Command Palette
Search for a command to run...
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Abstract
Large language models are increasingly expected to serve as general-purpose agents that interact with external, stateful tool environments. The Model Context Protocol (MCP) and broader agent skills offer a unified interface for connecting agents with scalable real-world services, but training robust agents remains limited by the lack of realistic environments and principled mechanisms for life-long learning. In this paper, we present Agent-World, a self-evolving training arena for advancing general agent intelligence through scalable environments. Agent-World has two main components: (1) Agentic Environment-Task Discovery, which autonomously explores topic-aligned databases and executable tool ecosystems from thousands of real-world environment themes and synthesizes verifiable tasks with controllable difficulty; and (2) Continuous Self-Evolving Agent Training, which combines multi-environment reinforcement learning with a self-evolving agent arena that automatically identifies capability gaps through dynamic task synthesis and drives targeted learning, enabling the co-evolution of agent policies and environments. Across 23 challenging agent benchmarks, Agent-World-8B and 14B consistently outperforms strong proprietary models and environment scaling baselines. Further analyses reveal scaling trends in relation to environment diversity and self-evolution rounds, offering insights for building general agent intelligence.
One-sentence Summary
ByteDance Seed researchers propose Agent-World, a self-evolving training arena that scales real-world environment synthesis through autonomous agentic environment-task discovery and continuous reinforcement learning to enable the co-evolution of agent policies and verifiable tasks, allowing the Agent-World-8B and 14B models to consistently outperform strong proprietary models and environment scaling baselines across 23 agent benchmarks.
Key Contributions
- The paper introduces Agent-World, a self-evolving training arena designed to advance general agent intelligence through scalable and realistic tool environments.
- The framework features an Agentic Environment-Task Discovery component that utilizes real MCP server metadata to autonomously mine topic-aligned databases and executable toolsets while synthesizing verifiable tasks with controllable difficulty.
- The research presents a Continuous Self-Evolving Agent Training mechanism that integrates multi-environment reinforcement learning with a diagnostic arena to identify capability gaps and drive targeted iterative learning, achieving superior performance across 23 benchmarks compared to strong proprietary models and scaling baselines.
Introduction
As large language models evolve into general purpose agents, they require interaction with complex, stateful tool environments to perform real world tasks. Current training approaches face significant hurdles because real world services are often inaccessible and manually constructed sandboxes are expensive to scale. Furthermore, existing reinforcement learning methods typically optimize policies on fixed distributions rather than adapting to new challenges. The authors leverage a novel framework called Agent-World to address these gaps through a self-evolving training arena. This system autonomously discovers real world tool ecosystems and databases to synthesize verifiable tasks, while simultaneously using a continuous reinforcement learning loop to identify and bridge agent capability gaps through targeted environment expansion.
Dataset
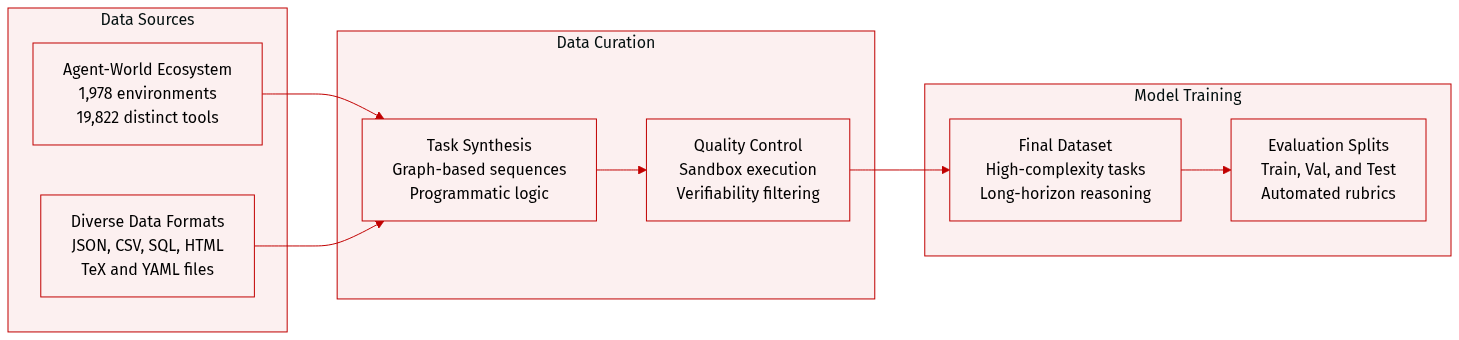
Dataset Description
The authors introduce a scalable ecosystem of agentic environments and synthesized tasks designed to simulate complex, real-world tool-use scenarios.
