Command Palette
Search for a command to run...
RaguTeam at SemEval-2026 Task 8: Meno and Friends in a Judge-Orchestrated LLM Ensemble for Faithful Multi-Turn Response Generation
RaguTeam at SemEval-2026 Task 8: Meno and Friends in a Judge-Orchestrated LLM Ensemble for Faithful Multi-Turn Response Generation
Ivan Bondarenko Roman Derunets Oleg Sedukhin Mikhail Komarov Ivan Chernov Mikhail Kulakov
Abstract
We present our winning system for TaskB (generation with reference passages) in SemEval-2026 Task8: MTRAGEval. Our method is a heterogeneous ensemble of seven LLMs with two prompting variants, where a GPT-4o-mini judge selects the best candidate per instance. We ranked 1st out of 26 teams, achieving a conditioned harmonic mean of 0.7827 and outperforming the strongest baseline (gpt-oss-120b, 0.6390). Ablations show that diversity in model families, scales, and prompting strategies is essential, with the ensemble consistently beating any single model. We also introduce Meno-Lite-0.1, a 7B domain-adapted model with a strong cost--performance trade-off, and analyse MTRAGEval, highlighting annotation limitations and directions for improvement. Our code is publicly available: https://github.com/RaguTeam/ragu_mtrag_semeval
One-sentence Summary
RaguTeam’s winning system for SemEval-2026 Task 8 (MTRAGEval Task B) employs a heterogeneous ensemble of seven LLMs with two prompting variants, where a GPT-4o-mini judge selects the best candidate per instance to achieve a conditioned harmonic mean of 0.7827, and introduces Meno-Lite-0.1, a 7B domain-adapted model that delivers a strong cost-performance trade-off.
Key Contributions
- Addressing the challenge of generating faithful responses to multi-turn queries with reference passages, the paper introduces a heterogeneous ensemble framework that combines seven large language models across different families and scales with two distinct prompting variants. A lightweight GPT-4o-mini model functions as an automated judge to select the most appropriate candidate response for each instance, streamlining the selection process without requiring extensive model alignment.
- Evaluations on the SemEval-2026 MTRAGEval Task B benchmark demonstrate that this ensemble architecture consistently surpasses individual models, securing first place among 26 competing teams with a conditioned harmonic mean of 0.7827. The approach outperforms the strongest baseline, gpt-oss-120b, by a substantial margin, while systematic ablations confirm that architectural and prompting diversity is the primary driver of these performance gains.
- The work also delivers Meno-Lite-0.1, a seven-billion parameter domain-adapted model engineered for an efficient cost-performance balance in retrieval-augmented generation workflows. This release is accompanied by a detailed evaluation of the MTRAGEval benchmark that catalogs existing annotation shortcomings and establishes a clear roadmap for future dataset enhancements.
Introduction
Retrieval-augmented generation is shifting from single-turn question answering to complex multi-turn dialogues where systems must ground responses in external evidence while preserving coherence across conversation history. This evolution is essential for deploying reliable conversational AI that accurately resolves coreferences, handles underspecified queries, and prevents hallucinated continuations. Prior systems, however, consistently degrade in late-turn faithfulness and rely on evaluation metrics that poorly capture contextual appropriateness. To overcome these limitations, the authors leverage a heterogeneous ensemble of seven diverse language models to generate candidate responses, then deploy a lightweight GPT-4o-mini judge to automatically select the most faithful output per instance. This judge-orchestrated ensemble strategy, combined with a newly introduced 7B domain-adapted model, achieves top performance on the SemEval-2026 MTRAGEval benchmark and demonstrates that strategic model diversity and LLM-based selection significantly outperform single-model baselines.
Dataset
- Dataset Composition and Sources: The authors utilize a conversational question answering dataset that pairs user queries with retrieved document contexts and multi-turn dialogue history. The benchmark includes standard answerable instances alongside 97 unanswerable questions designed to evaluate model refusal behavior.
