Command Palette
Search for a command to run...
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Abstract
Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce , a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
One-sentence Summary
The ClawMark Team introduces CLAWMARK, a benchmark of 100 tasks across 13 professional scenarios that evaluates seven frontier coworker agents on multi-turn, multi-day workflows within a stateful sandboxed environment, utilizing 1,537 deterministic Python checkers to score outcomes and reveal that even the strongest model achieves only 20.0% strict task success while struggling to adapt to exogenous environment updates.
Key Contributions
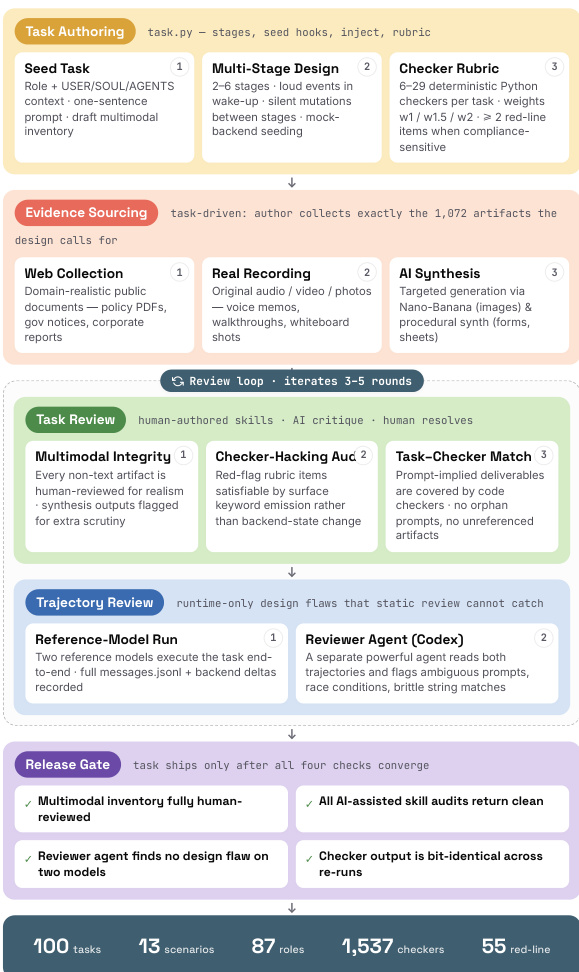
- CLAWMARK is introduced as a benchmark for coworker agents that integrates multi-turn multi-day workflows with a stateful sandboxed environment where exogenous updates occur independently between agent turns.
- The evaluation framework implements a deterministic scoring protocol using 1,537 Python checkers to verify post-execution service states, thereby eliminating reliance on LLM-as-judge assessments.
- Benchmarking seven frontier agent systems reveals that while the highest weighted score reaches 75.8, strict task success remains at 20.0%, with performance degrading after initial environment updates to underscore adaptation as a primary challenge.
Introduction
As language models evolve from single-session tools into persistent digital coworkers, evaluating them in dynamic, real-world office environments has become essential. Current benchmarks struggle to capture this reality because they treat interactions as static snapshots, ignore external state changes that occur independently of the agent, and rely almost exclusively on text-based inputs. To address these gaps, the authors introduce CLAWMARK, a benchmark that simulates multi-day coworker workflows across stateful sandboxed services like email, calendars, and shared drives. The framework subjects agents to exogenous environment updates and untranscribed multimodal evidence while replacing subjective LLM judges with a deterministic, rule-based scoring protocol. By providing a reproducible evaluation harness and testing seven frontier models, the authors establish a rigorous standard for measuring persistent agent adaptation, external state tracking, and multimodal integration.
Dataset
1. Dataset composition and sources
- The authors introduce CLAWMARK, a benchmark consisting of 100 tasks distributed across 13 professional scenarios and 87 distinct in-task roles.
- The corpus relies on 1,072 raw multimodal artifacts, including photos, audio, scanned PDFs, video, and spreadsheets.
