Command Palette
Search for a command to run...
MultiWorld: Scalable Multi-Agent Multi-View Video World Models
MultiWorld: Scalable Multi-Agent Multi-View Video World Models
Haoyu Wu Jiwen Yu Yingtian Zou Xihui Liu
Abstract
Video world models have achieved remarkable success in simulating environmental dynamics in response to actions by users or agents. They are modeled as action-conditioned video generation models that take historical frames and current actions as input to predict future frames. Yet, most existing approaches are limited to single-agent scenarios and fail to capture the complex interactions inherent in real-world multi-agent systems. We present MultiWorld, a unified framework for multi-agent multi-view world modeling that enables accurate control of multiple agents while maintaining multi-view consistency. We introduce the Multi-Agent Condition Module to achieve precise multi-agent controllability, and the Global State Encoder to ensure coherent observations across different views. MultiWorld supports flexible scaling of agent and view counts, and synthesizes different views in parallel for high efficiency. Experiments on multi-player game environments and multi-robot manipulation tasks demonstrate that MultiWorld outperforms baselines in video fidelity, action-following ability, and multi-view consistency. Project page: https://multi-world.github.io/
One-sentence Summary
MultiWorld is a unified framework for scalable multi-agent and multi-view video world modeling that utilizes a Multi-Agent Condition Module and a Global State Encoder to achieve precise controllability and coherent observations, outperforming baselines in video fidelity, action-following ability, and multi-view consistency across multi-player game environments and multi-robot manipulation tasks.
Key Contributions
- The paper introduces MultiWorld, a unified framework for scalable multi-agent and multi-view video world modeling that supports a variable number of agents and camera views.
- The framework incorporates a Multi-Agent Condition Module using agent identity embeddings and adaptive action weighting to achieve precise controllability over multiple agents.
- The method utilizes a Global State Encoder to compress cross-view information into a compact latent representation, which ensures multi-view consistency and enables efficient parallel synthesis.
Introduction
Video world models are essential for simulating environmental dynamics in response to user or agent actions, serving as powerful simulators for embodied AI and gaming. However, existing models typically assume a single-agent environment and struggle to capture the complex interdependencies found in multi-agent systems. Furthermore, previous approaches often fail to maintain geometric and visual consistency across the different viewpoints held by multiple agents, and many are limited by fixed agent or camera counts. The authors leverage a unified framework called MultiWorld to enable scalable multi-agent and multi-view video modeling. They introduce the Multi-Agent Condition Module (MACM) to ensure precise control over individual agents and the Global State Encoder (GSE) to maintain multi-view consistency by aggregating observations into a 3D-aware global state.
Dataset
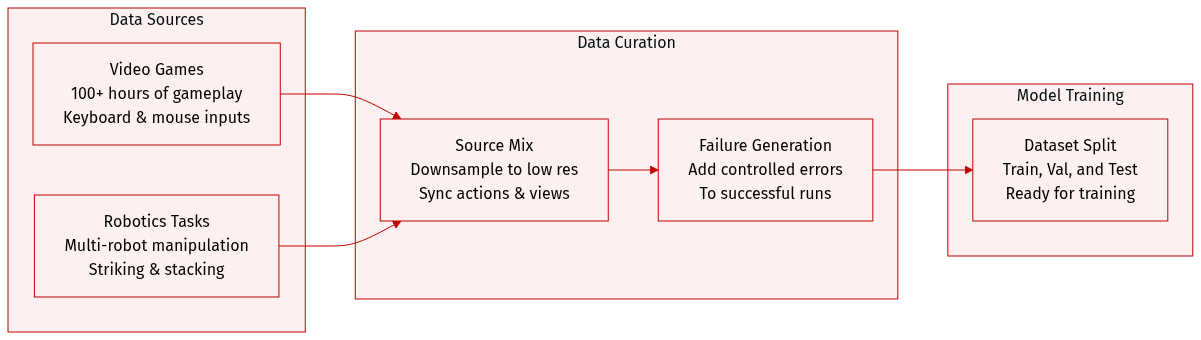
The authors construct a diverse dataset comprising video game gameplay and multi-robot manipulation tasks:
- Video Game Dataset: This subset consists of over 100 hours of human gameplay recorded at 60 FPS. The data includes synchronized keyboard and mouse actions. For training purposes, the original 1440×2560 resolution is downsampled to 320×640. The authors plan to release a subset of the "It Takes Two" multiplayer dataset to support reproduction.
- Robotics Dataset: Sourced from RoboFactory, this dataset focuses on four multi-robot manipulation tasks: striking, stacking with two robots, stacking with three robots, and passing with four robots. Each task contains 1,000 successful episodes and 2,000 failure episodes. Data is recorded from multiple viewpoints at a resolution of 256×320.
