Command Palette
Search for a command to run...
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
Abstract
Autonomous scientific research is significantly advanced thanks to the development of AI agents. One key step in this process is finding the right scientific literature, whether to explore existing knowledge for a research problem, or to acquire evidence for verifying assumptions and supporting claims. To assess AI agents' capability in driving this process, we present AutoResearchBench, a dedicated benchmark for autonomous scientific literature discovery. AutoResearchBench consists of two complementary task types: (1) Deep Research, which requires tracking down a specific target paper through a progressive, multi-step probing process, and (2) Wide Research, which requires comprehensively collecting a set of papers satisfying given conditions. Compared to previous benchmarks on agentic web browsing, AutoResearchBench is distinguished along three dimensions: it is research-oriented, calling for in-depth comprehension of scientific concepts; literature-focused, demanding fine-grained utilization of detailed information; and open-ended, involving an unknown number of qualified papers and thus requiring deliberate reasoning and search throughout. These properties make AutoResearchBench uniquely suited for evaluating autonomous research capabilities, and extraordinarily challenging. Even the most powerful LLMs, despite having largely conquered general agentic web-browsing benchmarks such as BrowseComp, achieve only 9.39% accuracy on Deep Research and 9.31% IoU on Wide Research, while many other strong baselines fall below 5%. We publicly release the dataset and evaluation pipeline to facilitate future research in this direction. We publicly release the dataset, evaluation pipeline, and code at https://github.com/CherYou/AutoResearchBench.
One-sentence Summary
AutoResearchBench evaluates AI agents on autonomous scientific literature discovery through Deep Research and Wide Research tasks that demand in-depth conceptual comprehension, fine-grained full-text analysis, and deliberate open-ended reasoning, exposing severe performance limitations in state-of-the-art LLMs that achieve only 9.39% accuracy and 9.31% IoU respectively, far below their capabilities on general web-browsing benchmarks.
Key Contributions
- AutoResearchBench is introduced as a large-scale benchmark for evaluating autonomous scientific literature discovery, comprising Deep Research and Wide Research tasks that require progressive multi-step probing and comprehensive set collection within a controlled corpus of over three million arXiv papers.
- A controlled evaluation environment is constructed over this corpus with up-to-date full-text extraction and search tools, requiring agents to navigate research-oriented, literature-focused, and open-ended queries that demand fine-grained utilization of detailed academic content.
- Experimental results demonstrate that frontier language models achieve only 9.39% accuracy on Deep Research and 9.31% IoU on Wide Research, exposing persistent limitations in scientific reasoning, long conjunctive query handling, and iterative reflection that position literature discovery as a distinct capability frontier beyond general web browsing.
Introduction
The emergence of LLM-driven AI scientists has positioned autonomous research as a practical objective, with scientific literature discovery serving as a foundational capability for verifying hypotheses, identifying appropriate methodologies, and mapping existing knowledge. Prior evaluation frameworks, however, primarily measure general web navigation and fail to assess the technical depth, open-ended constraint satisfaction, and exhaustive reasoning required to navigate peer-reviewed corpora. Existing academic benchmarks remain constrained by small scales, uncontrolled environments, or a lack of dynamic agent testing. To bridge this gap, the authors introduce AutoResearchBench, a large-scale benchmark comprising one thousand curated problems that evaluate both targeted paper identification and comprehensive literature collection. Built over a controlled environment of over three million arXiv papers, the benchmark demonstrates that current frontier models struggle significantly with multi-hop scientific reasoning, highlighting a distinct capability frontier for autonomous research agents.