- Evidence is sourced through three channels: web collection of public domain documents, original recordings, and targeted AI synthesis, all tagged with provenance information.
2. Key details for each subset
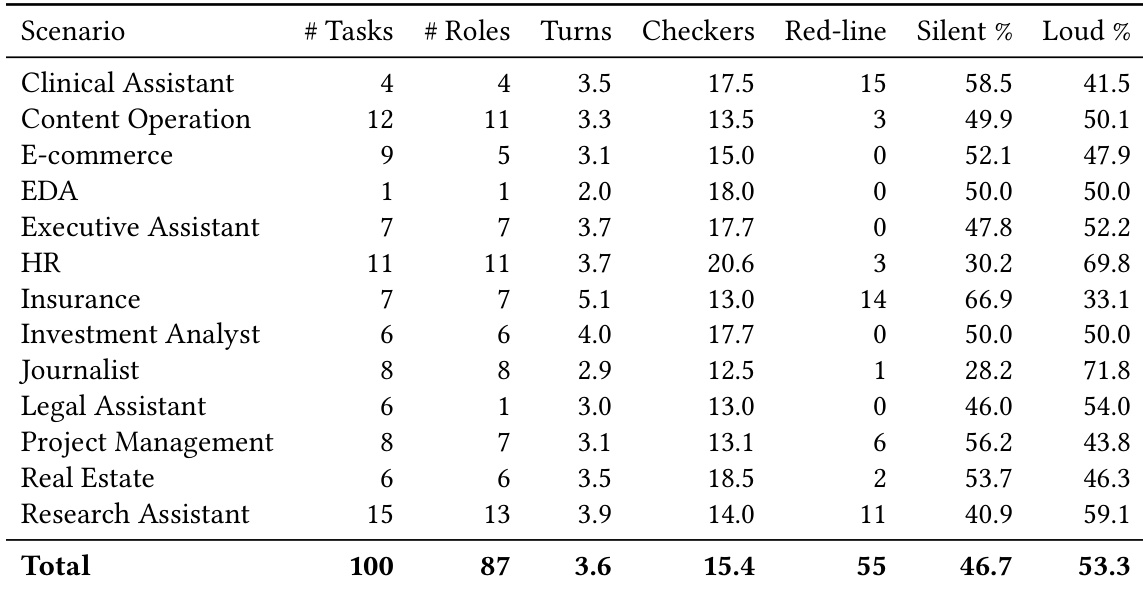
- The dataset does not use traditional training or test splits. Instead, tasks are organized by professional domain, ranging from general office roles to specialized fields like clinical assistance and electronic design automation.
- Each task spans two to six turns, with one turn representing a single in-universe working day.
- Tasks contain between six and twenty-nine weighted evaluation checkers, including fifty-five strict red-line constraints that enforce hard rules.
- Descriptive metadata tracks the mean share of silent versus loud between-turn mutations, though this classification is used solely for corpus characterization and does not influence scoring.
3. How the paper uses the data
- The authors use the dataset exclusively for evaluation rather than model training, so no training splits or mixture ratios are applied.
- Seven frontier agent systems are benchmarked using a single, framework-agnostic harness to isolate model performance differences.
- Scoring is entirely rule-based. The authors employ 1,537 deterministic Python checkers that inspect the post-execution state of five sandboxed services including filesystem, email, calendar, knowledge base, and spreadsheet.
- The evaluation pipeline guarantees deterministic results by requiring bit-identical checker verdicts across independent re-runs, explicitly avoiding LLM-as-judge methods.
4. Processing and metadata construction
- No cropping or preprocessing is applied to the multimodal evidence; raw files are delivered directly to the agents for independent parsing.
- Task specifications are constructed using a single task.py file per scenario, which defines turn structures, service seed hooks, between-turn injection scripts, and weighted checker rubrics.
- The environment evolves independently between turns through two mutation types: loud events announced in wake-up prompts and silent mutations injected directly into services without notification.