- Failure Case Construction: To prevent success-only bias and ensure meaningful training, the authors generate failure episodes by introducing controlled perturbations to successful trajectories. Rather than using purely random actions, which previously hindered world model training, they preserve the basic operational sequence while adding randomness to simulate realistic execution errors.
- Data Availability: While the full video game dataset is restricted due to external constraints, the authors will release a specific chapter of the game data and the complete multi-robot cooperation dataset to the public.
Method
The MultiWorld framework is designed to generate multi-view-consistent videos conditioned on multi-agent actions, leveraging a modular architecture that ensures scalability and consistency across agents and viewpoints. At its core, the model employs a diffusion-based backbone built on Flow Matching (FM) with a Transformer backbone, enabling conditional generation of video frames based on noisy observations, timesteps, actions, and environment context. For each camera view c, the model conditions on the joint action sequence a and initial observations oc, predicting the target velocity u through a parameterized velocity network vθ(xct,t,a,o). To maintain temporal causality during autoregressive generation, a frame-wise causal mask is applied to the action cross-attention mechanism, ensuring that predictions at frame i depend only on actions from frames {0,…,i}.
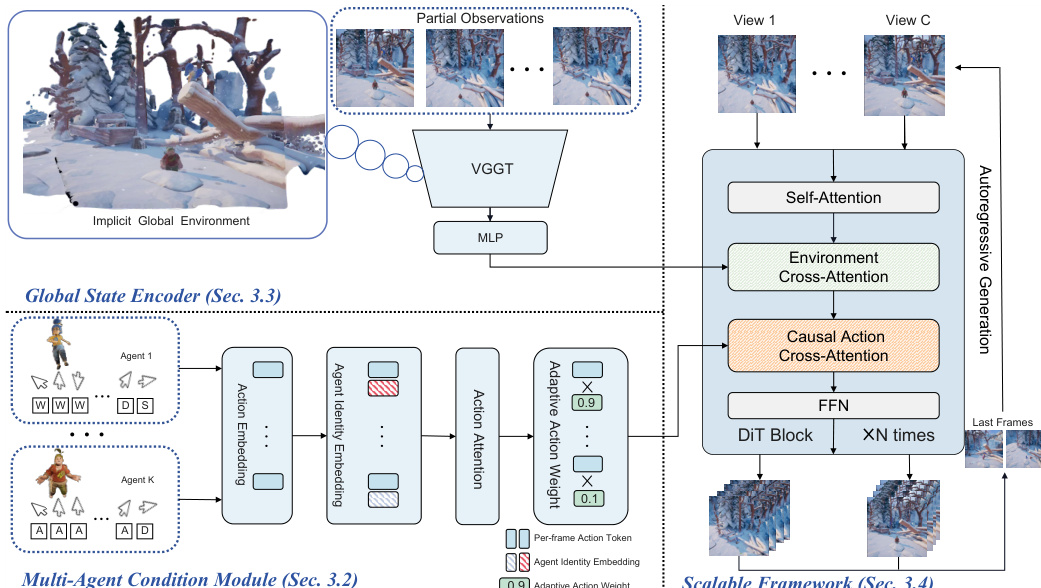
As shown in the figure below, the architecture integrates two key modules to address multi-agent and multi-view challenges: the Multi-Agent Condition Module (MACM) and the Global State Encoder (GSE). The MACM processes actions from K agents, addressing identity ambiguity and varying action strengths. To resolve identity ambiguity, the model applies Agent Identity Embedding (AIE) using Rotary Position Embedding (RoPE), which rotates action embeddings based on agent indices to break symmetry in the action space. This allows the model to distinguish between agents even when their actions are mirrored or similar. Following AIE, a self-attention mechanism models inter-agent interactions by computing attention between agents m and n as am⊤Rn−man, enabling the model to capture relational dynamics. To handle varying action strengths, Adaptive Action Weighting (AAW) uses a multi-layer perceptron to assign dynamic weights to each agent's action token, prioritizing active agents and suppressing static ones. These weighted action tokens are aggregated into a unified action representation, which is injected into the DiT backbone via causal cross-attention.
The Global State Encoder (GSE) ensures multi-view consistency by maintaining a shared 3D-aware representation of the environment. It processes partial observations from multiple camera views using a pretrained VGTT model, which extracts latent features Hvggt∈RC×n×d, where C is the number of views, n is the number of tokens per image, and d is the latent dimension. These features are then compressed via an MLP into a compact global representation H, which is injected into the DiT backbone through cross-attention. This shared global state enables the model to generate consistent partial observations across views without requiring explicit 3D reconstruction. The framework further supports scalability by decomposing multi-view simulation into independent single-view generation tasks conditioned on the global environment state, allowing for parallel generation across views with near-constant inference latency as the number of views increases.