Dataset
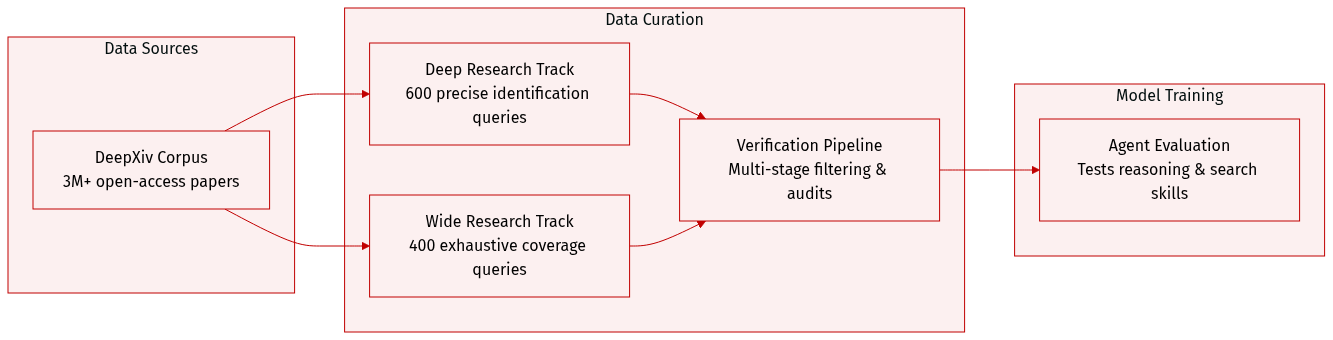
- Dataset Composition and Sources: The authors introduce AutoResearchBench, a benchmark constructed from a controlled DeepXiv corpus containing over three million open-access arXiv papers with structured metadata and full-text access. The dataset comprises 1,000 expert-curated queries spanning eight core computer science domains.
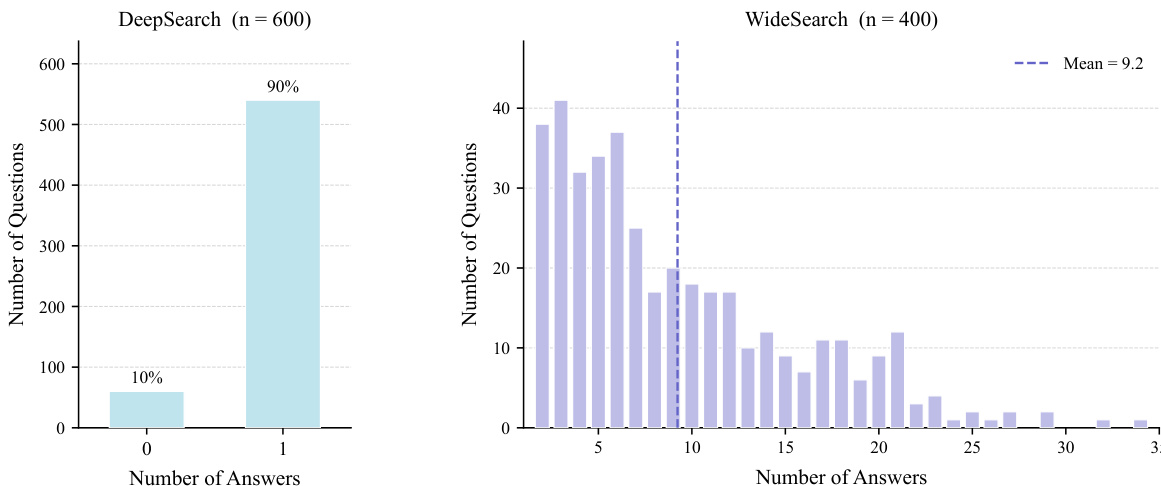
- Subset Details: The benchmark divides into two complementary task families. Academic Deep Research contains 600 queries focused on precise paper identification, with 90% targeting a single valid paper and 10% intentionally unsatisfiable to test an agent's ability to recognize infeasible constraints. Academic Wide Research contains 400 queries focused on exhaustive coverage, yielding an average of 9.23 valid answers per query with a long-tail distribution ranging from under ten to over twenty candidates.
- Model Usage and Data Handling: The authors use the dataset exclusively as an evaluation benchmark rather than a training resource. No training splits or mixture ratios are defined. Instead, they deploy frontier LLMs and autonomous agents within a controlled DeepXiv search environment to measure long-horizon browsing, multi-hop reasoning, and constraint satisfaction capabilities.
