Command Palette
Search for a command to run...
OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents
OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents
Shuang Chen Kaituo Feng Hangting Chen Wenxuan Huang Dasen Dai Quanxin Shou Yunlong Lin Xiangyu Yue Shenghua Gao Tianyu Pang
Abstract
Deep search has become a crucial capability for frontier multimodal agents, enabling models to solve complex questions through active search, evidence verification, and multi-step reasoning. Despite rapid progress, top-tier multimodal search agents remain difficult to reproduce, largely due to the absence of open high-quality training data, transparent trajectory synthesis pipelines, or detailed training recipes. To this end, we introduce OpenSearch-VL, a fully open-source recipe for training frontier multimodal deep search agents with agentic reinforcement learning. First, we curated a dedicated pipeline to construct high-quality training data through Wikipedia path sampling, fuzzy entity rewriting, and source-anchor visual grounding, which jointly reduce shortcuts and one-step retrieval collapse. Based on this pipeline, we curate two training datasets, SearchVL-SFT-36k for SFT and SearchVL-RL-8k for RL. Besides, we design a diverse tool environment that unifies text search, image search, OCR, cropping, sharpening, super-resolution, and perspective correction, enabling agents to combine active perception with external knowledge acquisition. Finally, we propose a multi-turn fatal-aware GRPO training algorithm that handles cascading tool failures by masking post-failure tokens while preserving useful pre-failure reasoning through one-sided advantage clamping. Built on this recipe, OpenSearch-VL delivers substantial performance gains, with over 10-point average improvements across seven benchmarks, and achieves results comparable to proprietary commercial models on several tasks. We will release all data, code, and models to support open research on multimodal deep search agents.
One-sentence Summary
OpenSearch-VL is an open-source training recipe for frontier multimodal deep search agents that integrates a source-anchor visual grounding data pipeline, a unified tool environment, and a multi-turn fatal-aware GRPO algorithm to mitigate cascading tool failures by preserving pre-failure reasoning, delivering average improvements exceeding ten points across seven benchmarks and performance comparable to proprietary commercial models.
Key Contributions
- OpenSearch-VL provides a fully open training recipe that constructs the SearchVL-SFT-36k and SearchVL-RL-8k datasets via a Wikipedia path sampling and source-anchor visual grounding pipeline. This data preparation is integrated with a diverse tool environment that unifies text search, image search, OCR, cropping, sharpening, super-resolution, and perspective correction to enable active perception.
- The framework implements a multi-turn fatal-aware GRPO algorithm that mitigates cascading tool failures by masking post-failure tokens while preserving valid pre-failure reasoning through one-sided advantage clamping.
- Comprehensive evaluations across seven multimodal deep search benchmarks demonstrate that the method achieves over a 10-point average performance improvement and delivers results comparable to proprietary commercial models.
Introduction
Multimodal deep search elevates vision-language models from passive visual interpreters into active agents that dynamically retrieve evidence and perform multi-step reasoning, a capability essential for solving complex, knowledge-intensive visual queries. Despite its promise, reproducing frontier search agents remains a significant hurdle because leading systems rely on proprietary data, lack transparent training pipelines, and typically assume pristine visual inputs that rarely exist in practice. Existing agentic reinforcement learning approaches also struggle with long-horizon tool use, where a single malformed call or visual degradation cascades into full trajectory failure, forcing models to either discard valuable pre-failure reasoning or learn from noisy post-failure tokens. To address these challenges, the authors leverage a Wikipedia-derived data curation pipeline to generate high-quality multi-hop datasets and deploy a comprehensive tool environment for visual enhancement alongside standard retrieval. They further introduce a fatal-aware GRPO algorithm that selectively masks invalid post-failure tokens while preserving productive pre-failure reasoning through one-sided advantage clamping, ultimately enabling robust multimodal search performance that rivals proprietary commercial models.
Dataset
-
Dataset Composition and Sources
- The authors construct a multi-modal reasoning dataset by combining a custom-curated Wikipedia-derived VQA pool with three open-source corpora: LiveVQA, FVQA, and WebQA.
- The final curated dataset is split into a Supervised Fine-Tuning (SFT) corpus of 36,592 trajectories and an RL dataset of 8,000 instances, collectively released as SearchVL-SFT-36k and SearchVL-RL-8k.
-
Subset Details and Filtering Rules
- Wikipedia Multi-Hop VQA: Generated via constrained random walks over the English Wikipedia hyperlink graph (snapshot from May 2025). Path lengths are sampled from a categorical distribution favoring 2 to 4 hops. Seeds are stratified across five visual categories and must meet infobox, image resolution, and in-degree criteria. The pipeline explicitly skips disambiguation pages, lists, redirects, and high-degree hub nodes (in-degree > 10,000).
- Difficulty Filtering: A frozen Qwen3-VL-32B model applies a two-stage filter to remove samples answerable without tools or solvable via a single image search, ensuring all retained instances require multi-step visual-to-text retrieval chains.
- Visual Enhancement Subset: Ten percent of the filtered pool undergoes controlled image degradation (blur, downsampling, perspective distortion) and is paired with corresponding restoration tools to train robust visual repair behaviors.
