Command Palette
Search for a command to run...
DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
DeVI: Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation
Hyeonwoo Kim Jeonghwan Kim Kyungwon Cho Hanbyul Joo
Abstract
Recent advances in video generative models enable the synthesis of realistic human-object interaction videos across a wide range of scenarios and object categories, including complex dexterous manipulations that are difficult to capture with motion capture systems. While the rich interaction knowledge embedded in these synthetic videos holds strong potential for motion planning in dexterous robotic manipulation, their limited physical fidelity and purely 2D nature make them difficult to use directly as imitation targets in physics-based character control. We present DeVI (Dexterous Video Imitation), a novel framework that leverages text-conditioned synthetic videos to enable physically plausible dexterous agent control for interacting with unseen target objects. To overcome the imprecision of generative 2D cues, we introduce a hybrid tracking reward that integrates 3D human tracking with robust 2D object tracking. Unlike methods relying on high-quality 3D kinematic demonstrations, DeVI requires only the generated video, enabling zero-shot generalization across diverse objects and interaction types. Extensive experiments demonstrate that DeVI outperforms existing approaches that imitate 3D human-object interaction demonstrations, particularly in modeling dexterous hand-object interactions. We further validate the effectiveness of DeVI in multi-object scenes and text-driven action diversity, showcasing the advantage of using video as an HOI-aware motion planner.
One-sentence Summary
The DeVI framework enables physically plausible dexterous robotic manipulation by imitating text-conditioned synthetic videos through a hybrid tracking reward that integrates 3D human tracking with robust 2D object tracking, achieving superior zero-shot generalization across diverse objects compared to existing methods that rely on 3D kinematic demonstrations.
Key Contributions
- The paper introduces DeVI, a framework that utilizes video diffusion models as motion planners to enable physically plausible dexterous human-object interaction in physics simulations without requiring high-quality 3D motion capture data.
- This work presents a hybrid tracking reward system that combines 3D human tracking with robust 2D object tracking and visual HOI alignment to reconstruct object-aligned motion without the need for 6D object pose estimation.
- Extensive experiments demonstrate that the method achieves zero-shot generalization across diverse objects and outperforms existing approaches that rely on 3D kinematic demonstrations, particularly in modeling complex dexterous hand-object interactions.
Introduction
Achieving realistic dexterous human-object interaction (HOI) in physics simulations is essential for training robotic agents to perform complex tasks like grasping or functional manipulation. While video generative models can synthesize diverse interaction scenarios, they produce 2D content that lacks the physical fidelity and 3D depth required for direct imitation in a physics engine. Existing imitation methods often rely on high-quality 3D motion capture data, which is difficult to scale across diverse objects and complex movements. The authors propose DeVI, a framework that uses text-conditioned synthetic videos as an interaction-aware motion planner. They introduce a hybrid tracking reward that combines 3D human tracking with robust 2D object tracking to overcome the imprecision of 2D generative cues, enabling zero-shot generalization for dexterous manipulation without requiring 3D demonstrations.
Method
The framework of DeVI (Dexterous Video Imitation) is designed to learn a humanoid control policy that enables a simulated character to imitate complex human-object interactions (HOI) from 2D video inputs. The overall process begins with a 3D scene initialization, where a human, parameterized by the SMPL-X model, and a target object are placed in a tabletop environment. To enhance realism for video synthesis, the SMPL-X mesh is replaced with a textured human mesh from the THuman2.0 dataset, which is deformed via linear blend skinning to match the pose of the initial SMPL-X model. This textured scene is then rendered from a set of predefined camera viewpoints to generate a 2D image, which serves as the starting point for video generation.
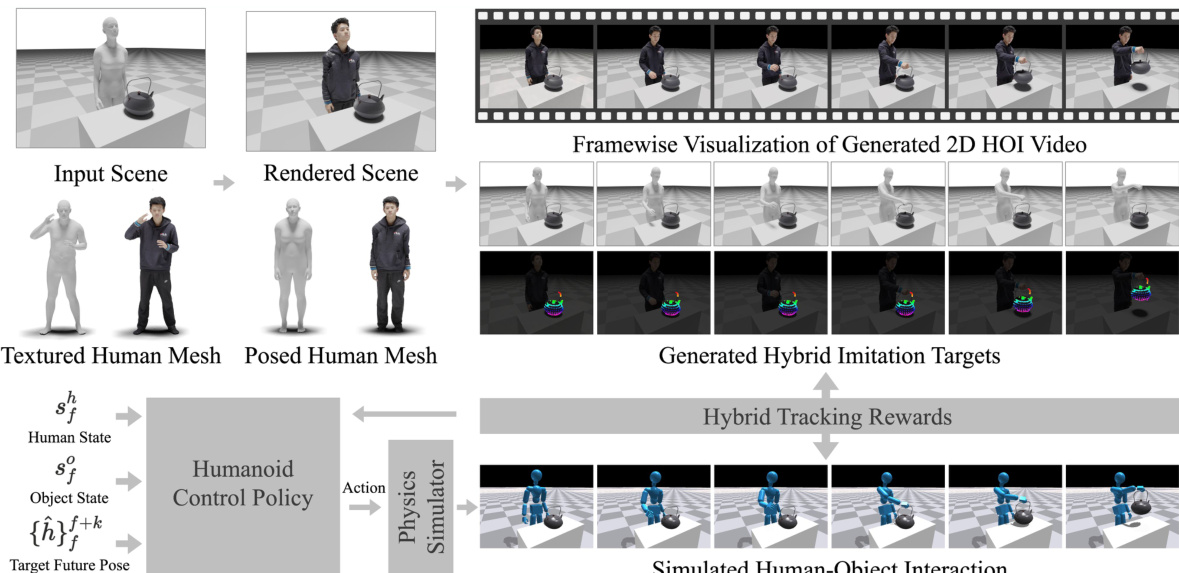
As shown in the figure below, the rendered scene is used to generate a 2D HOI video using a pre-trained video diffusion model. This video, which is conditioned on a text prompt describing the desired interaction, contains the visual information needed to extract hybrid imitation targets. The goal of the method is to learn a policy that can replicate the motion observed in the video, even when the original 3D motion capture data is not available.