- Processing and Construction Pipeline: The authors employ a full-text-first human-machine pipeline to ensure high difficulty and factual grounding. Key processing steps include target selection that prioritizes technically substantive papers with 10 to 100 citations while excluding surveys. Full-text constraint mining extracts subtle methodological details, proof steps, and citation relationships while deliberately avoiding headline keywords. Constraint fuzzification and iterative pruning paraphrase local evidence to retain only minimally sufficient clues that uniquely isolate the target. Wide Research undergoes candidate expansion, abstract screening, automated ArXiv ID normalization, and month-level temporal calibration. Finally, a multi-stage adversarial verification process applies multi-query shortcut screening, timed human retrieval with a 10-minute budget, and corpus-level uniqueness audits to eliminate trivial or ambiguous instances.
Method
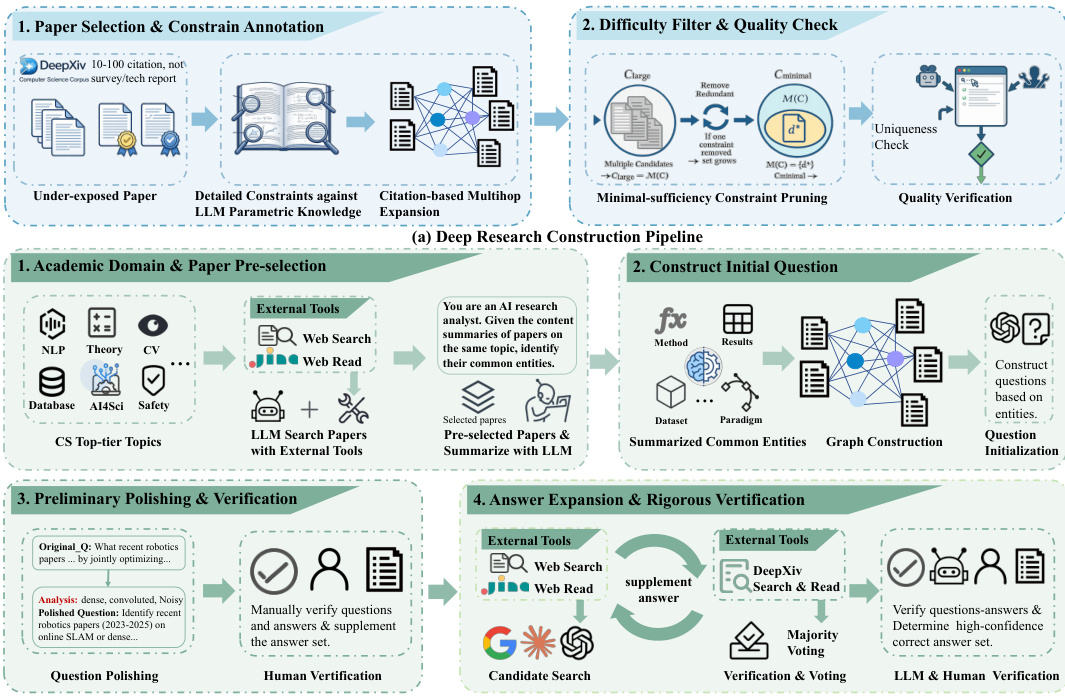
The framework for AutoResearchBench is structured around a systematic pipeline designed to evaluate an agent's ability to autonomously conduct academic research by searching, browsing, and reasoning over scientific literature. The overall process begins with task creation, where the agent operates within a search environment defined by an initial query q and a corpus D. At each step t, the agent's state st comprises the query, interaction history ht, and the subset of documents Dt observed so far. The agent iteratively engages in reasoning and tool usage—either through a search tool like DeepXiv or web search—or terminates by providing a predicted answer set Y^(q), which aims to approximate the true set of documents Y∗(q) that satisfy all implicit constraints of the query. Unlike conventional question-answering tasks, the decisive evidence in this setting often resides in non-traditional sections such as appendices, figure captions, or citation contexts.