- Subset Details: Training examples are partitioned into three mutually exclusive categories based on context availability and conversation state. The first category contains empty contexts with no supporting documents. The second category features empty dialogue history, representing first-turn interactions where documents are available. The third category covers non-empty context and non-empty dialogue history, which constitutes the most frequent and complex scenario requiring cross-turn reasoning. To construct evaluation prompts, the authors select representative medoids from each category using embedding distance, retaining two examples from the largest third category to capture within-group diversity.
- Data Usage and Processing: The dataset serves as the foundation for prompt-based model evaluation rather than direct model training. Group 1 relies on a system prompt alone, while Group 2 augments a base prompt with four category-aware few-shot exemplars. During development, the authors also explored an optional query rewriting pipeline that resolves coreferences and expands relative temporal expressions using dialogue context, though this preprocessing step was ultimately excluded from the final submission.
- Metadata Construction and Annotation Notes: Each instance is structured to clearly separate conversation history, current user queries, and retrieved evidence. The authors note that gold standard responses for underspecified queries explicitly request clarification rather than assuming intent. They also highlight that the original benchmark contains target leakage in unanswerable questions due to empty reference passages, recommending that future iterations include distractor passages to better simulate realistic retrieval scenarios.
Method
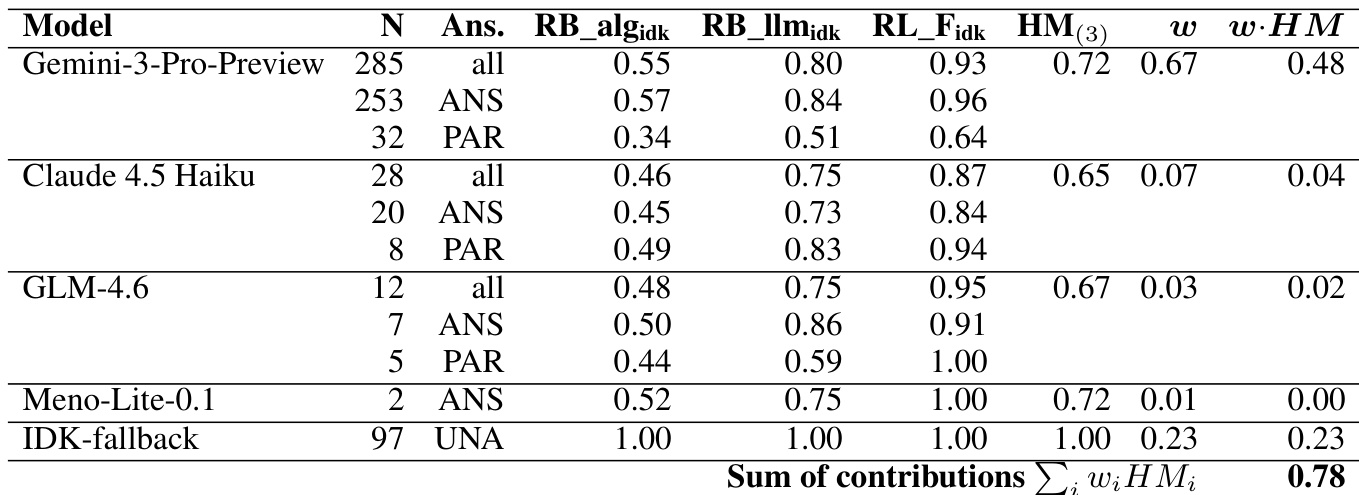
The proposed system follows a three-stage pipeline designed to address the challenges of multi-turn retrieval-augmented question answering, as illustrated in the framework diagram. The first stage involves prompt construction, where two distinct strategies are employed to guide model behavior. In the second stage, seven heterogeneous large language models (LLMs) generate candidate responses in parallel, leveraging the constructed prompts. The final stage consists of a judge-based selection process, where a lightweight GPT-4o-mini model evaluates the generated candidates and selects the most faithful response as the system's output.