The hybrid imitation targets are extracted from the generated 2D video. For the human component, an off-the-shelf monocular motion estimator is applied to recover a 3D SMPL-X human motion sequence. This initial reconstruction is refined through a Visual HOI Alignment optimization process, which jointly aligns the estimated human pose with both the 2D projections in the video and the initial 3D object state. This alignment involves minimizing a composite loss function that includes 2D projection losses for body and hand joints, a temporal consistency loss, and a one-sided Chamfer distance loss to enforce contact between the human and the object. For the object component, a 2D trajectory is constructed by tracking visible object vertices across the video frames using a video tracker, which provides the 2D object reference.
The humanoid control policy, πθ, is trained to track these hybrid targets. The policy takes as input the current character state st (comprising human and object states) and a goal vector gt, which is defined as the future k entities of the 3D human motion reference. The learning objective is to maximize the expected discounted cumulative reward, J(θ), which is optimized using Proximal Policy Optimization (PPO). The reward function is designed to be a product of three components: a human tracking reward (Rh), an object tracking reward (Ro), and a contact reward (Rcontact).
The human tracking reward encourages the simulated character to match the 3D human motion reference, combining joint position, velocity, and rotation differences, along with a power penalty for smooth and physically plausible actions. The object tracking reward, Ro, is defined as an exponential function of the negative squared error between the 2D projection of the simulated object and the 2D object trajectory extracted from the video. The contact reward, Rcontact, is a product of a contact force reward and a contact distance reward. It is modulated by a binary contact label, ψt, which is automatically estimated from the video by analyzing the motion of the object vertices and hand joints to infer the timing of contact.
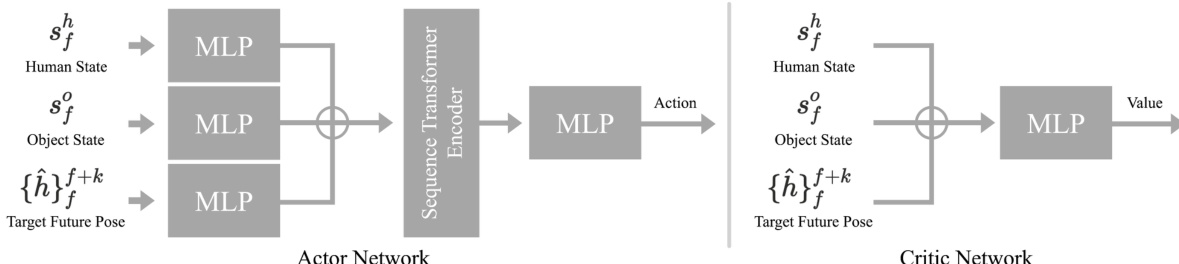
The actor-critic network architecture for the control policy is illustrated in the figure below. The actor network, which outputs the action, consists of separate Multi-Layer Perceptrons (MLPs) for the human state, object state, and target future pose. These representations are concatenated and passed through a sequence transformer encoder for joint encoding, followed by a multi-layer MLP to produce the action. The critic network, which estimates the value function, takes the same inputs, concatenates them, and passes them through a multi-layer MLP. The policy is trained by updating the actor and critic networks using the PPO algorithm, with the hybrid tracking reward guiding the learning process.
Experiment
The researchers evaluate DeVI by comparing its ability to imitate dexterous human-object interactions against state-of-the-art 3D motion imitation baselines using the GRAB dataset and diverse synthetic video scenarios. The experiments validate that the proposed hybrid imitation target and visual HOI alignment effectively bridge the gap between 2D video cues and 3D physics-based control. Results demonstrate that the framework achieves superior motion accuracy and higher success rates than methods relying on complex 6D poses, while also showing strong text controllability and generalization to multi-object scenes.
