Command Palette
Search for a command to run...
DV-World: Benchmarking Data Visualization Agents in Real-World Scenarios
DV-World: Benchmarking Data Visualization Agents in Real-World Scenarios
Abstract
Real-world data visualization (DV) requires native environmental grounding, cross-platform evolution, and proactive intent alignment. Yet, existing benchmarks often suffer from code-sandbox confinement, single-language creation-only tasks, and assumption of perfect intent. To bridge these gaps, we introduce DV-World, a benchmark of 260 tasks designed to evaluate DV agents across real-world professional lifecycles. DV-World spans three domains: DV-Sheet for native spreadsheet manipulation including chart and dashboard creation as well as diagnostic repair; DV-Evolution for adapting and restructuring reference visual artifacts to fit new data across diverse programming paradigms and DV-Interact for proactive intent alignment with a user simulator that mimics real-world ambiguous requirements. Our hybrid evaluation framework integrates Table-value Alignment for numerical precision and MLLM-as-a-Judge with rubrics for semantic-visual assessment. Experiments reveal that state-of-the-art models achieve less than 50% overall performance, exposing critical deficits in handling the complex challenges of real-world data visualization. DV-World provides a realistic testbed to steer development toward the versatile expertise required in enterprise workflows. Our data and code are available at https://github.com/DA-Open/DV-World{this project page}.
One-sentence Summary
The authors introduce DV-World, a benchmark of 260 tasks that evaluates data visualization agents across spreadsheet manipulation, cross-platform adaptation, and proactive intent alignment through a hybrid evaluation framework integrating Table-value Alignment for numerical precision and MLLM-as-a-Judge with rubrics for semantic-visual assessment.
Key Contributions
- DV-World introduces a benchmark of 260 tasks evaluating data visualization agents across native spreadsheet manipulation (DV-Sheet), cross-paradigm code evolution (DV-Evolution), and proactive user interaction (DV-Interact). The benchmark tests iterative updates, diagnostic repair, and ambiguous intent handling to reflect real-world professional lifecycles beyond static reproduction.
- A hybrid evaluation framework pairs a Table-value Alignment protocol for numerical precision with a hierarchical MLLM-as-a-Judge system guided by expert-annotated rubrics. This methodology assesses data fidelity and visual semantics while transcending conventional code verification.
- Experimental results establish performance baselines across state-of-the-art models, revealing that current agents achieve less than 50% overall accuracy. These findings expose critical deficits in managing native object models, migrating visualization logic, and aligning with iterative user feedback.
Introduction
Data visualization agents powered by large language models are transforming how abstract datasets translate into actionable decisions, yet their practical deployment requires seamless integration with real software ecosystems and dynamic user workflows. Prior evaluation benchmarks remain constrained by idealized, code-only sandboxes that ignore native spreadsheet constraints, focus exclusively on one-shot chart generation, and assume perfectly specified prompts without accounting for real-world ambiguity. The authors introduce DV-World, a comprehensive benchmark that assesses visualization agents across native spreadsheet manipulation, iterative cross-framework logic evolution, and proactive dialogue-based clarification. They pair this testbed with a hybrid evaluation framework combining precise data alignment protocols and expert-guided multimodal judging to expose critical performance gaps and steer agent development toward robust, lifecycle-aware visualization systems.