- A strict release gate filters the corpus during construction, requiring human sign-off, successful AI audits, and consistent re-run results. Tasks that fail deterministic verification more than twice are redesigned or removed.
Method
The authors leverage a modular framework designed to bridge natural-language task specifications with executable, multi-turn, multi-service agent evaluations. The core of the system revolves around a task definition file, task.py, which encapsulates all necessary components for a single evaluation episode. This file defines four key elements: turn entries, each an asynchronous function specifying the wake-up prompt, allowed tools, and service-side mutation hooks; inject layers, which provide evidence files introduced at the beginning of each turn; checker functions, deterministic Python routines that assess post-turn service state against rubric items; and a rubric mapping that assigns weights and turn assignments to each checker, with red-line checkers distinguished by ID convention and a fixed high weight.
The framework begins with a loader that parses the task definition file and associated staged input files into runtime objects. The task_loader.py module reads task.py, validates required fields, collects stage-specific evidence from the assets/ and inject/ directories, and builds the task object. This task object, defined in models.py, contains the prompt, stage functions, rubric, and environment configuration. A shared context, managed by context.py, holds the service manager and current snapshots of the backend services. This structured representation allows the orchestrator to execute each turn within an isolated docker-compose stack, which includes the agent container and five services: a Docker-mounted filesystem, GreenMail SMTP/IMAP, Notion API, Google Sheets API, and a Radicale CalDAV server.
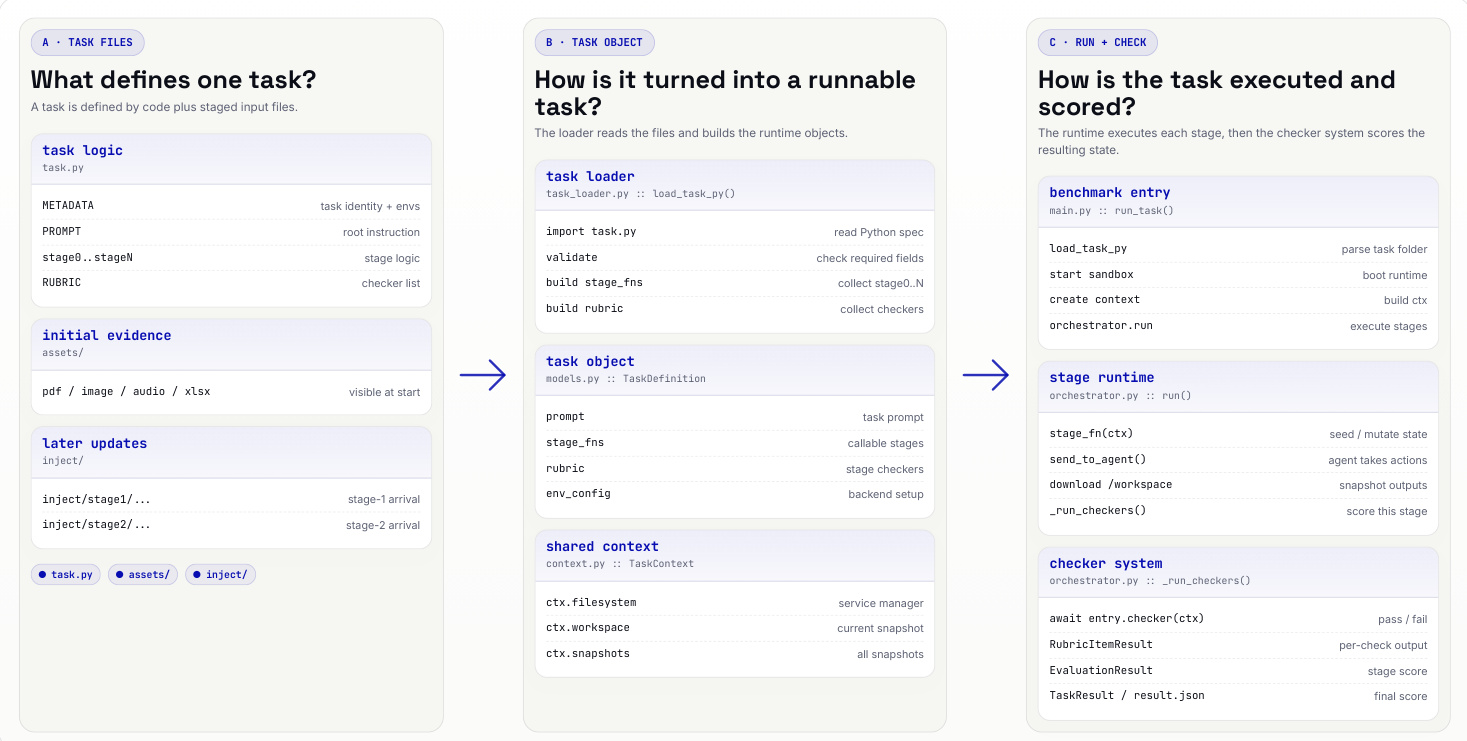
The execution process proceeds in stages. The benchmark entry point, main.py, parses the task folder, boots the runtime, and builds the context. The orchestrator then executes each stage, starting with a seed or mutate state, followed by the agent taking actions, downloading outputs, and capturing a snapshot. After each turn, the checker system, implemented in orchestrator.py, runs