The core of the methodology involves a four-stage construction pipeline for generating high-quality research tasks, which is grounded in academic entity graphs. The first stage, domain-specific candidate sourcing, identifies high-level research themes across core computer science domains and retrieves preliminary candidate pools using external search tools. These candidates are then filtered and summarized by a large language model (LLM) to ensure topical cohesion and representativeness. In the second stage, structural abstraction and query formulation, shared multidimensional attributes—such as methods, datasets, and results—are extracted from the candidate papers to construct an entity graph. This graph is then translated into an initial query encoding a strict conjunction of these shared constraints. The third stage, query refinement and initial verification, rewrites the query into natural scientific language while preserving its logical structure. Human annotators verify the alignment between the query and the candidate set, manually augmenting it with missing valid papers to establish a reliable initial approximation of Y∗(q).
The fourth and final stage, iterative expansion and rigorous auditing, aims to achieve near-complete coverage. The candidate set is expanded iteratively using search tools, and newly retrieved documents undergo full-text analysis. A majority-voting scheme involving three independent frontier LLMs—Gemini-3.1-pro, Claude 4.6-Sonnet, and GPT-5.4—evaluates each document for compliance with the query constraints. These models are instructed to be conservative, marking a condition as violated unless unambiguously demonstrated in the text. A final verdict is determined by a majority vote on the binary satisfies judgment. To ensure robustness, domain experts perform randomized audits on 50% of the papers that pass the multi-model filter. If the human-validated compliance rate for any query falls below a 75% precision threshold, the entire candidate pool for that query is subjected to a renewed cycle of multi-model voting and manual spot-checking. This iterative refinement continues until the threshold is met, effectively mitigating model hallucinations and ensuring high semantic consistency.
The evaluation framework operates within a single-tool ReAct loop, where the model alternates between free-form reasoning, selection of paper IDs from the latest search results, and either a structured search call or an explicit termination signal. The system prompt distinguishes between wide and deep research, encouraging multi-hop decomposition when necessary and enforcing a fixed output order: thinking, , and then Done. Each benchmark instance is processed asynchronously, with multiple independent trajectories supported for pass@k metrics. Inputs and outputs are line-oriented JSON records, enabling partial runs to be resumed by appending missing questions. Termination occurs when the model emits the finish marker, when a soft context budget is exceeded, when the turn cap is reached, or when the chat API fails.

The agent-tool interface exposes a search tool with a schema that accepts a required query string and an optional top_k parameter. The executor dispatches to the configured backend, reformats hits into a shared JSON structure, and injects them into the next user message inside <tool_response> tags for the following turn. For paper search, a POST request is issued with the natural-language query and k, returning ranked hits with metadata and sectioned full text. Each hit is post-processed in parallel: author lists longer than ten names are truncated to five leading and five trailing names, and a query-conditioned snippet is extracted from the beginning of the stored body. An auxiliary LLM compresses this snippet into a query-focused "evidence" string, which is shown as the paper's search_evidence. Failures or timeouts result in an empty hit list for that call. For web search, queries are prefixed to bias results toward arXiv, and two interchangeable connectors—programmatic web search or an alternate search+reader stack—are available. The default path uses the connector that returns both snippets and partial page text without a second fetch per URL. Each hit is capped to a large character window before the same query-conditioned summarization template is applied. The arXiv identifier shown to the agent is derived heuristically from the result URL when present.

The system prompt guides the agent through a strict ReAct workflow. In the reasoning phase, the agent first identifies the user's intent, determining whether the task is a wide search (multiple strict matches) or a deep search (at most one correct paper). It then decomposes the query into sub-questions if necessary and evaluates the candidate paper list from the latest tool response. In the acting phase, the agent either calls the search tool with a well-constructed query or issues a finish signal. The tool call must follow a specific format, with the function name and arguments provided in a JSON object within <tool_call> tags. The agent must output in a fixed order: thinking, candidate selection, and then either a tool call or the finish signal. This structured approach ensures that the agent's actions are grounded in evidence and align with the task requirements.