Dataset
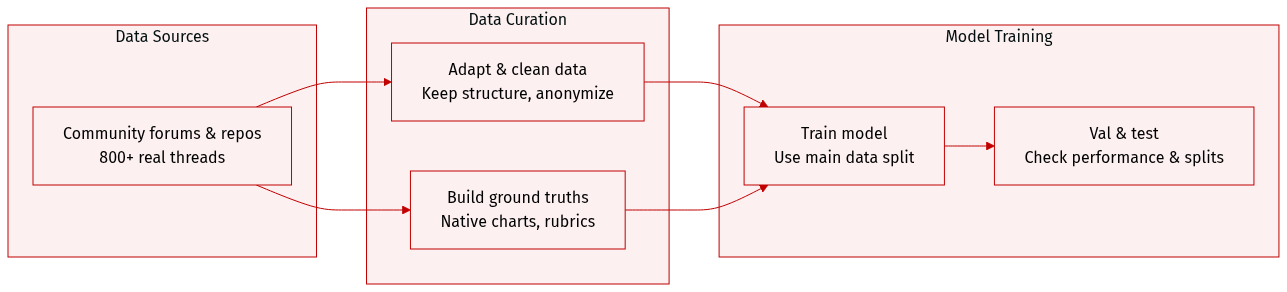
Dataset Composition and Sources The authors introduce DV-World, a benchmark comprising 260 tasks designed to evaluate data visualization agents across real-world professional lifecycles. The dataset is curated from over 800 problem threads sourced from communities including ExcelForum, Kaggle, Chandoo.org, Excelguru, and MrExcel. This collection prioritizes authentic scenarios by gathering spreadsheets, tables, plotting code, and reference visualizations that capture natural user language, troubleshooting behaviors, and diverse analytical workflows.
Subset Details
- DV-Sheet (160 tasks): Focuses on native spreadsheet grounding with workbooks averaging 36.53 columns and 11,583 rows.
- DVSheet-Crea (80 tasks): Evaluates chart and dashboard creation. Tasks are stratified by complexity into Direct Visualization, Extraction-Required, and Multi-Sheet Reasoning.
- DVSheet-Fix (50 tasks): Assesses diagnostic repair. The authors use a controlled inverse injection strategy where experts introduce errors such as data binding failures, axis scaling issues, and type mismatches into verified healthy workbooks. This subset contains 74.5% noisy data.
- DVSheet-Dash (30 tasks): Tests dashboard construction using hybrid reference files. Instructions follow three user archetypes: Executive Directives, Technical Specifications, and Ad-hoc Queries.
- DV-Evolution (80 tasks): Measures visual refinement across five frameworks including Python, ECharts, Vega-Lite, D3.js, and Plotly.js. Tasks involve adapting atomic subplots using adversarial data perturbations like schema-preserving shifts and schema mutations.
- DV-Interact (80 tasks): Evaluates proactive intent alignment through multi-turn dialogue. The authors inject metric, temporal, and aggregation ambiguities into base queries. A user simulator powered by nine LLMs provides feedback, categorized as Mentors, Standard Users, or Hard Clients.
Data Usage and Processing The authors utilize DV-World strictly as an evaluation benchmark. They employ a hybrid evaluation framework integrating Table-value Alignment for numerical precision and MLLM-as-a-Judge with multidimensional rubrics for semantic and visual assessment.
- Adaptation Protocol: All data undergoes a three-step processing pipeline: structure retention to preserve merged cells and irregular layouts, value perturbation to renormalize numbers while maintaining statistical distributions, and metadata anonymization to replace identifiable entities.
- Ground Truth Construction: For DV-Sheet, the authors generate ground truths using Python scripts via openpyxl to produce native Excel chart objects with explicit data bindings, ensuring auditable provenance. Reverse engineering is applied to recover healthy files for the Fix tasks.
- DV-Evolution Processing: The authors enforce a No-Hardcode policy where solutions must dynamically derive visual elements from input data. They also perform atomic subplot isolation to decompose complex composite figures into focused editing units.
- DV-Interact Processing: Interaction trajectories are constructed by recording question-answer patterns and correction strategies. The authors define hidden true intents and reaction rules to govern simulator responses, ensuring alignment with optimal code solutions.
- Metadata: Construction includes gold tables for numerical verification, gold plots for visual references, and task-specific rubrics with binary criteria covering fidelity, logic, aesthetics, and professionalism.