all relevant checkers against the current service state. The checker module evaluates each rubric item, returning a pass/fail outcome. The results are aggregated into a final TaskResult record, which includes the per-checker outcomes and the final score, ensuring a comprehensive and deterministic evaluation of the agent's performance across all turns.
Experiment
The evaluation assesses seven frontier models across 100 tasks in 13 professional scenarios using a deterministic, sandboxed framework to measure end-to-end agent performance. The main benchmark validates general capability and domain specialization, revealing that top systems remain closely clustered with no single model dominating all tasks. Turn-by-turn trajectory analysis examines adaptive reasoning under dynamic environment changes, demonstrating that most agents struggle to recover after external state mutations, while a failure-mode taxonomy isolates structural weaknesses by showing that silent-change detection and backend writeback errors dominate overall mistakes. Collectively, these experiments indicate that reliable professional deployment requires robust state synchronization and strict compliance adherence, as aggregate scores often mask critical trajectory and constraint violations.
The experiment evaluates multiple models across a diverse set of professional scenarios, with results showing significant variation in performance across different domains. The benchmark highlights that no single model dominates all scenarios, and that models exhibit distinct strengths and weaknesses in handling complex, multi-turn tasks involving external state changes and compliance constraints. Performance is further influenced by the model's ability to recover after environmental shifts and avoid critical failure modes such as missing silent updates or failing to commit backend actions. Performance varies significantly across scenarios, with models showing specialization rather than a uniform top ranking. The majority of failures occur in detecting silent changes and committing backend actions, indicating key areas for improvement. Models struggle to recover after the first exogenous environment change, with most remaining below their initial performance level by the final turn.