Dataset Composition and Sources The dataset is built upon the Agent-World ecosystem, which consists of:
- Environments: Over 1,978 filtered environments covering diverse domains such as local arXiv libraries, email mailboxes (Enron dataset), calendar services, hotel booking systems, social app metadata (Instagram, TikTok, WhatsApp), and food delivery storefronts.
- Tools: A collection of 19,822 distinct tools distributed across these environments.
- Data Formats: A diverse range of file types including JSON, CSV, SQL, HTML, TeX, and YAML.
Task Synthesis Subsets The authors utilize two primary strategies to generate verifiable tasks:
- Graph-Based Tasks (Xgraph): These focus on sequential tool dependencies. The authors construct weighted directed tool graphs where edges represent strong, weak, or independent dependencies. They perform random walks on these graphs to sample tool sequences, which are then populated with real data and refined by an LLM.
- Programmatic Tasks (Xprog): These model non-linear reasoning, such as loops and conditional logic. An LLM generates a complex task query and a corresponding executable Python script. This approach captures behaviors that simple sequential tool calls cannot.
Processing and Quality Control To ensure high quality and verifiability, the authors implement several rigorous processing steps:
- Sandbox Execution: All synthesized tool sequences and programmatic scripts are executed within a Python sandbox to collect execution traces and derive ground-truth answers.
- Verifiability Filtering: Tasks are only retained if they pass a stability test, where a ReAct agent must successfully solve the task in at least two out of five independent attempts.