Method
The framework addresses three core visualization challenges: native spreadsheet charting, visualization evolution, and interactive visualization. The overall architecture integrates specialized agents and evaluation protocols tailored to each task domain. For DV-Sheet, which focuses on native spreadsheet charting, the system supports three subtasks: DVSheet-Crea, where agents generate a new chart with dynamic range bindings; DVSheet-Fix, which involves diagnosing and repairing defective charts; and DVSheet-Dash, where agents compose professional dashboards by arranging multiple charts and tables. Agents operate within a sandboxed environment using spreadsheet manipulation libraries such as openpyxl and xlwings, ensuring all outputs are native Excel chart objects. The process involves iterative observation, proposal, revision, and action, with agents leveraging tool calls to modify workbook states directly. The framework enforces strict constraints to prevent the use of external plotting libraries and mandates that all charts are created as editable, interactive objects within the spreadsheet.

For DV-Evol, the task involves evolving visual assets into executable code through logic synthesis, modeled as a transformation from a reference image, a new dataset, and modification requirements into functional plotting code and the corresponding data table. This process is supported by a logic synthesis pipeline that reverse-engineers the visual semantics of the reference image and produces output in target languages such as Python, Vega-Lite, or D3.js. The evaluation assesses three dimensions: integrity, which ensures correct data migration and functional code; consistency, which measures the preservation of design semantics and visual structure; and aesthetics, which evaluates professional quality and readability of the output. The framework supports multiple visualization frameworks and enforces a deterministic sequence of ingestion, normalization, rendering, and serialization, using the Object-Oriented API of matplotlib for fine-grained control.
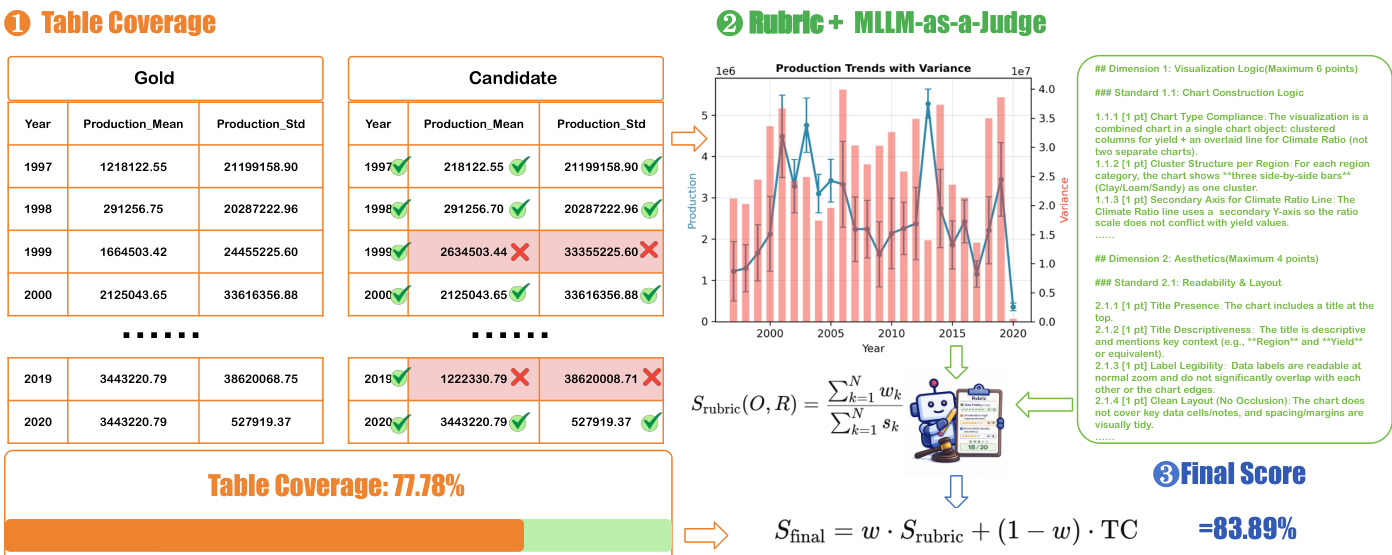
DV-Inter focuses on multi-turn interactive visualization, where agents generate visualization code from ambiguous natural-language queries. This task evaluates interaction competence, requiring agents to identify missing information, ask minimal yet informative questions, and iteratively refine specifications. The framework employs a dual-stage user simulator to ensure authentic reasoning and prevent information leakage. The simulator consists of a gatekeeper module that filters inappropriate requests, such as those for implementation code or internal schema details, and a generator that provides grounded, non-technical responses based on the user's latent intent. The interaction success rate is calculated using metrics that account for clarification requests, rejections, and successful turns, encouraging proactive and efficient dialogue. The evaluation assesses three dimensions: interaction, accuracy, and aesthetics, with scoring based on structured rubrics that decompose the task into requirements and sub-standards.
