Command Palette
Search for a command to run...
Refinement via Regeneration: Enlarging Modification Space Boosts Image Refinement in Unified Multimodal Models
Refinement via Regeneration: Enlarging Modification Space Boosts Image Refinement in Unified Multimodal Models
Jiayi Guo Linqing Wang Jiangshan Wang Yang Yue Zeyu Liu Zhiyuan Zhao Qinglin Lu Gao Huang Chunyu Wang
Abstract
Unified multimodal models (UMMs) integrate visual understanding and generation within a single framework. For text-to-image (T2I) tasks, this unified capability allows UMMs to refine outputs after their initial generation, potentially extending the performance upper bound. Current UMM-based refinement methods primarily follow a refinement-via-editing (RvE) paradigm, where UMMs produce editing instructions to modify misaligned regions while preserving aligned content. However, editing instructions often describe prompt-image misalignment only coarsely, leading to incomplete refinement. Moreover, pixel-level preservation, though necessary for editing, unnecessarily restricts the effective modification space for refinement. To address these limitations, we propose Refinement via Regeneration (RvR), a novel framework that reformulates refinement as conditional image regeneration rather than editing. Instead of relying on editing instructions and enforcing strict content preservation, RvR regenerates images conditioned on the target prompt and the semantic tokens of the initial image, enabling more complete semantic alignment with a larger modification space. Extensive experiments demonstrate the effectiveness of RvR, improving Geneval from 0.78 to 0.91, DPGBench from 84.02 to 87.21, and UniGenBench++ from 61.53 to 77.41.
One-sentence Summary
The authors propose Refinement via Regeneration (RvR), a framework for unified multimodal models that reformulates refinement as conditional regeneration guided by the target prompt and initial image semantic tokens, thereby replacing coarse editing instructions and strict pixel preservation to expand the modification space and improve Geneval, DPGBench, and UniGenBench++ scores from 0.78 to 0.91, 84.02 to 87.21, and 61.53 to 77.41, respectively.
Key Contributions
- Introduces Refinement via Regeneration (RvR), a framework that reformulates text-to-image refinement as conditional image regeneration instead of relying on the coarse editing instructions characteristic of existing refinement-via-editing paradigms.
- Conditions generation on the target prompt alongside semantic tokens from the initial image while discarding strict pixel-level preservation constraints, thereby expanding the modification space for more complete semantic alignment.
- Demonstrates substantial performance gains across multiple benchmarks, improving Geneval from 0.78 to 0.91, DPGBench from 84.02 to 87.21, and UniGenBench++ from 61.53 to 77.41.
Introduction
Unified multimodal models merge visual understanding with image generation, enabling text-to-image systems to refine outputs by analyzing prompt-image mismatches. This capability is vital for enhancing alignment in complex scenarios, yet existing refinement strategies predominantly rely on a refinement-via-editing paradigm that generates instructions to modify specific regions while enforcing strict pixel-level preservation. This approach suffers from inherent limitations, as editing instructions often provide only coarse descriptions of semantic gaps, leading to incomplete corrections, and rigid content preservation unnecessarily restricts the modification space, hindering necessary structural adjustments. The authors introduce Refinement via Regeneration (RvR), a framework that reformulates refinement as conditional image regeneration rather than editing. By conditioning generation on the target prompt and semantic tokens of the initial image, RvR eliminates editing instructions and pixel-level consistency constraints, thereby expanding the effective modification space for more complete semantic alignment. The method employs a training scheme based on independently generated samples and semantic ViT representations to prioritize semantic correction over appearance preservation, achieving significant gains across multiple benchmarks.
