Command Palette
Search for a command to run...
Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
Bin Wu Mengqi Huang Shaojin Wu Weinan Jia Yuxin Wang Zhendong Mao Yongdong Zhang
Abstract
Distillation-based acceleration has become foundational for making autoregressive streaming video diffusion models practical, with distribution matching distillation (DMD) as the de facto choice. Existing methods, however, train the student to match the teacher's output indiscriminately, treating every rollout, frame, and pixel as equally reliable supervision. We argue that this caps distilled quality, since it overlooks two complementary axes of variance in DMD supervision: Inter-Reliability across student rollouts whose supervision varies in reliability, and Intra-Perplexity across spatial regions and temporal frames that contribute unequally to where quality can still be improved. The objective thus conflates two questions under a uniform weight: whether to learn from each rollout, and where to concentrate optimization within it. To address this, we propose Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework that adaptively reweights the distillation objective at both rollout and spatiotemporal-element levels through a single shared reward-guided mechanism. At the Inter-Reliability level, Stream-R1 rescales each rollout's loss by an exponential of a pretrained video reward score, so that rollouts with reliable supervision dominate optimization. At the Intra-Perplexity level, it back-propagates the same reward model to extract per-pixel gradient saliency, which is factored into spatial and temporal weights that concentrate optimization pressure on regions and frames where refinement yields the largest expected gain. An adaptive balancing mechanism prevents any single quality axis from dominating across visual quality, motion quality, and text alignment. Stream-R1 attains consistent improvements on all three dimensions over distillation baselines on standard streaming video generation benchmarks, without architectural modification or additional inference cost.
One-sentence Summary
The authors propose Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework for autoregressive streaming video diffusion models that employs a single shared reward-guided mechanism to adaptively reweight the distillation objective at both rollout and spatiotemporal-element levels, addressing inter-reliability and intra-perplexity variances overlooked by existing indiscriminative distribution matching distillation methods.
Key Contributions
- The paper introduces Stream-R1, a Reliability-Perplexity Aware Reward Distillation framework that brings reward signals directly into the distribution matching distillation objective. This method adaptively reweights the distillation objective through a single shared reward-guided mechanism to address indiscriminative supervision.
- The approach applies an Inter-Reliability scalar weight to modulate each rollout's contribution to the loss and an Intra-Perplexity per-element weight to concentrate optimization on regions with the largest expected gain. This design addresses the conflation of deciding whether to learn from each rollout and where to concentrate optimization within each rollout.
- Results demonstrate consistent improvements on all three quality dimensions over DMD-based baselines on standard streaming video generation benchmarks. These gains are achieved without any architectural modification to the student model and at no additional inference cost.
Introduction
Autoregressive streaming video diffusion models enable unbounded generation but require distillation to mitigate prohibitive inference costs. Current Distribution Matching Distillation methods apply uniform supervision across all rollouts and pixels, overlooking variance in supervision reliability and refinement potential. The authors propose Stream-R1, a framework that leverages a pretrained reward model to adaptively reweight the distillation objective at both the rollout and spatiotemporal levels. This approach addresses Inter-Reliability by scaling loss based on reward scores and Intra-Perplexity by using gradient saliency to concentrate optimization on regions needing refinement. Stream-R1 achieves consistent quality improvements across visual, motion, and text dimensions without architectural modifications or additional inference overhead.
Method
The authors propose Stream-R1, a dynamic spatiotemporal reward-guided distillation framework designed to enhance video generation quality. As illustrated in the framework diagram, the overall training pipeline integrates a student generator with a specialized reward modulation module. The process initiates with a text prompt fed into the student generator Gθ, which produces a video rollout. This rollout is perturbed by adding noise and subsequently evaluated by two critic networks, ffake and fReal, alongside the Stream R1 module. The core innovation involves modulating the distillation signal through a balanced multi-dimensional penalty and weighting the loss using an Inter-Reliability weight Winter and an intra-instance weight Wintra.