Experiment
The evaluation employs a hybrid framework combining expert-curated qualitative rubrics with quantitative data fidelity checks to assess state-of-the-art language models across three distinct visualization domains. DV-Sheet validation reveals persistent deficiencies in precise data grounding and error correction, as agents frequently generate structurally plausible charts that lack numerical accuracy or professional layout standards. DV-Evol testing highlights substantial bottlenecks in cross-framework adaptation, where increasing code complexity consistently degrades semantic transfer and layout consistency. Finally, DV-Inter experiments expose fundamental weaknesses in proactive reasoning and multi-turn alignment, demonstrating that models struggle to resolve ambiguous user intent without making unverified assumptions or experiencing cognitive-execution gaps, which collectively underscores the need for stronger data validation and iterative inquiry capabilities.
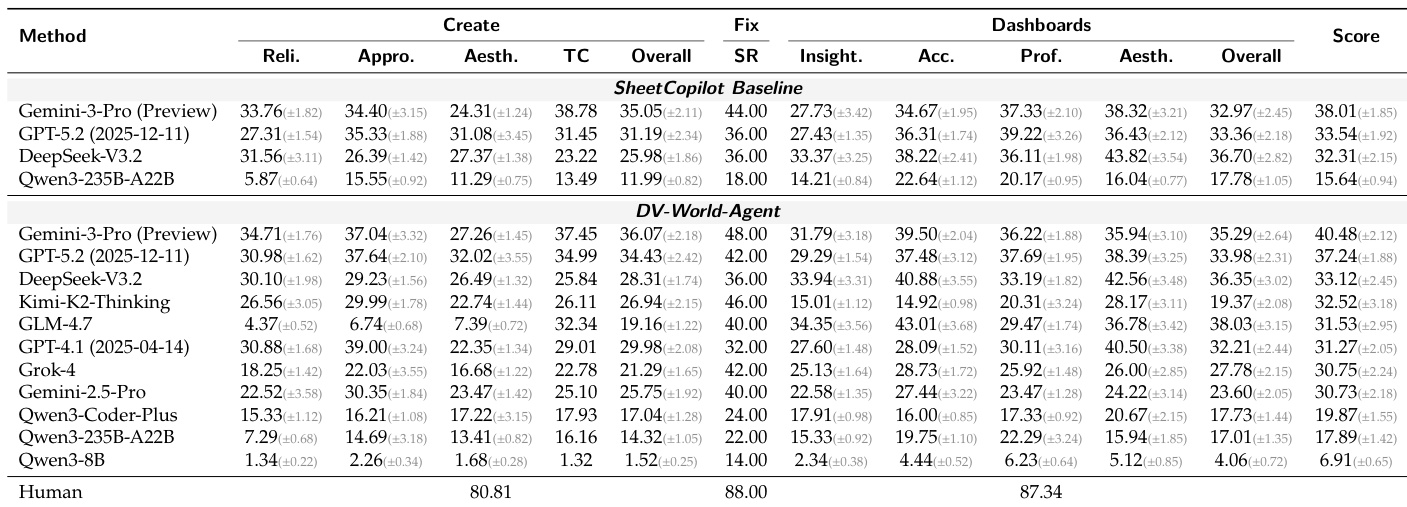
The experiment evaluates various models on data visualization tasks across creation, fixing, and dashboard generation, with results showing that even top-performing models struggle to match human-level performance. The benchmark highlights persistent challenges in data accuracy, visual fidelity, and task execution, particularly in complex scenarios requiring multi-step reasoning and interactive alignment. Performance varies significantly by task type, with the most advanced models achieving the highest scores in specific areas but still falling short of human baselines. Top models achieve high scores in specific tasks but consistently underperform compared to human benchmarks. Data accuracy and visual fidelity remain major challenges across all tasks and model types. Interactive and complex dashboard tasks show the most significant performance gaps, indicating difficulties in multi-step reasoning and professional design.