Experiment
The evaluation employs a standardized ReAct-based agent framework interacting with a specialized academic search tool to validate model capabilities across two distinct literature retrieval paradigms: precise target isolation and comprehensive set completion. Main experiments reveal that current agents struggle significantly with scientific search, as extended reasoning and increased interaction budgets frequently degrade into redundant exploration rather than improving accuracy. Supplementary analyses further demonstrate that specialized academic indexing outperforms open-web tools, explicit reasoning steps often increase latency without benefit, and test-time scaling primarily addresses decision instability rather than recall gaps. Ultimately, the findings indicate that effective evidence utilization and rigorous constraint filtering are far more critical than search volume or raw reasoning steps for advancing agentic academic discovery.
The authors analyze the performance of various models on deep and wide research tasks using a standardized agent framework and a curated arXiv corpus. Results show that top-performing models achieve low accuracy and IoU scores, indicating significant challenges in precise document retrieval and comprehensive set completion. The evaluation highlights that increased interaction does not improve outcomes and that effective reasoning is more critical than search budget, with failures often stemming from difficulty in verifying constraints and managing hypothesis spaces. Top-performing models achieve low accuracy and IoU scores, indicating significant challenges in precise document retrieval and comprehensive set completion. Increased interaction does not improve outcomes, and effective reasoning is more critical than search budget. Failures often stem from difficulty in verifying constraints and managing hypothesis spaces, with agents struggling to eliminate boundary cases and integrate fragmented evidence.
The authors evaluate the performance of models on two distinct scientific search paradigms, Deep Search and Wide Search, using a standardized agent framework and a curated arXiv corpus. The results show that both paradigms present significant challenges, with models exhibiting low accuracy and IoU scores, high computational costs, and inefficiencies in reasoning and evidence collection. The evaluation highlights that performance is limited by the ability to verify complex constraints, manage hypothesis spaces, and avoid redundant or illogical search behavior, rather than by the number of interactions or reasoning steps. Models achieve low performance on both Deep Search and Wide Search tasks, with top results well below 10% in accuracy and IoU. Increased interaction turns and reasoning steps do not improve outcomes and often lead to redundant or illogical search behavior. Wide Search requires systematic management of hypothesis spaces and strict adherence to constraints, while Deep Search demands precise verification of complex multi-hop evidence chains.

The authors evaluate agentic scientific literature search using two distinct task paradigms: Deep Research and Wide Research, each with tailored metrics. Results show that current models perform poorly on both tasks, with top systems achieving less than 10% accuracy or IoU, indicating significant challenges in handling complex constraints and ensuring comprehensive retrieval. The study reveals that increased reasoning or search budget does not consistently improve outcomes, and that effective evidence utilization is more critical than trajectory length. Top-performing models achieve less than 10% accuracy in Deep Research and IoU in Wide Research, indicating substantial difficulty in solving scientific search tasks. Increased interaction turns and reasoning do not reliably improve performance, as longer trajectories often lead to redundant or illogical reasoning without better outcomes. The primary bottlenecks involve precise constraint verification and comprehensive evidence integration, with agents struggling to eliminate boundary cases and manage hypothesis spaces effectively.
The authors evaluate several large language models on academic literature search tasks using a standardized agent framework and DeepXiv search tool. Results show that performance remains low across models for both Deep Search and Wide Search, with top models achieving less than 6% accuracy and IoU. The the the table highlights that model performance varies significantly between THINK and NOTHINK modes, with some models performing better in one mode and others in the other, and that performance differences are not consistently tied to computational cost or reasoning depth. Top models achieve low accuracy and IoU scores, indicating significant challenges in academic literature search. Performance varies between THINK and NOTHINK modes, with no consistent advantage for either approach across models. There is no clear correlation between computational cost (time, turns, calls) and performance, as some models with lower resource usage outperform others with higher usage.