The authors evaluate their method against baselines using success ratios across multiple metrics, showing that their approach achieves higher success rates in imitating human-object interaction motions. The results indicate that the proposed method outperforms baselines in both human and object tracking accuracy, particularly under relaxed thresholds. The method demonstrates robust performance even when using 2D object trajectories instead of 6D poses, highlighting the effectiveness of the hybrid imitation target. DeVI achieves higher success ratios than baselines across all evaluation metrics and thresholds. The method outperforms baselines in both human and object tracking accuracy, especially under relaxed constraints. DeVI demonstrates robust performance using 2D object trajectories, showing the effectiveness of the hybrid imitation target.
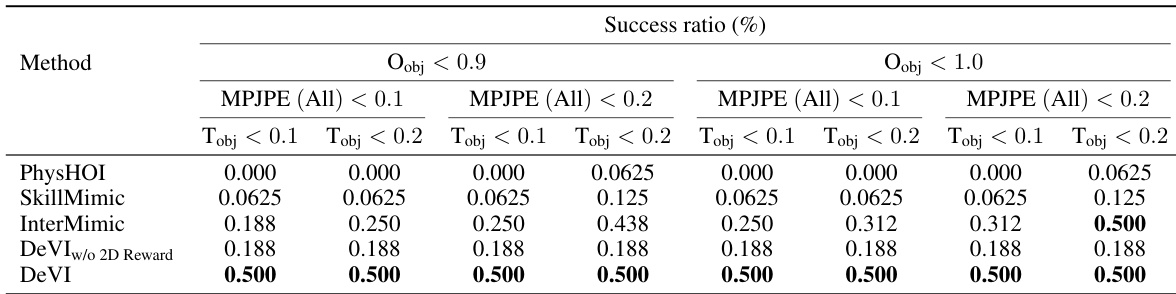
The authors compare their method DeVI against several baselines on a dataset involving human-object interactions, using metrics for human and object motion accuracy. Results show that DeVI achieves lower error in human motion tracking and object trajectory, particularly in hand and root joint positions, and outperforms baselines in success rates. Ablation studies confirm the importance of visual HOI alignment for accurate hand-object interaction and demonstrate that using 2D object trajectories as a reward is effective compared to 6D pose tracking. DeVI outperforms baselines in human motion tracking and object trajectory accuracy, especially for hand and root joint positions. Visual HOI alignment significantly improves the alignment of human motion with both video frames and 3D objects, enhancing interaction realism. Using 2D object trajectories as a reward leads to better performance than 6D pose tracking, indicating a more effective and practical approach for imitation.
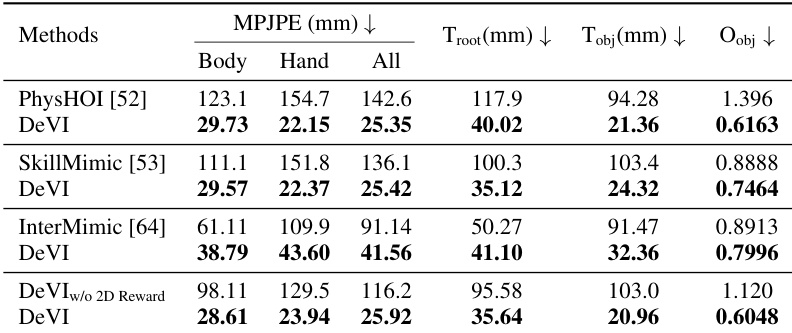
The authors evaluate the effectiveness of visual HOI alignment in their framework by comparing results with and without the alignment component. Results show that incorporating visual HOI alignment significantly improves the alignment between the generated 3D human motion and the input video, particularly for hand joints, and enhances the accuracy of hand-object interactions. The method achieves lower error in human pose tracking and better contact precision with the object compared to the baseline without alignment. Visual HOI alignment improves the alignment of 3D human motion with the input video, especially for hand joints. The method with visual HOI alignment achieves better contact precision and reduces the distance between hands and objects during interaction. Incorporating visual HOI alignment leads to more accurate and plausible hand-object interactions in the simulated motions.
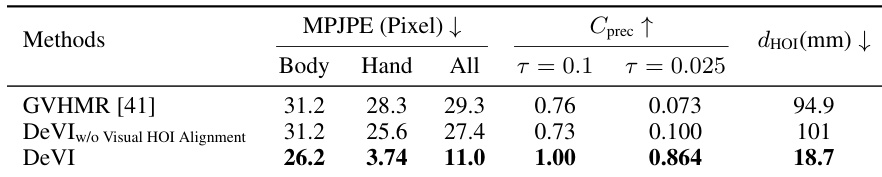
The authors evaluate DeVI against several baselines using human and object motion accuracy metrics to validate its ability to imitate human-object interactions. The results demonstrate that DeVI achieves superior tracking accuracy and higher success rates, particularly in hand and root joint positioning. Ablation studies further confirm that visual HOI alignment significantly enhances interaction realism and contact precision, while the use of 2D object trajectories provides a robust and effective imitation target.