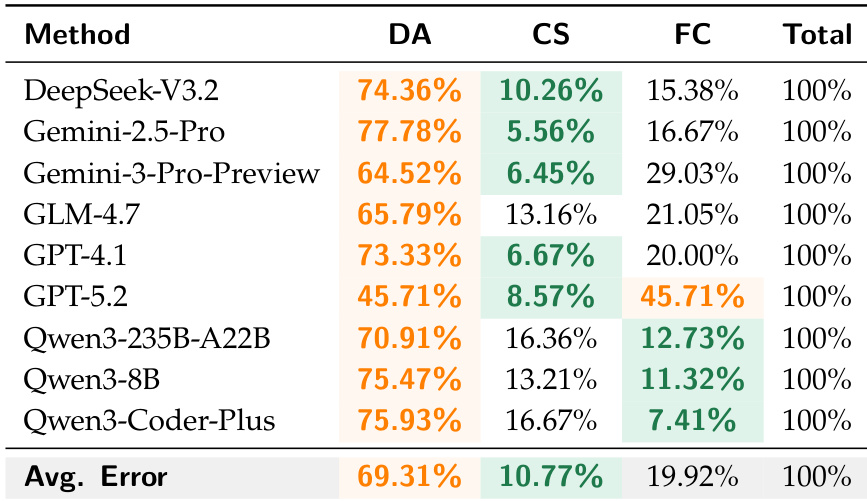
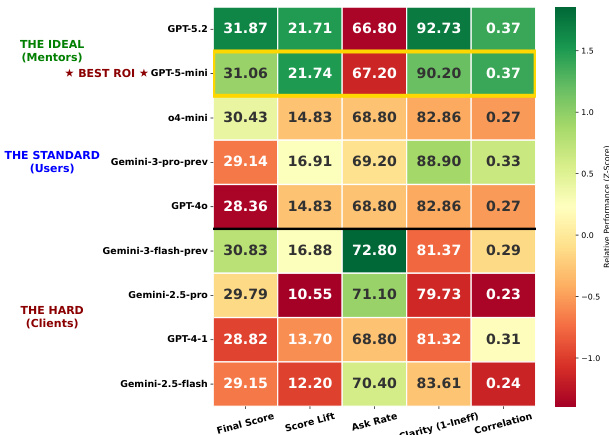
The the the table presents a comparison of different methods across three evaluation metrics: DA, CS, and FC, with a total score of 100% for each method. The results highlight variations in performance across the metrics, with some methods showing higher scores in DA and others in CS or FC. The average error rates across all methods are also provided, indicating the overall performance level. Methods show varying performance across DA, CS, and FC metrics, with no single method excelling in all areas. The average error rates across all methods are 69.31% for DA, 10.77% for CS, and 19.92% for FC. GPT-5.2 achieves the highest score in FC at 45.71%, while DeepSeek-V3.2 has the highest score in DA at 74.36%.