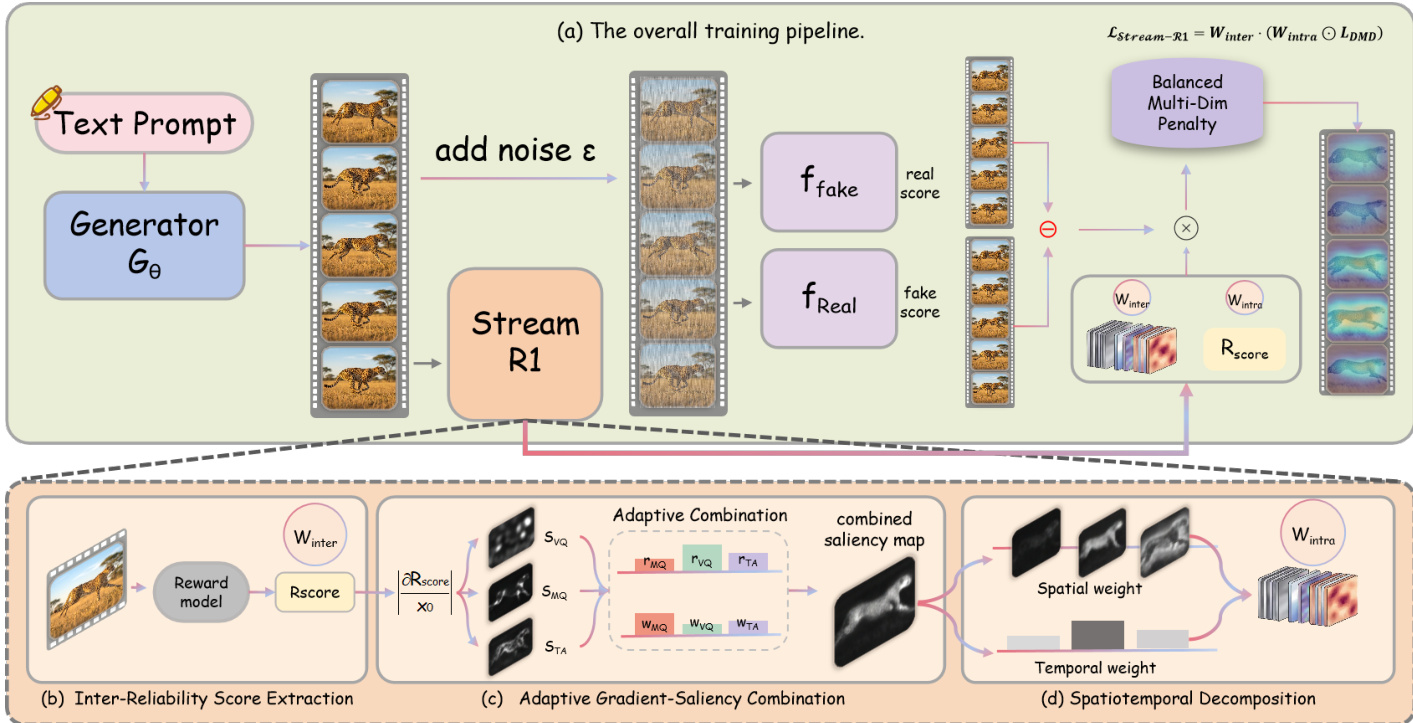
To address the variance in supervision reliability across different generated rollouts, the framework employs Inter-Reliability Weighting. In standard Distribution Matching Distillation, gradients are averaged equally across all rollouts, yet the reliability of these gradients varies significantly depending on the rollout's proximity to the high-quality mode. The authors assign a per-sample loss multiplier that increases with the overall reward score. This ensures that rollouts where the supervision is reliable contribute more strongly to the gradient signal. As shown in the figure below, the method transitions from uniform optimization intensity to stronger optimization intensity in high-reliability regions, effectively filtering out noisy supervision. Additionally, region-wise heat maps highlight the specific areas targeted for refinement based on student rollout perplexity.