The overall framework supports long-horizon, autoregressive simulation by iteratively generating video chunks and updating the global environment state using the most recent frames. This enables stable generation over temporal horizons exceeding twice the training context length. The modular design ensures that the model can scale to arbitrary numbers of agents and views, with agent scalability achieved through relative identity embeddings and view scalability through the compression of multi-view observations into a unified 3D-aware state. The training objective for the diffusion backbone is to minimize the Flow Matching loss LFM=Et,ϵ[∥vθ(xt,t,a)−u∥22], with inference performed via a probability flow ODE sampled using the Euler solver.
Experiment
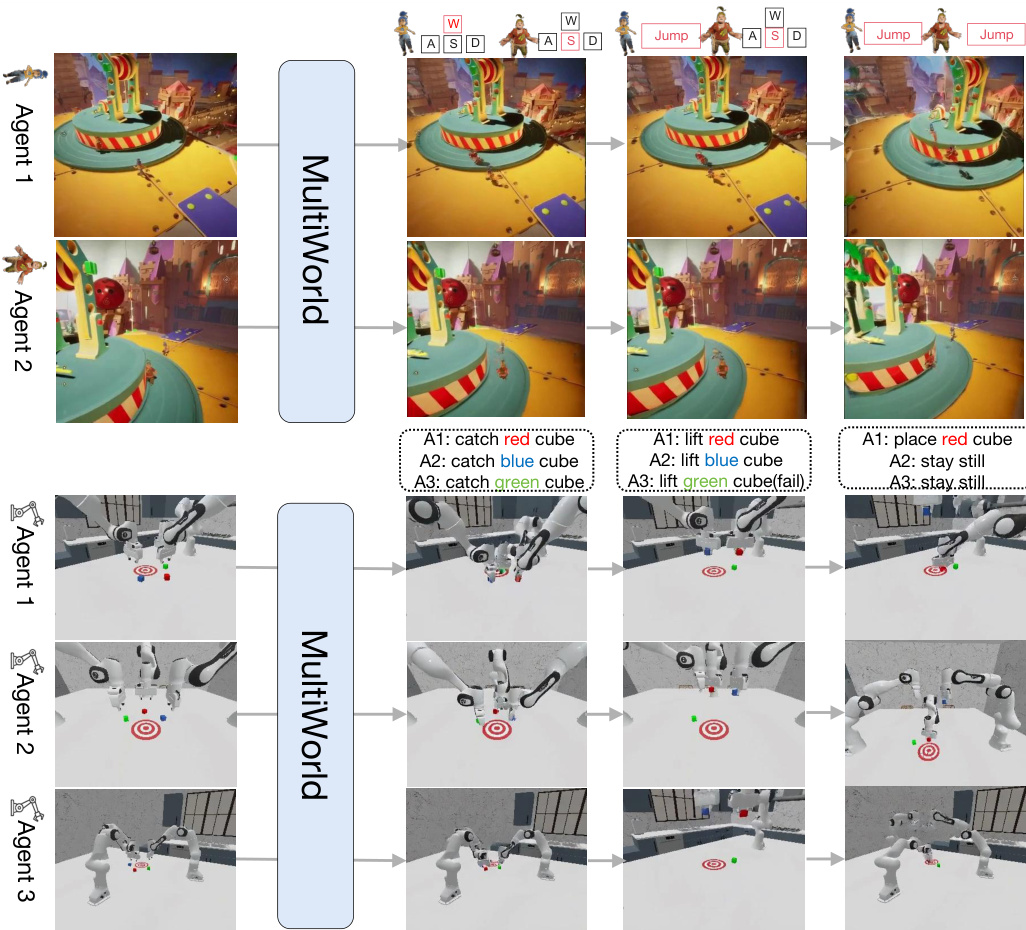
MultiWorld is evaluated across multi-player video games and multi-robot manipulation tasks to validate its scalability, action-following accuracy, and multi-view consistency. Comparative experiments demonstrate that the framework outperforms existing baselines by effectively modeling inter-agent interactions and maintaining structural integrity across synchronized viewpoints. Ablation studies further confirm that the proposed architectural modules are essential for enhancing motion fidelity, preventing agent disappearance, and enabling realistic long-horizon simulations.
The authors conduct an ablation study to evaluate the contributions of key components in their MultiWorld framework, focusing on visual quality and action-following performance. Results show that adding the Multi-Agent Condition Module improves action-following ability, while incorporating the Global State Encoder enhances multi-view consistency, with both components together leading to superior overall performance. Adding the Multi-Agent Condition Module improves action-following ability. Incorporating the Global State Encoder enhances multi-view consistency. Combining both modules leads to the best overall performance in visual quality and action-following.

