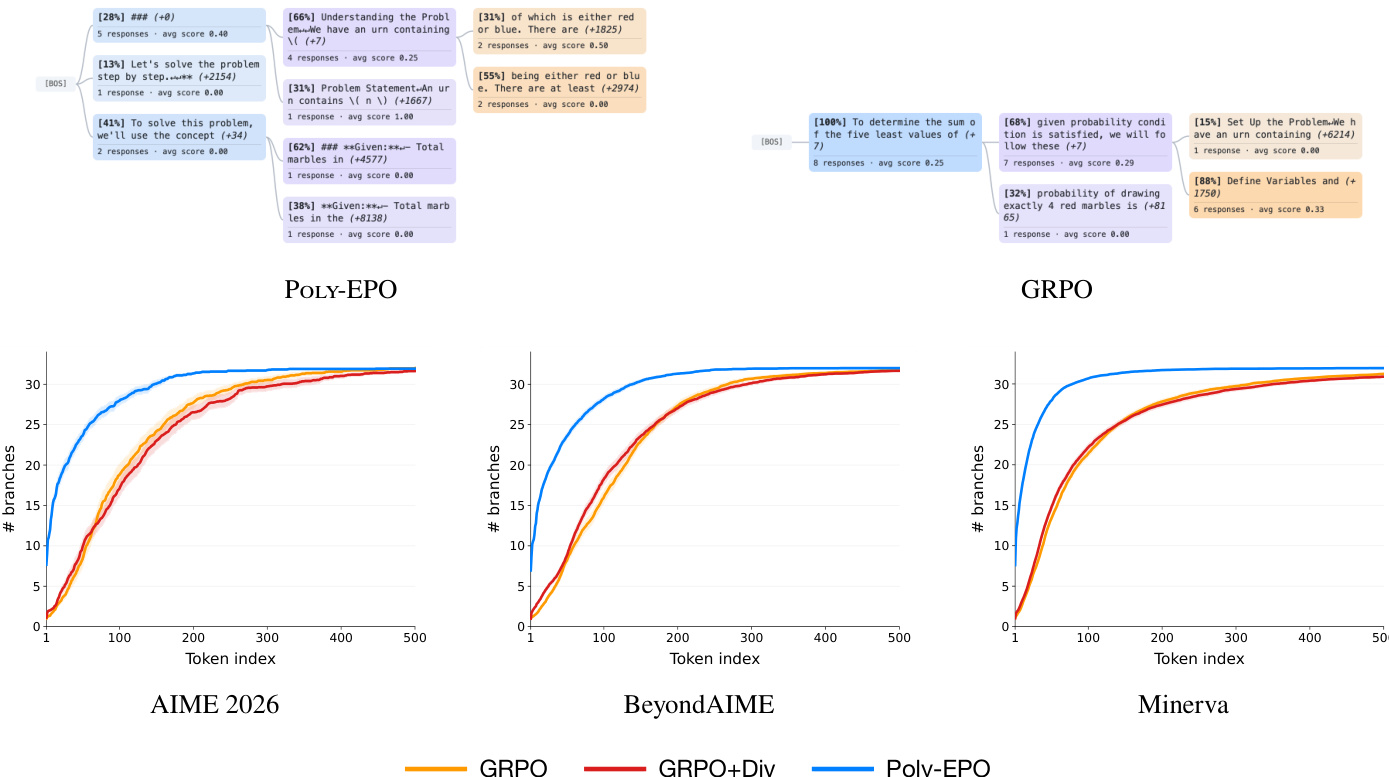
Exploration is critical for language models to solve complex reasoning tasks and scale effectively with test-time compute. However, standard reinforcement learning fine-tuning often collapses generation diversity onto narrow high-reward behaviors. Prior methods attempt to address this by adding exploration bonuses, yet they treat exploration and exploitation as separate objectives requiring careful hyperparameter tuning. The authors introduce Polychromatic Exploratory Policy Optimization (POLY-EPO), a framework that leverages set reinforcement learning to optimize sets of responses collectively. This method explicitly synergizes exploration and exploitation by encoding the covariance between average reward and strategy diversity directly into the advantage function. As a result, the approach encourages optimistic exploration of novel reasoning strategies and improves generalization metrics like pass@k.
Method
The authors introduce Polychromatic Exploratory Policy Optimization (POLY-EPO), a method designed to optimize language models using a set reinforcement learning framework. This approach generalizes standard reinforcement learning by assigning rewards to sets of sampled generations rather than to each generation independently. The core objective is to balance exploration and exploitation, encouraging the model to discover diverse reasoning strategies while maintaining accuracy.
The framework begins with a set-level objective function. For a given prompt, the policy samples a set of n generations. A set-level reward function f is applied to the entire set, coupling all generations under a shared learning signal. To optimize this objective efficiently, the authors derive a tractable gradient estimator. For each prompt, N independent generations are sampled, where N is greater than the set size n. From these samples, K sets of size n are constructed combinatorially. A set-level score is computed for each constructed set, and a baseline is established as the average of these scores across all sets. The advantage for a specific set is the difference between its score and this baseline.
To integrate this with standard reinforcement learning algorithms, a marginal set advantage is defined for each individual generation. This value is calculated as the average advantage of all sets that contain the specific generation. This construction allows the method to use existing policy gradient algorithms, such as PPO or GRPO, by replacing the standard advantage function with the marginal set advantage. The marginal set advantage for a generation y is defined as:
Amarg♯(x,y;f):=∣G(y)∣1G∈G(y)∑A♯(x,G;f)where G(y) represents the collection of all sets containing the generation y. The resulting estimator is unbiased and scales efficiently with the number of samples.
The specific objective optimized in POLY-EPO is the polychromatic objective. This function is defined as the product of the mean reward of the generations in the set and a diversity measure. The mathematical formulation ensures that a set must optimize both exploration and exploitation simultaneously, as the score depends on the product of these two factors. The polychromatic objective is expressed as:
fpoly(x,y1,⋯,yn)=n1i=1∑nr(x,yi)⋅d(x,y1,⋯,yn)If either the reward or the diversity is low, the overall score is diminished.
Diversity is measured using a language model judge to cluster responses according to their underlying reasoning strategies. The judge groups generations based on macro and micro strategies while ignoring superficial textual differences. The diversity of a set is calculated as the number of distinct clusters represented in the set divided by the set size. Degenerate generations that exhibit reward hacking or nonsensical behavior are isolated into a dedicated cluster and excluded from the diversity calculation to ensure robustness.
The final training algorithm follows a standard on-policy update loop. The model samples generations for a batch of prompts, constructs sets, computes the polychromatic scores, and derives the marginal set advantages. These advantages are then used to update the policy parameters. This process prioritizes simplicity and scalability, leveraging infrastructure already present in modern post-training pipelines while introducing the benefits of set-level credit assignment.
Experiment
The experiments evaluate POLY-EPO on mathematical reasoning benchmarks and synthetic domains with verifiable rewards to assess whether its exploration mechanism improves reasoning performance. In mathematical tasks, POLY-EPO demonstrates superior diversity in reasoning strategies and better utilization of test-time compute compared to baselines that suffer from strategy collapse. Synthetic domain results further confirm that POLY-EPO discovers significantly more distinct successful strategies than standard methods which quickly converge to single solutions, validating that the proposed objective effectively balances exploration and exploitation to enhance generalization.