Dataset
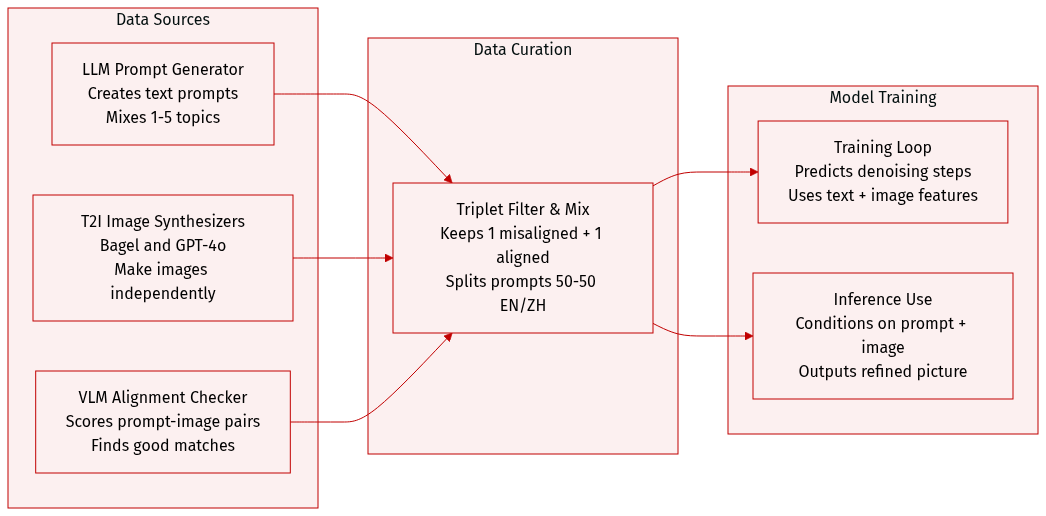
-
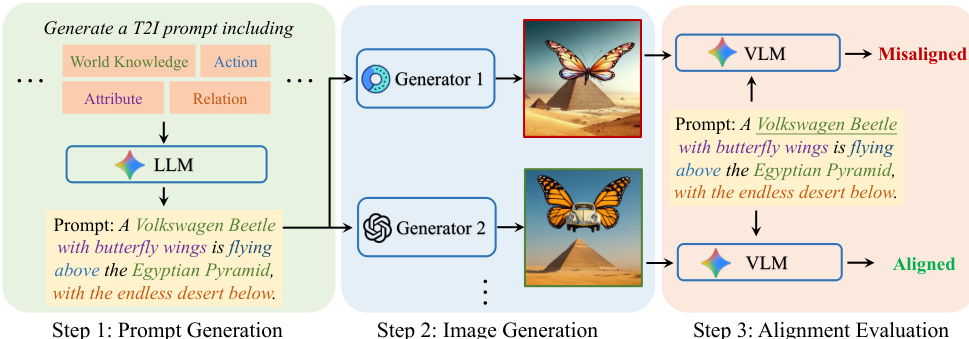
Dataset composition and sources: The authors build a unified training set of triplets ⟨I,I′,T⟩ pairing a textual prompt (T) with a misaligned image (I) and a prompt-aligned image (I'). Prompts are generated by large language models, images are synthesized by multiple text-to-image generators such as Bagel and GPT-4o, and alignment quality is validated using vision-language models.
-
Key details for each subset: The dataset is structured around a single curated collection rather than separate subsets, with the primary split being a 1:1 mixture of English and Chinese prompts to support bilingual refinement. Each triplet is filtered through a three-step pipeline: prompts are formed by randomly combining one to five semantic dimensions, candidate images are produced independently per prompt, and a vision-language model retains only one misaligned and one aligned image per prompt based on semantic alignment scores.
-
How the paper uses the data: The filtered triplets train a unified multimodal model to predict denoising velocities. During training, the model ingests text tokens, visual features extracted from the misaligned image, and noisy latent representations of the aligned image. At inference, the system conditions on a prompt and a misaligned image to directly denoise noise into a refined, prompt-faithful output.
-
Processing and metadata construction: The pipeline deliberately removes content consistency and pixel-level editing constraints between input and output images, encouraging the model to learn semantic transformation rather than conservative updates. Metadata is organized around prompt dimension tags and VLM alignment evaluations, while the independent generation strategy expands the learning space by forcing the model to correct misalignments from scratch.
Method
The authors leverage a unified multimodal model (UMM) architecture that integrates image understanding, generation, and editing within a single framework. This UMM employs a semantic visual encoder, typically a Vision Transformer (ViT), to extract high-level semantic features ZViT from an input image, and a variational autoencoder (VAE) to map the image into low-level latent tokens ZVAE. These representations are processed by a multi-modal backbone M to support diverse tasks. For image understanding, the model generates a textual response T^ given an image I and a text query T. For text-to-image generation, it synthesizes an image I^ from a text prompt Tprompt. For image editing, it produces an edited image I^′ by modifying I according to an editing instruction Tedit, using both ZViT and ZVAE as conditioning inputs.