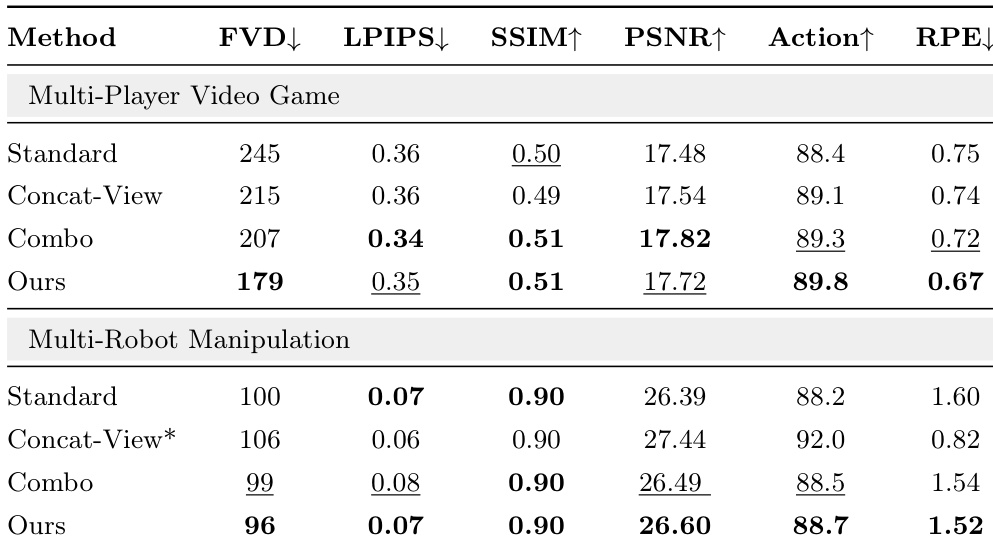
The authors evaluate MultiWorld against baseline methods in multi-player video games and multi-robot manipulation scenarios, demonstrating that their approach consistently outperforms all baselines across metrics such as visual quality, action-following, and multi-view consistency. The results highlight the effectiveness of the framework's components in improving both perceptual fidelity and geometric coherence in multi-agent, multi-view settings. MultiWorld consistently outperforms all baselines in both video game and robotic manipulation scenarios across multiple evaluation metrics. The framework achieves superior visual quality and action-following ability, with the best performance in metrics like FVD, PSNR, and SSIM. MultiWorld demonstrates improved multi-view consistency, as indicated by lower reprojection error compared to baselines.
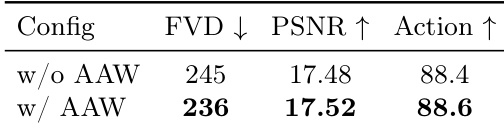
The authors conduct an ablation study to evaluate the impact of Adaptive Action Weighting on visual quality and action-following ability. The results show that incorporating this mechanism leads to improvements in both metrics, with the method achieving higher performance in terms of visual quality and action-following compared to the baseline without it. Adaptive Action Weighting improves both visual quality and action-following ability The method with Adaptive Action Weighting achieves higher performance in visual quality and action-following compared to the baseline without it Incorporating Adaptive Action Weighting leads to improvements in both visual quality and action-following metrics
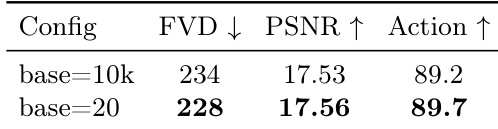
The ablation study examines the impact of different base frequencies in Agent Identity Embedding on visual quality and action-following performance. Results show that a lower base frequency leads to improvements in all evaluated metrics, indicating better alignment with the number of agents and enhanced control over multi-agent actions. A lower base frequency in Agent Identity Embedding improves action-following ability and visual quality. The configuration with base=20 achieves better performance across all metrics compared to base=10k. Reducing the base frequency enhances the model's ability to distinguish between agents and follow actions accurately.
The authors conduct an ablation study to evaluate the impact of different backbone choices for the Global State Encoder in the MultiWorld framework. Results show that the VGGT backbone achieves the best performance across multiple metrics, outperforming other backbones and the baseline without a global state encoder. The VGGT-based encoder improves both visual quality and multi-view consistency compared to alternatives. The VGGT backbone outperforms other backbones in visual quality and multi-view consistency The VGGT-based Global State Encoder achieves the best results across all evaluated metrics The absence of a global state encoder leads to the worst performance across all metrics

Through ablation studies and comparative evaluations in multi-player video games and robotic manipulation, the authors validate the effectiveness of the MultiWorld framework and its individual components. The results demonstrate that the Multi-Agent Condition Module, Global State Encoder with a VGGT backbone, and Adaptive Action Weighting collectively enhance action-following, visual quality, and multi-view consistency. Furthermore, optimizing the Agent Identity Embedding with a lower base frequency improves the model's ability to distinguish between agents and accurately follow multi-agent actions.