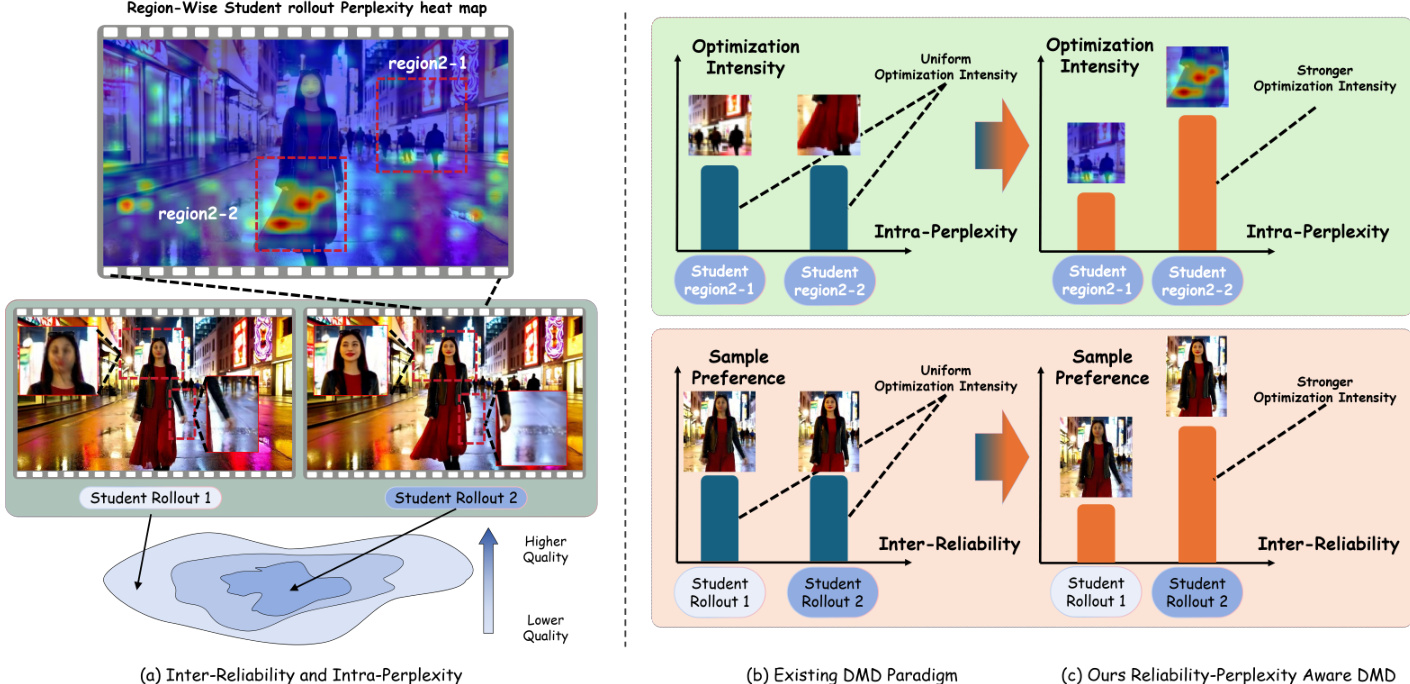
Within individual rollouts, the authors also address Intra-Perplexity variance, as different spatial regions and temporal frames contribute unequally to the potential for quality improvement. To localize optimization pressure, the method derives a per-element weight using adaptive gradient-saliency combination. The reward model is back-propagated to compute saliency maps for different quality dimensions, such as visual quality and temporal consistency. These maps are adaptively combined to form a unified guide that prioritizes regions with larger room for improvement.
Finally, the combined saliency volume undergoes spatiotemporal decomposition. This step disentangles the spatial structure from the temporal structure by separately normalizing the components before composing them into the final weight map Wintra. This ensures that every frame retains meaningful internal contrast while allowing the temporal weights to modulate the contribution of entire frames. To ensure balanced improvement across multiple quality dimensions, a balance penalty is introduced. This penalty discourages the optimizer from focusing disproportionately on dimensions that yield easy gains. The final objective combines these weights with the base distillation loss to produce high-quality, temporally stable videos.
Experiment
Stream-R1 is evaluated against leading baselines across short and long video benchmarks using automated metrics, VLM scoring, and human preference studies. The results show that spatiotemporal reward localization enables the distilled model to surpass its multi-step diffusion teacher and existing reward-guided methods in total quality and semantic alignment. Furthermore, ablation studies and visualizations validate that targeting localized quality deficiencies effectively mitigates temporal drift, ensuring stable backgrounds and coherent motion in extended video generation.
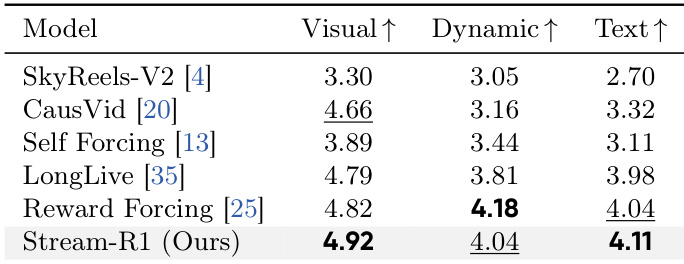
The authors utilize a vision-language model to evaluate long video generation quality across visual fidelity, motion dynamics, and text alignment. Results indicate that the proposed Stream-R1 method outperforms existing baselines in visual quality and text alignment metrics. Although it trails slightly in dynamic scores compared to the Reward Forcing baseline, it demonstrates a superior balanced profile across all three dimensions. Stream-R1 achieves the highest visual quality score among all compared methods. The method secures the top ranking for text alignment, surpassing the previous best model. Performance remains competitive across all axes, highlighting a balanced optimization of video attributes.