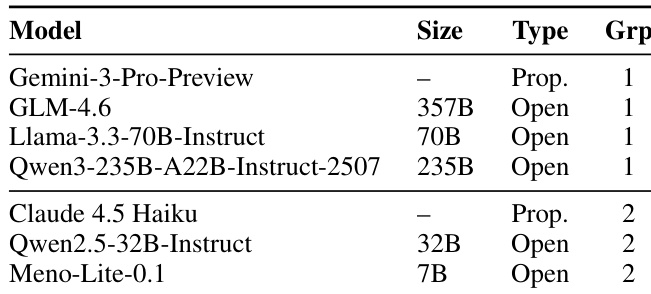
The ensemble composition is detailed in Table 1, which categorizes the seven models into two groups based on their prompting strategy. Group 1 models utilize a refined system prompt P, while Group 2 models employ a few-shot strategy. The models are selected to maximize diversity in architecture, training data, and scale, including both proprietary and open-weight models. This diversity is intended to produce a range of candidate responses with varied failure modes, increasing the likelihood that at least one candidate will be faithful and accurate.
The system prompt P for Group 1 models is derived through an iterative refinement process using a Gemini-based procedure. This process involves analyzing a sample of training instances to identify consistent behavioral patterns, synthesizing these patterns into a concise prompt, and evaluating the prompt's effectiveness. The final prompt P emphasizes strict context adherence, extractive phrasing, depersonalized synthesis, direct delivery, and fidelity to the structure of the source documents. This prompt is designed to ensure that the models rely exclusively on the provided evidence, avoid hallucinations, and generate concise, objective answers.
For Group 2 models, the few-shot strategy augments the prompt with category-aware examples. The training instances are clustered into three structural categories: full context, empty context, and empty history. Four exemplars are selected from these categories using a medoid-based approach to ensure robustness across different dialogue patterns, particularly for unanswerable cases. This strategy aims to provide the models with clear examples of how to handle various input configurations, improving their performance on specific scenarios.
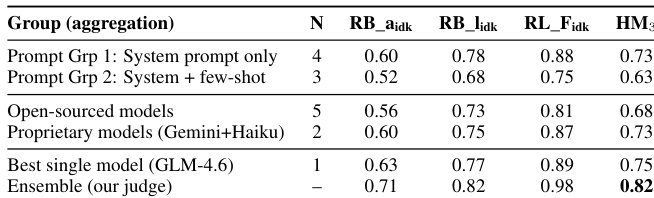
The final stage of the pipeline involves a faithfulness judge, GPT-4o-mini, which evaluates all candidate responses. The judge assesses the faithfulness of each answer based on the provided documents and selects the best-performing response. This selection process is critical for ensuring the system's output is grounded in the evidence, especially in complex multi-turn dialogues where the context and retrieved passages must be integrated correctly. The system's performance is evaluated using conditioned metrics, and the contribution of each model to the final weighted harmonic mean is analyzed, highlighting the importance of diverse candidate generation and effective selection.
Experiment
The evaluation employs a curated conversational dataset to test a heterogeneous ensemble of seven language models, utilizing a dedicated judge to select the most faithful response for each query. Comparative and ablation experiments validate that informed selection successfully exploits complementary model strengths, confirming that architectural diversity and concrete few-shot demonstrations consistently outperform larger single models or abstract system instructions. These findings demonstrate that while faithfulness is necessary, optimal generation requires balancing grounding with pragmatic responsiveness, particularly for ambiguous queries, and highlights the strong cost-performance trade-offs achievable through domain-adapted smaller architectures.