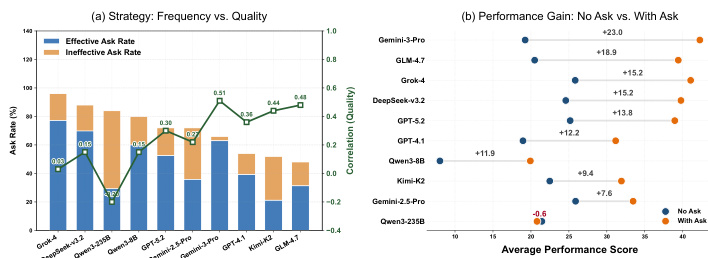
The authors analyze the impact of interactive strategies on agent performance, focusing on how proactive clarification affects task quality and overall scores. Results show that models with higher effective clarification rates achieve better performance, while those relying on ineffective or frequent interactions without improvement show diminishing returns. The relationship between interaction frequency and quality varies significantly across models, with some benefiting from targeted questions and others suffering from noise due to poor query quality. Effective clarification significantly improves task quality, with models showing higher success rates when they ask relevant questions. Frequent interactions do not guarantee better performance; some models experience performance loss due to ineffective or redundant queries. The correlation between interaction quality and final score varies, indicating that the strategic use of clarification is more important than the number of interactions.
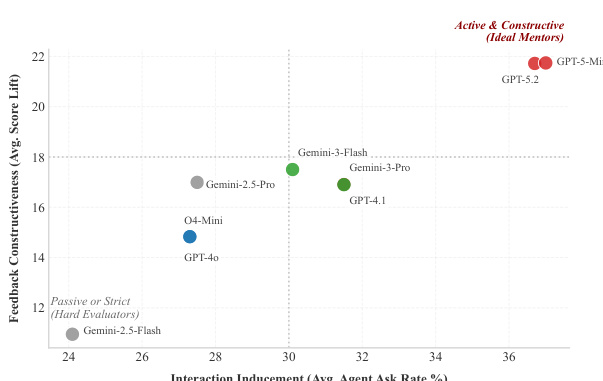
The chart illustrates the relationship between interaction inducement and feedback constructiveness for various models, showing that models with higher agent ask rates tend to achieve greater score lifts. GPT-5.2 and Gemini-3-Flash are positioned in the top-right quadrant, indicating high interaction and high feedback constructiveness, while Gemini-2.5-Flash and GPT-4.0 are in the lower-left quadrant, reflecting lower interaction and feedback metrics. Models with higher interaction rates generally achieve greater score lifts. GPT-5.2 and Gemini-3-Flash show high interaction and feedback constructiveness. Gemini-2.5-Flash and GPT-4.0 exhibit low interaction and feedback metrics.
The experiment evaluates data visualization agents across multiple tasks, including spreadsheet-based chart creation, evolution, and interactive refinement. Results show that even top-performing models struggle with error correction, faithful data binding, and consistent visualization evolution, with performance gaps observed between models and human benchmarks. The evaluation framework combines rubric-based judgments with quantitative metrics to assess visual quality and data fidelity. Top models achieve high scores in visual quality and data fidelity but still fall short of human benchmarks. Performance varies significantly across tasks, with chart evolution and interactive alignment posing major challenges. The evaluation framework demonstrates robustness, with stable model rankings under different parameter settings.
The evaluation assesses various AI models on data visualization tasks spanning creation, error correction, and interactive dashboard generation using a combined rubric and quantitative framework. The primary experiment validates that top models consistently underperform human benchmarks in complex scenarios, highlighting persistent difficulties in data accuracy and visual fidelity. A secondary analysis of agent interactions confirms that proactive clarification substantially improves task quality, demonstrating that targeted questioning outperforms high-frequency but ineffective communication. Collectively, the results indicate that advancing automated visualization requires prioritizing strategic feedback mechanisms and multi-step reasoning over raw interaction volume.