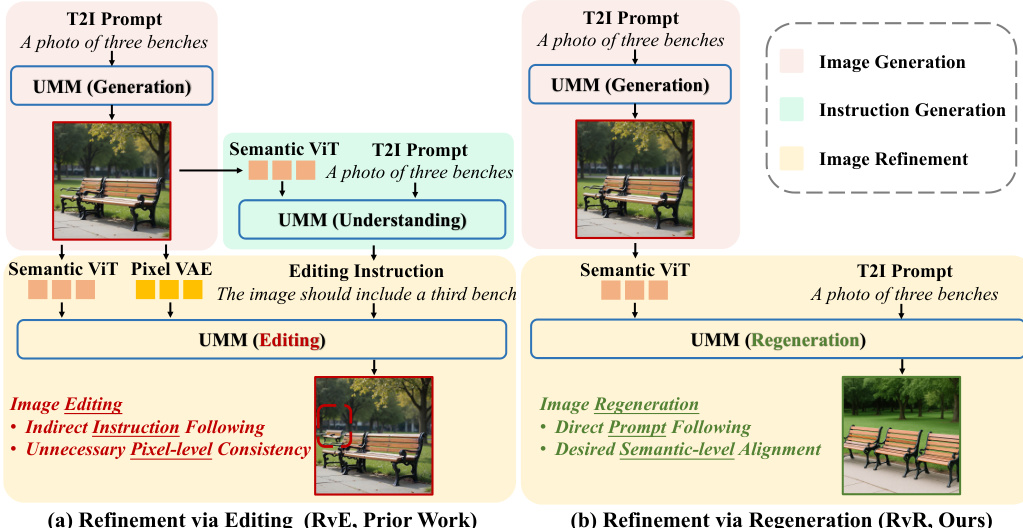
As shown in the figure below, the existing refinement-via-editing (RvE) paradigm operates in two stages: first, generating an editing instruction T^edit by comparing the input image with the target prompt, and second, using this instruction to edit the original image. This approach inherits constraints from image editing, such as the requirement for pixel-level consistency and content preservation, which are unnecessary for refinement. The reliance on an intermediate instruction introduces potential error accumulation, and the modification space is limited to conservative, localized changes.
To address these limitations, the authors propose Refinement via Regeneration (RvR), which reformulates refinement as a conditional image regeneration problem. This approach eliminates the need for an intermediate editing instruction and removes the constraint of maintaining pixel-level consistency with the source image. Instead, RvR directly conditions on the target prompt and the semantic tokens of the initial image. The training pipeline involves a system prompt Tsystem that instructs the model to analyze misalignment and re-generate the image to align with the user's prompt. The model is trained to predict the velocity field for rectified flow, conditioned on the system prompt, the target prompt Tprompt, and the semantic ViT tokens ZViT of the misaligned image. Notably, the VAE tokens ZVAE are excluded from the conditioning context during training, allowing for larger, more flexible modifications.
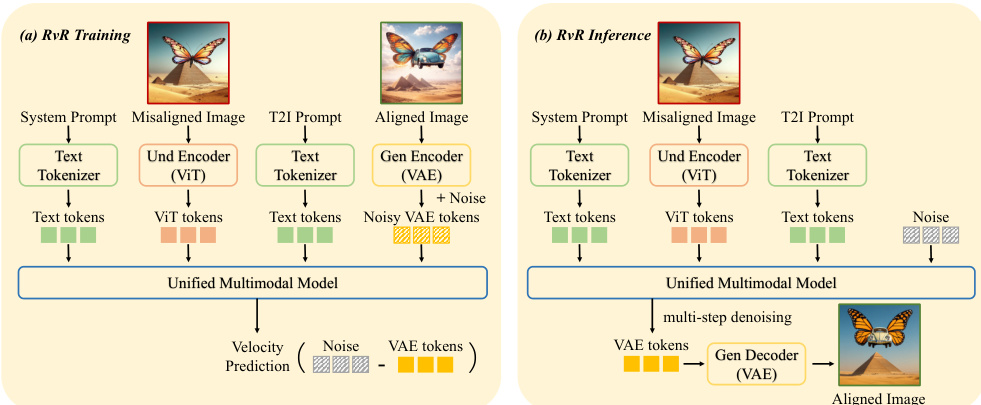
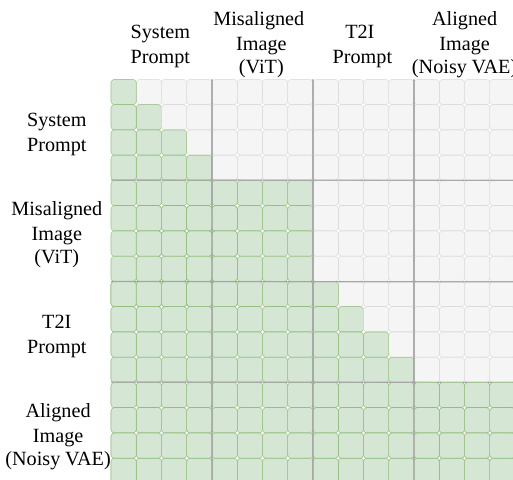
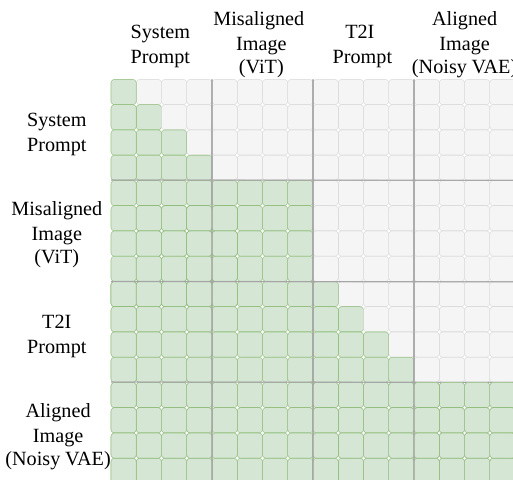
During inference, given a prompt Tprompt and a misaligned image I, the model regenerates an improved image I^′ conditioned on the semantic tokens ZViT extracted from I. This direct prompt following bypasses the error-prone instruction generation step and removes the unnecessary content-preservation constraints, enabling more effective refinement. The attention mechanism in RvR uses causal attention for text tokens (system prompt and T2I prompt) and full attention for image tokens (ViT and VAE), as illustrated in the attention mask.