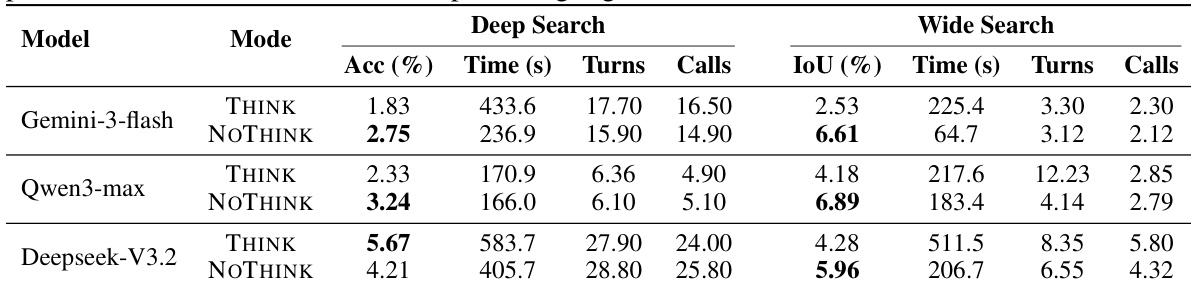
The authors analyze the impact of test-time scaling on agentic scientific search performance, using pass@k for Deep Search and best@k IoU for Wide Search. Results show that increasing the search budget improves performance in both tasks, but the gains are more substantial for Deep Search, indicating that its failures are primarily due to unstable decision paths. In contrast, Wide Search shows smaller improvements, suggesting a recall bottleneck where repeated runs tend to reproduce similar omissions rather than uncover new evidence. The trend lines indicate that the best-performing models achieve higher scores with larger budgets, with Deep Search showing a steeper improvement curve compared to Wide Search. Test-time scaling improves performance in both Deep and Wide Search, with more significant gains observed in Deep Search. The improvement in Deep Search suggests that failures are often due to unstable decision paths rather than a lack of evidence. Wide Search shows smaller gains with increased budget, indicating a recall bottleneck where repeated runs fail to uncover complementary evidence.
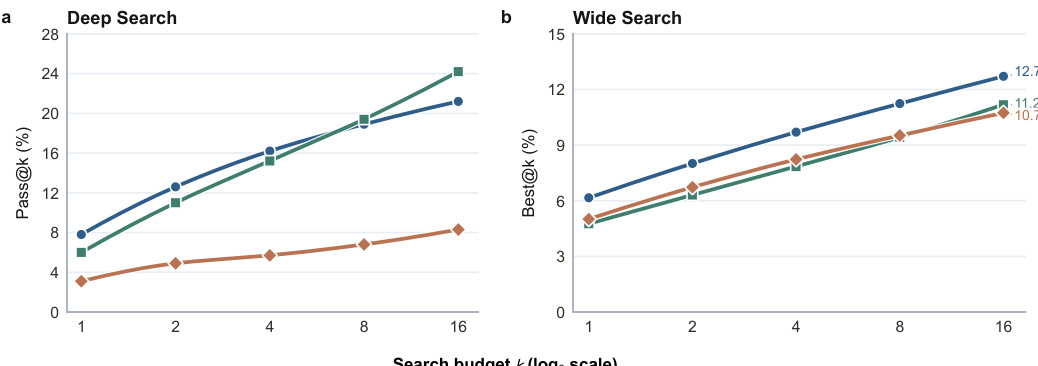
The authors evaluate multiple language models on deep and wide scientific search tasks using a standardized agent framework and a curated arXiv corpus to assess retrieval precision and evidence completeness. Baseline evaluations validate that models struggle with constraint verification and hypothesis management, as extended reasoning and interaction turns rarely improve outcomes and frequently generate redundant behavior. Scaling and reasoning-mode experiments further validate that computational budget and explicit thinking strategies provide inconsistent advantages, with success heavily dependent on task-specific bottlenecks. Ultimately, the studies conclude that stable decision paths and systematic evidence integration drive performance, while deep search is hindered by unstable trajectories and wide search by persistent recall limitations.