- Metadata Construction: For each task, the authors generate a realistic query, a structured JSON ground-truth answer, and detailed evaluation rubrics covering field completeness, schema matching, and numerical tolerances. For programmatic tasks, a dedicated executable verification script is generated to perform multi-level assertions.
- Difficulty Scaling: Complexity is increased by expanding tool chain lengths, increasing the frequency of non-linear dependencies, and rewriting task descriptions to obscure technical tool names, forcing agents to infer workflows from abstract goals.
Data Usage The synthesized tasks are characterized by high interaction complexity, averaging over 20 turns per task, with many exceeding 40 turns. The dataset is designed to evaluate an agent's ability to perform long-horizon reasoning, cross-database aggregations, and complex programmatic control flows across diverse, self-contained, and offline environments.
Method
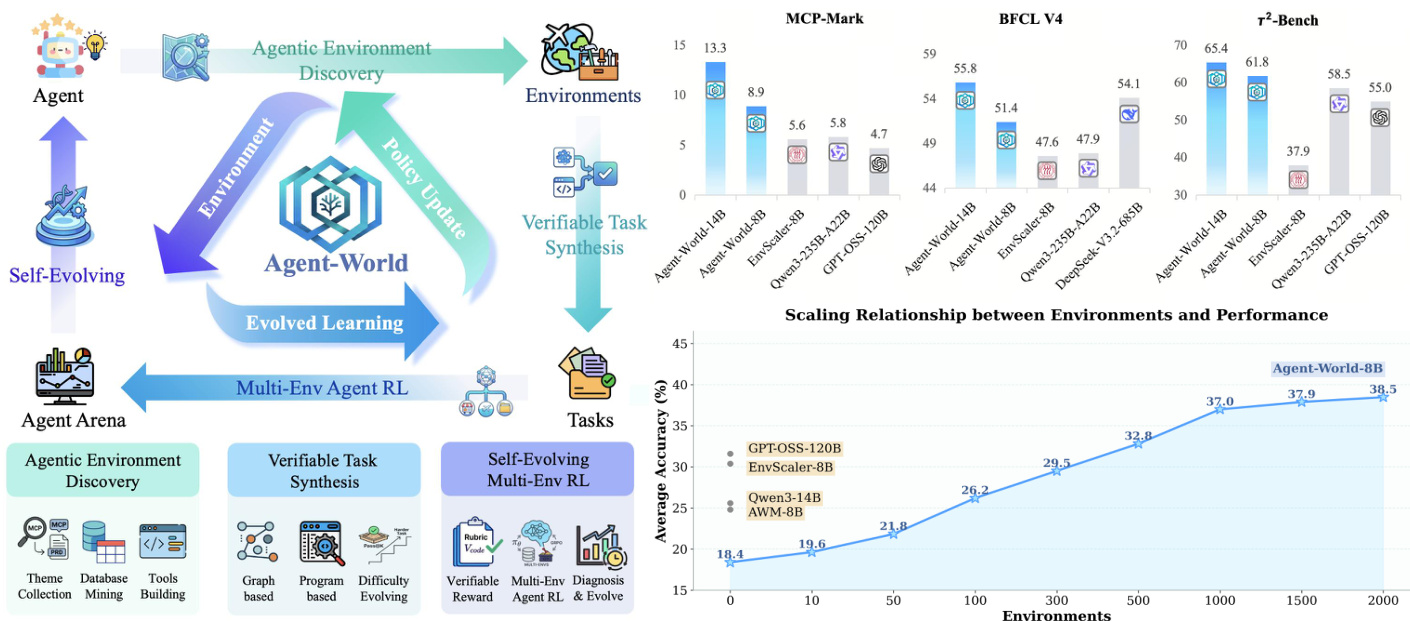
The proposed framework, Agent-World, consists of two tightly coupled components: Agentic Environment-Task Discovery and Continuous Self-Evolving Agent Training, forming a closed-loop system for scalable environment-task discovery and agent policy refinement. The overall architecture integrates environment synthesis, task generation, and agent training into a dynamic, self-improving pipeline.
Agentic Environment-Task Discovery begins with the collection of diverse environment themes from real-world sources, including MCP servers, tool documentation, and industrial product requirement documents. These themes serve as anchors for synthesizing a scalable environment ecosystem. The process then proceeds to agentic database mining, where a deep-research agent, equipped with a policy model and external