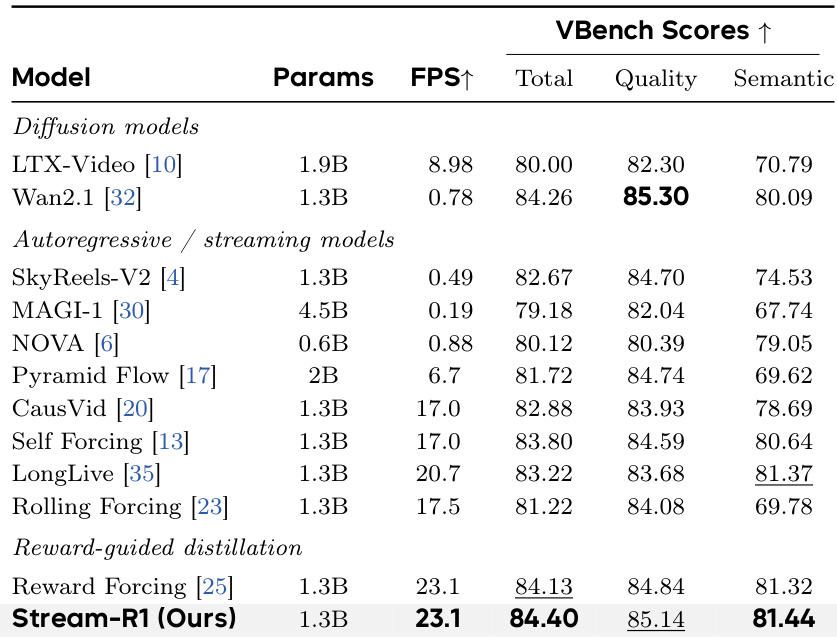
The authors benchmark Stream-R1 against representative open-source video generation models, demonstrating that it achieves the highest total performance score among all compared methods. The model notably surpasses its multi-step diffusion teacher in total and semantic quality while operating at a significantly higher inference speed. Additionally, it achieves the top quality score among autoregressive and streaming models despite having comparable parameter counts to the diffusion baseline. Stream-R1 achieves the highest total score among all compared methods, surpassing the diffusion baseline Wan2.1. The model attains the best semantic score across all methods and the highest quality score within the autoregressive category. Inference speed is drastically improved over diffusion baselines, running at a much higher frame rate with comparable parameter counts.
The authors conducted a human preference study comparing Stream-R1 against Reward Forcing on 50 long videos across five evaluation dimensions. Results indicate that Stream-R1 is preferred in all categories, with the most significant advantages observed in dynamic reasonableness and visual quality. Stream-R1 achieves the highest win rates in Dynamic Reasonableness and Visual Quality & Aesthetics compared to other dimensions. The model demonstrates a consistent preference advantage in Overall Preference against the baseline method. Temporal Consistency shows a narrower margin of preference compared to the other evaluated dimensions.
The the the table presents an ablation study analyzing the contribution of spatial and temporal reward components to video generation quality. The full model, which combines these elements, demonstrates superior performance across short and long video benchmarks compared to the baseline and intermediate variants. Furthermore, hyperparameter sensitivity analysis indicates that the specific setting for the temporal weight floor is critical, as higher values lead to performance degradation. The full model incorporating temporal reward achieves the best results across all short video metrics and long video totals. Adding temporal reward decomposition results in the largest performance gain, significantly lowering drift in long video generation. Increasing the temporal weight floor parameter negatively impacts short video performance, confirming the optimal configuration of the full model.
The authors evaluate Stream-R1 through automated vision-language assessments, benchmarking, and human preference studies to validate its long video generation capabilities. Results indicate the method outperforms existing baselines in visual fidelity and text alignment while maintaining a balanced profile across motion dynamics and semantic quality. Human evaluations confirm a consistent preference for Stream-R1 over competing approaches, particularly regarding dynamic reasonableness and aesthetics, while ablation studies establish that combining spatial and temporal reward components is critical for minimizing drift.