Experiment
Evaluated against representative regeneration- and editing-based baselines across standard text-to-image benchmarks, the RvR pipeline is designed to validate its capacity for precise semantic correction. Qualitative and iterative assessments confirm that the model consistently outperforms existing methods by leveraging an enlarged modification space that prioritizes semantic alignment over strict pixel preservation, allowing it to successfully resolve complex misalignments across multiple refinement rounds without degrading already accurate content. Additionally, robustness tests and ablation studies demonstrate that RvR effectively reuses compatible elements from initial images while discarding conflicting ones, with results confirming that these gains stem directly from the regeneration-based training strategy rather than pixel-level constraints or standard fine-tuning.
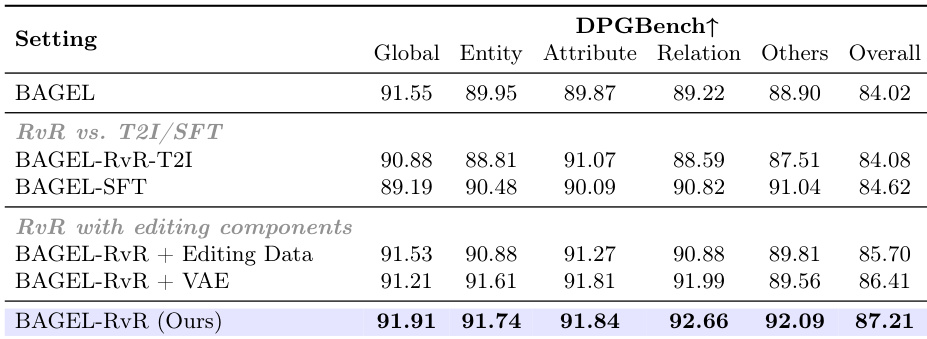
The authors compare their RvR model with various baselines and ablation variants on the DPGBench benchmark, focusing on refinement performance. Results show that the proposed RvR method achieves the highest overall score, outperforming both T2I and refinement-based approaches, with improvements particularly evident in entity and attribute-level alignment. The ablation studies indicate that incorporating editing data or VAE features degrades performance, highlighting the importance of the regeneration-based refinement mechanism. RvR achieves the best overall performance on DPGBench, surpassing both T2I and refinement-based methods. The model shows significant improvements in entity and attribute alignment compared to baselines. Incorporating editing data or VAE features reduces performance, indicating that strict pixel-level consistency constraints are detrimental to semantic refinement.