tools, autonomously mines and processes web data to construct topic-aligned databases. This workflow is enhanced through a database complexification process that iteratively enriches the databases, ensuring they meet realistic demands. Following database construction, a coding agent generates executable tool interfaces grounded in the database, accompanied by unit tests. These tools undergo rigorous cross-validation to ensure functionality and reliability, resulting in a quality-controlled toolset. The synthesized environments are systematically organized using a hierarchical taxonomy, which provides a structured foundation for cross-environment task synthesis and stratified evaluation. 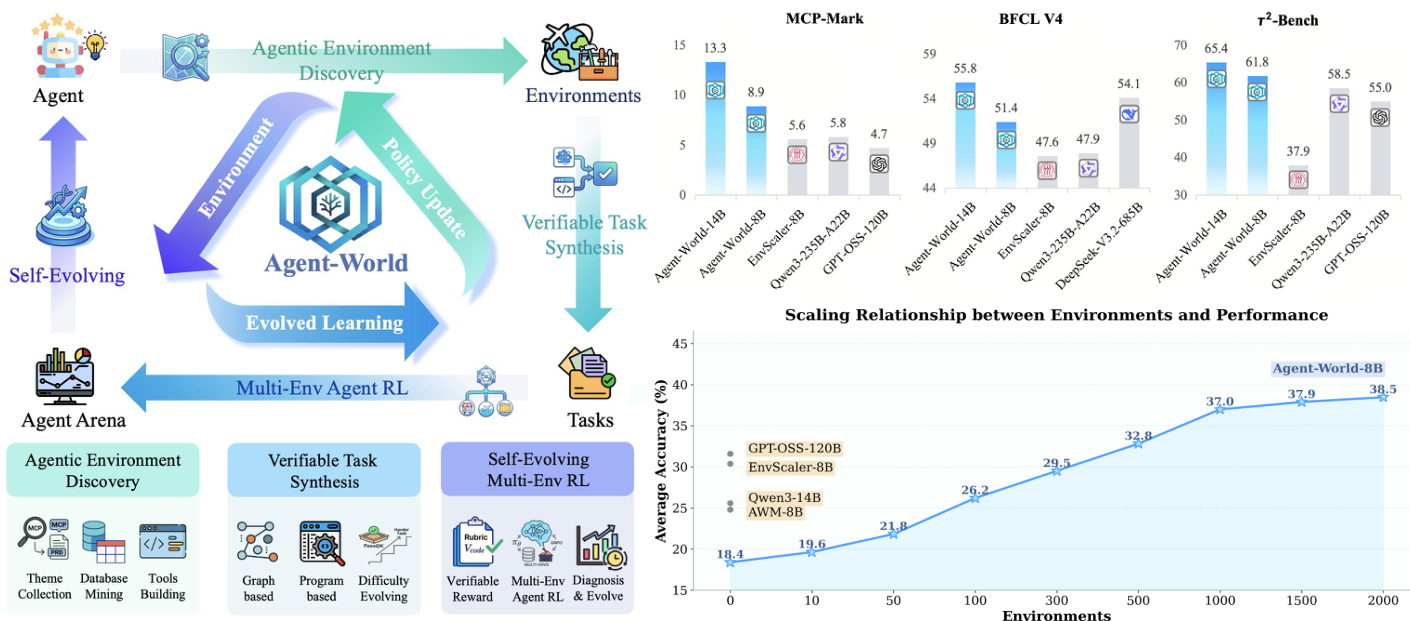
The second component, Continuous Self-Evolving Agent Training, leverages the scalable environment ecosystem for multi-environment reinforcement learning. The training process involves a closed-loop interaction among a policy model, a tool interface, and a database state, enabling the agent to perform state-aware reasoning and long-horizon tool use. At each step, the policy generates actions based on the dialogue history and tool feedback, triggering tool execution in a sandboxed environment to read or update the database state. The interaction trajectory and final answer are collected, and a structured verifiable reward is computed to guide policy optimization. Reward signals are derived from two types of tasks: graph-based tasks use a rubric-conditioned LLM judge to evaluate criterion-level pass indicators, while programmatic tasks employ executable validation scripts to verify the predicted answer or resulting database state. Policy updates are performed using Group Relative Policy Optimization (GRPO), which maximizes verifiable returns by optimizing a clipped objective with a KL penalty to a reference policy. 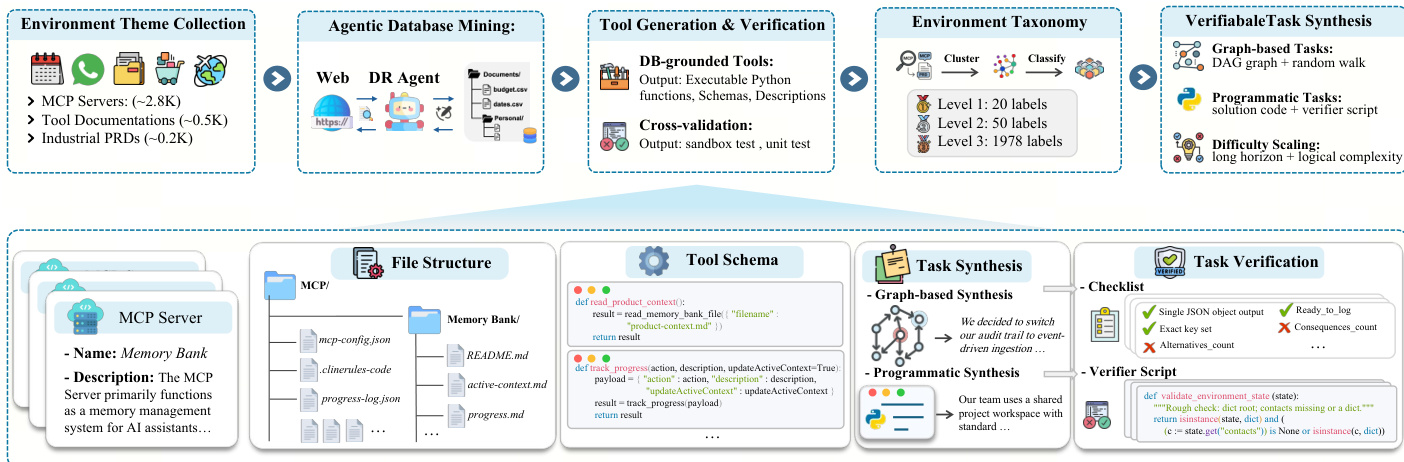