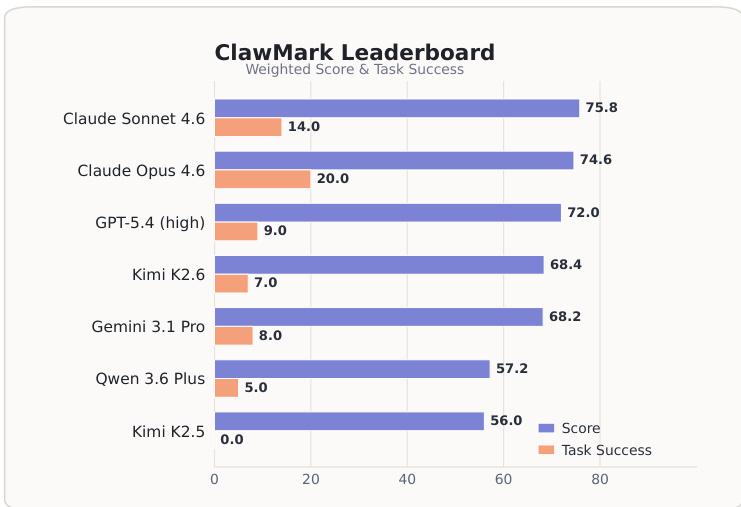
The authors evaluate seven frontier models on a benchmark that measures coworker-agent behavior across multi-turn, multi-day workflows, focusing on responses to exogenous environment changes and compliance with safety constraints. Results show that no model achieves high performance across all metrics, with significant drops in performance after the first external mutation and a high failure rate in detecting silent changes and committing backend actions. The top models differ in strengths across scenarios, and performance is not consistently correlated with resource usage or tool efficiency. No model achieves high task success or full compliance, with the highest score falling short of 76 and the best task success at 20% Models show significant performance drops after the first exogenous environment change, with most failing to recover to initial levels Failure rates are highest for detecting silent changes and committing backend actions, indicating key weaknesses in state management and action execution
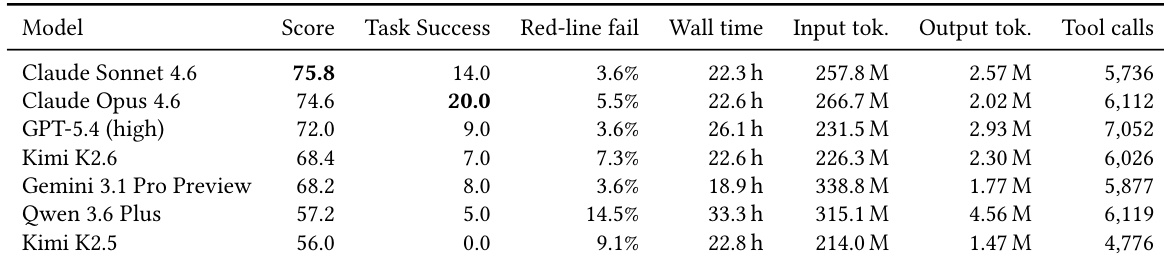
The authors evaluate seven frontier models on a benchmark covering specialized professional scenarios, with results showing that no model achieves high overall performance across all tasks. The top models cluster closely in overall score, but their performance varies significantly by scenario, with no single model excelling across all domains. The evaluation highlights that even the best models struggle with end-to-end task completion, and performance drops sharply after exogenous environmental changes, indicating limited recovery capabilities. No single model dominates all scenarios, with top performers varying by task type and showing no consistent leadership across domains. Performance declines significantly after the first environmental change, with most models failing to recover fully by the final day of the multi-turn evaluation. The two highest-scoring models are also the most efficient in terms of action cost, suggesting a positive correlation between overall performance and computational efficiency.
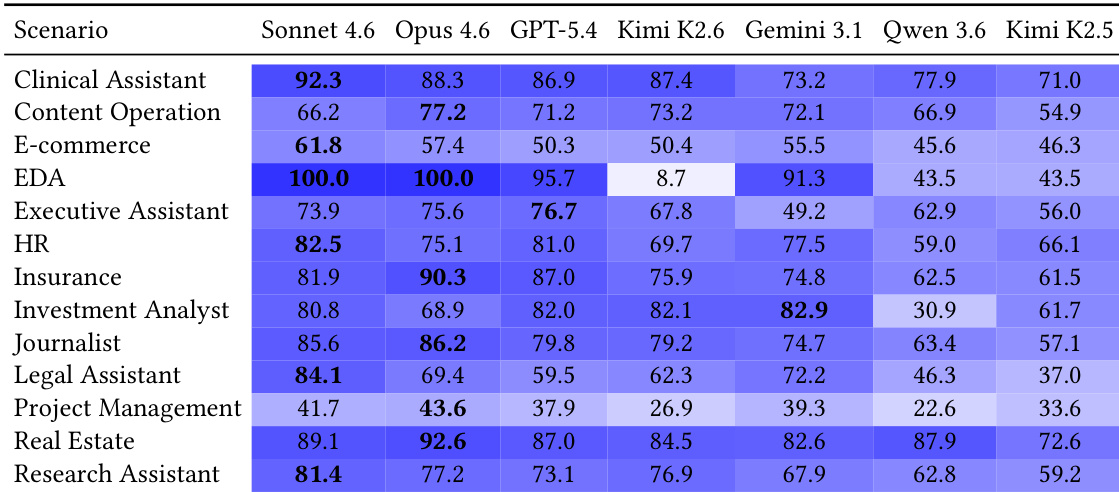