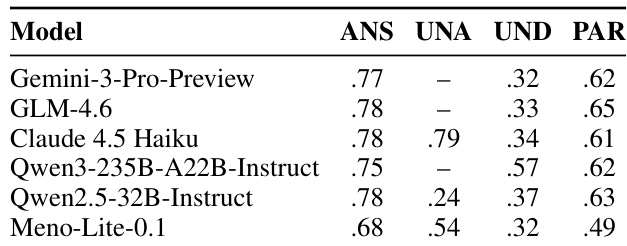
The authors present a comparison of individual model performance across different answerability categories, highlighting variations in how models handle answerable, unanswerable, underspecified, and partially answerable questions. The results show that models differ significantly in their ability to correctly respond or abstain based on the question type, with some models excelling in specific categories while underperforming in others, particularly in underspecified and unanswerable cases. Models exhibit varying strengths across different answerability categories, with some performing well on answerable questions but struggling with unanswerable or underspecified ones. The performance of models on unanswerable questions is highly dependent on their ability to abstain, with significant differences in IDK rates across models. There is a notable gap in performance on underspecified questions, where all models struggle to generate appropriate clarification requests, indicating a challenge for the task.
The the the table lists models used in the experiment, categorized by size, type, and prompting group. The models are divided into two groups based on their prompting strategy, with Group 1 including larger open-weight models and Group 2 containing a mix of proprietary and open-weight models, including a smaller model that demonstrates strong performance despite its size. Models are grouped into two prompting strategies, with Group 1 using a system-prompt-only approach and Group 2 using a system-prompt with few-shot setup. The models vary in size from 7B to 357B parameters, including both proprietary and open-weight models. Meno-Lite-0.1, a 7B model, is included in Group 2, highlighting its performance despite being significantly smaller than other models.
The authors analyze the impact of prompt engineering on model performance by comparing three versions of a system prompt: a bare prompt, an LLM-synthesized prompt, and a self-critiqued revision. Results show that the LLM-synthesized prompt improves performance over the bare prompt, while the self-critiqued revision leads to a significant drop, primarily due to reduced abstention on unanswerable questions. The LLM-synthesized prompt outperforms the bare prompt, indicating that extracting behavioral patterns from responses improves performance. The self-critiqued revision of the prompt reduces performance, likely because it suppresses abstention on unanswerable questions. The final choice of prompt is the LLM-synthesized version, as it balances performance and appropriate response behavior.

The authors present an ensemble system that uses judge-based selection to achieve top performance on a benchmark, outperforming the best baseline by a significant margin. The results highlight the effectiveness of combining diverse models with a faithfulness-focused judge to improve grounded response generation. The ensemble system achieves first place by significantly outperforming the best baseline. Judge-based selection enhances performance by leveraging diverse model outputs and prioritizing faithfulness. The system's success demonstrates the value of combining multiple models with a dedicated evaluation mechanism.

The authors evaluate an ensemble system using a judge-based selection method to choose the best response from multiple models. Results show that the ensemble outperforms individual models and baseline systems, with the highest performance achieved when the judge selects responses based on faithfulness and other metrics. The system leverages diverse models and prompting strategies, with the best results obtained from a combination of open-weight and proprietary models. The ensemble system outperforms individual models and baseline systems, achieving the highest score on the evaluation metric. Judge-based selection significantly improves performance compared to random selection, highlighting the value of faithfulness in response generation. Open-weight models and proprietary models both contribute to the ensemble, with the best results coming from a combination of different prompting strategies and model types.
The experiments evaluate large language models across varying question answerability categories to assess their ability to correctly respond or appropriately abstain, while also examining how different prompting strategies and system architectures impact overall performance. Qualitative analysis reveals that models exhibit distinct strengths and weaknesses depending on whether inputs are answerable, unanswerable, or underspecified, with a consistent struggle to generate effective clarification requests for ambiguous queries. The study further demonstrates that LLM-synthesized prompts enhance behavioral alignment compared to baseline or self-critiqued versions, which inadvertently suppress necessary abstention. Finally, implementing a judge-based ensemble system that combines diverse model outputs with a faithfulness-focused selection mechanism significantly outperforms individual baselines, highlighting the effectiveness of strategic model aggregation.