The training process is augmented by a self-evolving agent arena that serves as a dynamic diagnostic platform. This arena is constructed by stratified sampling from the hierarchical taxonomy, ensuring broad coverage over different environment types. At each iteration, fresh verifiable tasks are synthesized for the sampled environments, and the agent policy is evaluated using the executable rewards. An agentic diagnosis agent analyzes failure patterns from per-task execution traces, error statistics, and environment metadata to identify weak environments and generate targeted task-generation guidelines. These insights drive a co-evolutionary process where the environment ecosystem is expanded and refined to address capability gaps, and the agent policy is updated through continued multi-environment RL. This iterative loop enables the continuous improvement of both agent capabilities and the underlying environment ecosystem. 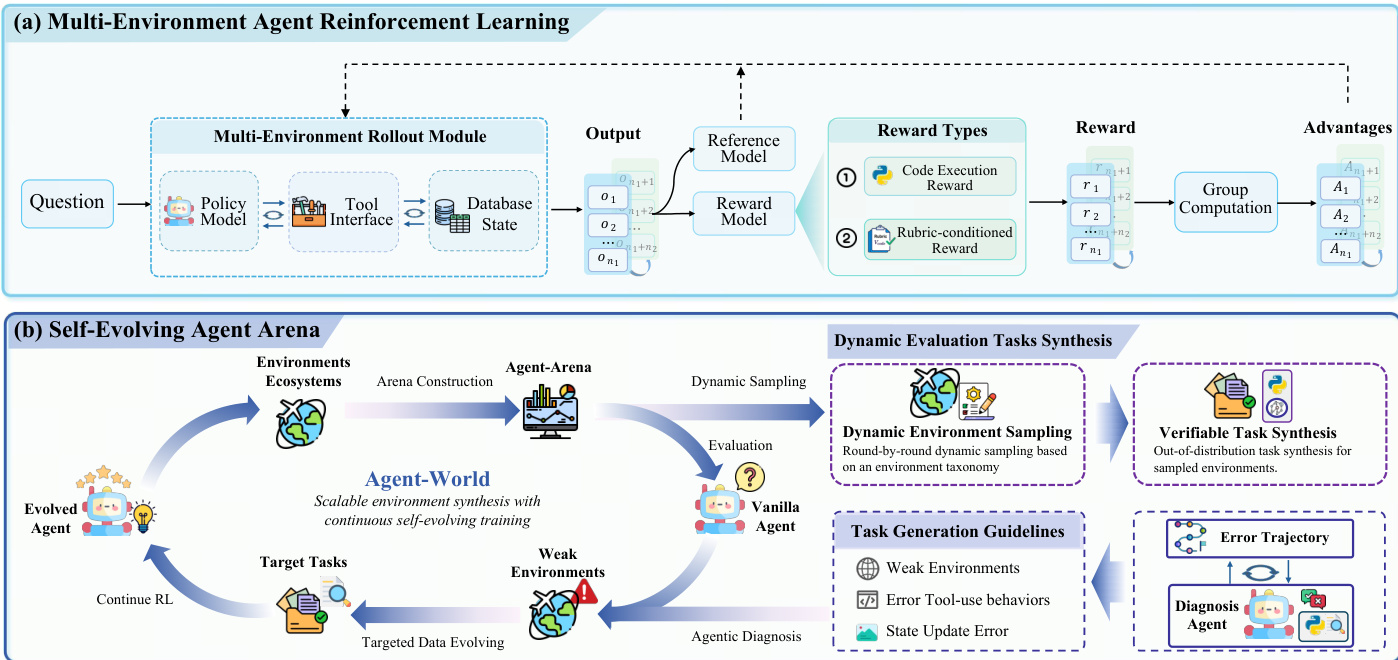
Experiment
The evaluation assesses Agent-World across 23 diverse benchmarks to validate its effectiveness in agentic tool-use, software engineering, deep research, and general reasoning. Results demonstrate that the unified framework provides superior and more consistent cross-environment generalization compared to frontier proprietary models and existing environment-scaling baselines. The analysis further confirms that agent performance scales positively with the number of synthesized environments and that the continuous self-evolving training loop drives sustained, monotonic improvements by targeting specific capability gaps.