The authors evaluate seven frontier models on the ClawMark benchmark, which measures coworker-agent behavior across multi-turn, multi-day workflows with exogenous environment changes and multimodal evidence. Results show that no model achieves high task success, with the top model solving only about 20% of tasks fully, and performance varies significantly across scenarios, indicating specialization and room for improvement in handling structural failures like silent-change detection and backend writeback. No model achieves high task success, with the top performer solving only a small fraction of tasks fully. Performance varies across scenarios, with different models excelling in different domains, indicating specialization. Failures concentrate on structural challenges like silent-change detection and backend writeback, which are critical for real-world trustworthiness.
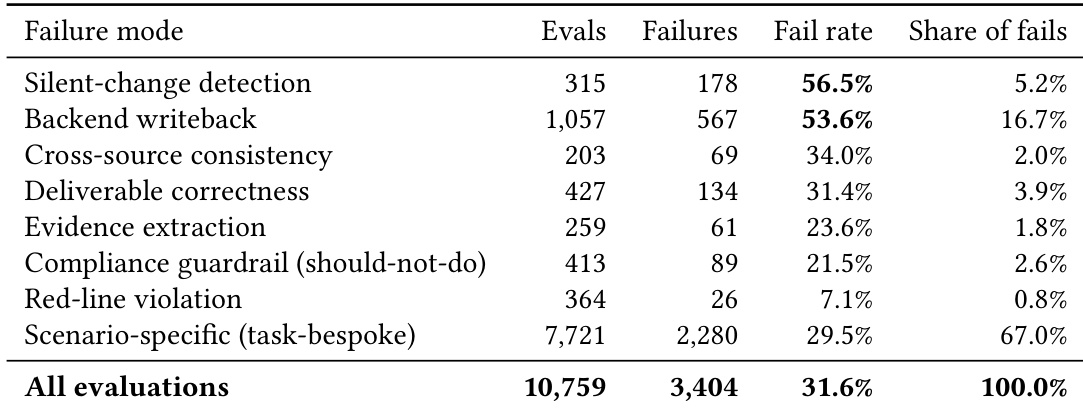
The authors analyze failure modes in a benchmark evaluating coworker-agent behavior, focusing on how models handle exogenous state changes and compliance constraints. The results show that failures are concentrated in two primary categories: silent-change detection and backend writeback, which have significantly higher failure rates than other evaluation types. Scenario-specific checks account for the majority of failures due to their high number rather than increased brittleness, while red-line violations, though rare, are concentrated in a small set of tasks and models. Silent-change detection and backend writeback are the dominant failure modes, with failure rates nearly double the benchmark-wide average. Scenario-specific checks contribute the largest share of failures, driven by their high number rather than higher per-evaluation brittleness. Red-line violations are rare overall but concentrated in specific tasks and models, indicating potential safety risks in otherwise high-performing trajectories.
The evaluation assesses multiple frontier models on a benchmark designed to validate coworker-agent capabilities across multi-turn, multi-day professional workflows that incorporate exogenous environmental shifts and compliance constraints. Results indicate that no single model demonstrates consistent superiority across all domains, revealing clear performance specialization rather than uniform capability. Models experience significant performance degradation following initial environmental changes and generally fail to recover to baseline levels throughout extended interactions. The primary weaknesses concentrate on detecting silent state updates and executing backend actions, highlighting critical gaps in state management and long-term reliability that limit overall task success.