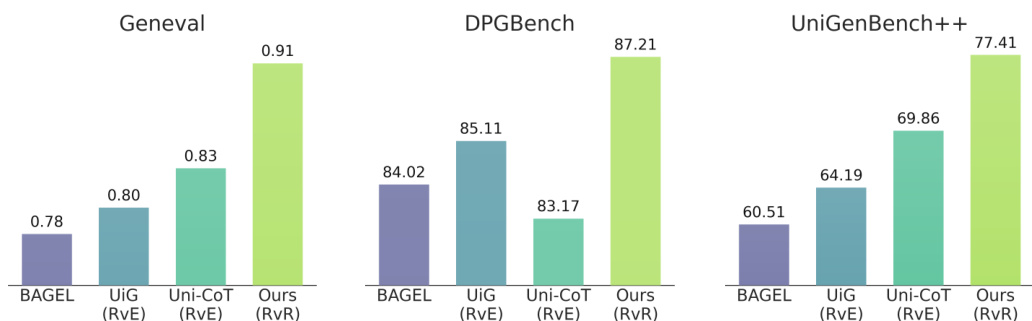
The authors evaluate their RvR method on three benchmarks, demonstrating consistent performance improvements over baseline models and existing refinement methods. The results show that RvR outperforms both generation-only models and editing-based approaches, particularly in handling complex semantic prompts, and maintains strong performance across different evaluation metrics. The method also supports iterative refinement and effectively leverages compatible semantics from initial images while discarding conflicting ones. RvR consistently outperforms baseline models and existing refinement methods across all three benchmarks. RvR achieves better results than editing-based methods by allowing greater modification space through regeneration rather than pixel-level preservation. RvR supports iterative refinement, further correcting misalignments in subsequent rounds while preserving correctly aligned semantics.
The authors evaluate their RvR model on image refinement tasks, comparing it against various baseline models including generation-only, unified multimodal, and refinement-based methods. Results show that RvR consistently outperforms other approaches across multiple benchmarks, demonstrating superior performance in correcting semantic misalignments and maintaining alignment with complex prompts. The model also exhibits robustness in reusing compatible semantics from initial images while discarding conflicting ones, and supports iterative refinement without degrading previously correct results. RvR achieves consistent leading performance across multiple benchmarks compared to both generation-only and refinement-based models. RvR outperforms editing-based methods by enabling a larger modification space through regeneration rather than pixel-level preservation. RvR supports multi-round refinement, further correcting misaligned semantics while preserving correct results from previous rounds.
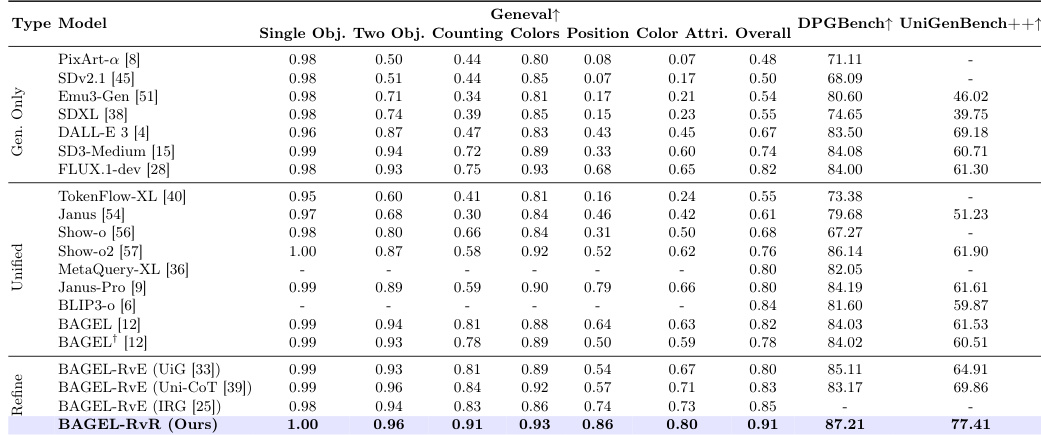
The authors present an image refinement method called RvR that outperforms existing generation-only and editing-based approaches across multiple benchmarks. The method leverages a regeneration-based approach to correct semantic misalignments, demonstrating robustness in reusing compatible initial image semantics and discarding conflicting ones, while also supporting iterative refinement to further improve results. RvR achieves superior performance by expanding the modification space beyond pixel-level constraints, enabling more effective semantic correction. RvR outperforms generation-only and editing-based methods on multiple benchmarks by enabling broader semantic corrections. The method supports iterative refinement, improving misaligned semantics further and preserving correct results in subsequent rounds. RvR demonstrates robustness by reusing compatible initial image semantics and discarding conflicting ones during regeneration.
The authors evaluate their regeneration-based RvR model across multiple image refinement benchmarks, comparing it against generation-only, editing-based, and existing refinement methods alongside ablation studies. These experiments validate that replacing strict pixel-level editing with a regeneration mechanism significantly enhances semantic alignment, particularly for entity and attribute consistency in complex prompts. Qualitative results demonstrate that the approach robustly preserves compatible semantics from initial images while discarding conflicting details, and effectively supports iterative refinement to progressively correct misalignments without degrading prior results. Overall, the study concludes that regeneration-based refinement provides a superior modification space, consistently outperforming conventional baselines in semantic correction tasks.