The authors evaluate Agent-World, a training framework that integrates scalable environment synthesis with continuous self-evolving training, on multiple benchmarks covering tool use, reasoning, and AI assistant tasks. Results show that Agent-World consistently outperforms existing baselines across diverse environments, demonstrating stronger generalization and more stable improvements with increasing model scale. The framework achieves significant gains through iterative self-evolution, particularly in complex, stateful scenarios requiring long-horizon planning and multi-tool coordination. Agent-World consistently outperforms prior environment-scaling methods and foundation models across diverse benchmarks, showing stronger generalization in long-horizon tool-use scenarios. Agent-World achieves stable improvements from 8B to 14B, with consistent gains across different task types, indicating effective transferability to complex assistant and reasoning domains. The performance of Agent-World improves with the number of synthesized environments, and its self-evolving training loop leads to monotonic gains by identifying and addressing capability gaps in agent behavior.
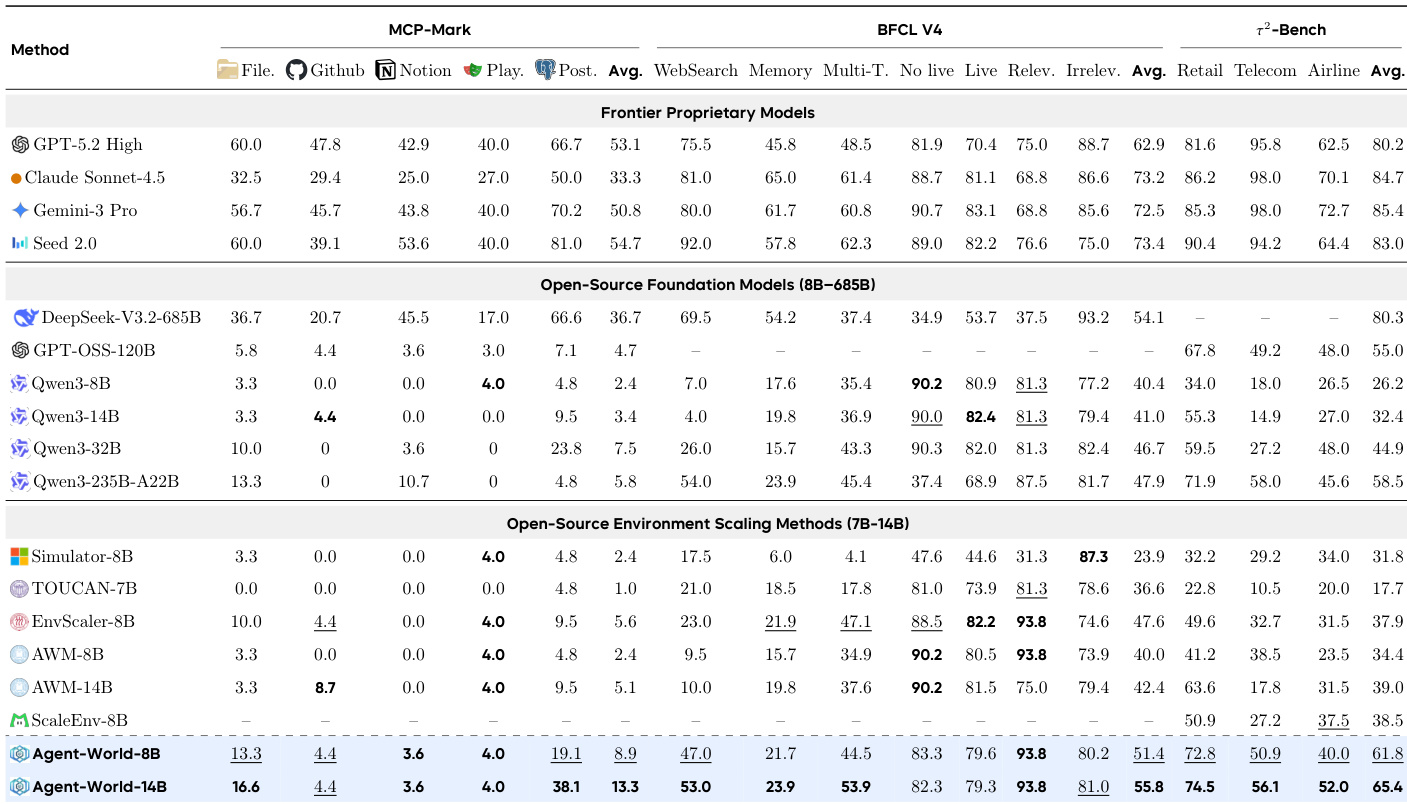
The authors introduce Agent-World, a training framework that combines scalable environment synthesis with continuous self-evolving training to improve agent performance. Results show that Agent-World consistently outperforms baseline methods across diverse benchmarks, with stronger generalization in long-horizon and stateful scenarios. The framework demonstrates that increasing the number of training environments leads to improved performance, and iterative self-evolution drives sustained gains by identifying and addressing capability gaps. Agent-World consistently outperforms existing baselines across multiple benchmark suites, showing stronger generalization in complex, stateful environments. Performance improves as the number of training environments increases, indicating a positive scaling relationship between environment diversity and agent capability. Iterative self-evolution leads to sustained gains by diagnosing weaknesses and generating targeted training tasks, resulting in continual policy improvement.
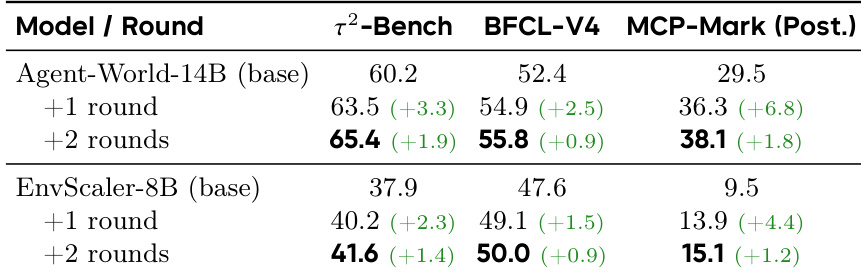
The authors evaluate the effectiveness of their continuous self-evolving training framework by comparing performance improvements across multiple rounds of training. Results show that both Agent-World-14B and EnvScaler-8B achieve consistent gains after each self-evolving round, with Agent-World-14B demonstrating stronger overall improvements, especially on complex benchmarks requiring state tracking and multi-step coordination. The gains diminish across rounds, indicating diminishing returns at larger scales. Agent-World-14B achieves consistent performance gains across all evaluated benchmarks after each self-evolving round, with the largest improvements on MCP-Mark. Both Agent-World-14B and EnvScaler-8B show positive improvements after each round, indicating the self-evolving loop benefits models regardless of initialization. Gains diminish across rounds, suggesting that early rounds address major capability gaps while later rounds provide incremental refinements.
The authors evaluate the Agent-World framework across multiple benchmarks covering tool use, reasoning, and assistant tasks to validate the effectiveness of scalable environment synthesis and continuous self-evolving training. The results demonstrate that the framework consistently outperforms existing baselines, particularly in complex, long-horizon scenarios that require multi-tool coordination and state tracking. Furthermore, the experiments show that increasing environment diversity and conducting iterative self-evolution cycles drive sustained performance gains by effectively addressing agent capability gaps.