-
Data Usage and Training Processing
- The authors use the combined filtered and enhanced instances to synthesize expert trajectories for supervised fine-tuning.
- Each VQA instance serves as a prompt for five independent multi-turn ReAct rollouts using Claude Opus 4.6 in a live tool environment.
- A two-stage rejection sampling process filters these rollouts: first verifying answer correctness with an LLM judge, then evaluating process quality (tool usage, logical consistency, and repetition avoidance) with a second judge.
- The surviving trajectories, averaging 6.3 tool calls each, form the final SFT corpus, while the broader processed set supports subsequent reinforcement learning stages.
-
Metadata Construction and Visual Processing
- The pipeline assigns explicit functional roles to each node in the sampled path: an anchor node for visual grounding, intermediate bridge nodes for relational reasoning, and a final answer node.
- Canonical questions are iteratively rewritten into fuzzy versions to prevent shortcutting, with strict checks for answer invariance, entity uniqueness, and name leakage.
- Visual grounding replaces the anchor node name with a referring expression and pairs it with a representative image from Wikimedia Commons, filtered by CLIP similarity to ensure relevance.
- All final instances are structured as multi-turn ReAct trajectories with embedded metadata tracking tool calls, observations, and reasoning steps to guide policy optimization.
Method
The architecture of OpenSearch-VL is designed to support multi-turn, tool-augmented reasoning over multimodal inputs, combining a structured agent framework with a dual-stage training process. The system operates within a multimodal environment E that returns both visual and textual observations based on the invoked tool, enabling a flexible interaction between a policy model and external resources. The policy, conditioned on the accumulated history hl=(Il,q,a<l,o<l), generates a sequence of actions al=[zl,cl], where zl is a reasoning trace and cl is a tool call or final response. This interaction unfolds as a multi-turn trajectory τ, where each step emits a policy action followed by an environment observation. The trajectory likelihood is modeled autoregressively as πθ(τ∣I0,q)=∏l=0LPθ(zl∣hl)Pθ(cl∣hl,zl), with observations excluded from the generative probability mass. To ensure training stability, a token-level generation mask Mgen(yt) is applied, which excludes non-generated tokens—such as those from textual observations or image-valued outputs—from the loss computation. This masking strategy, inspired by prior work, prevents the policy from being destabilized by noisy, structurally divergent external outputs.
The agent leverages a diverse tool set T=Tv∪Ts, comprising visual tools for image enhancement and parsing (e.g., CROP, OCR, SHARPEN, SUPERRESOLUTION, PERSPECTIVECORRECT) and retrieval tools for external knowledge (e.g., TEXTSEARCH, IMAGESEARCH). These tools are integrated into a unified framework that supports both single-turn and multi-turn interactions. The policy model, implemented using a large language model (LLM), is trained to reason and invoke these tools effectively. The training process consists of two sequential stages: supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, the model is trained on a curated dataset of 36,592 expert trajectories, optimizing a standard objective that jointly supervises the reasoning trace and the subsequent tool invocation or response. This provides a strong initialization for tool-use behaviors and foundational reasoning capabilities.
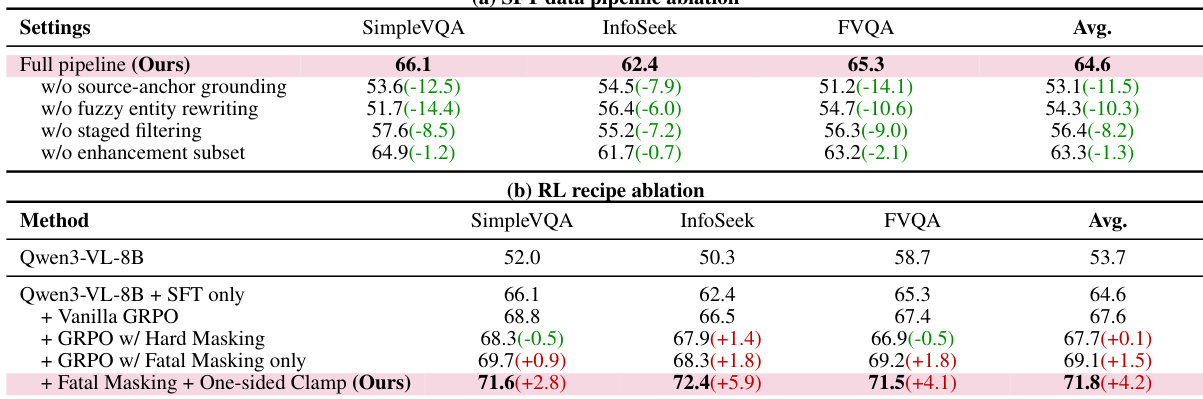
The RL stage builds upon this foundation to discover more effective exploration strategies through multi-turn, search-augmented optimization. The authors employ a variant of Group Relative Policy Optimization (GRPO) that is extended to handle the complexities of a multimodal, tool-interleaved environment. This multi-turn, search-augmented GRPO framework, referred to as fatal-aware GRPO, introduces several key innovations. First, it uses a composite trajectory-level reward r(τ) that balances terminal accuracy (racc), process-level search quality (rquery), and algorithmic formatting (rfmt). The format reward enforces structural integrity by penalizing malformed actions, while the accuracy reward assesses the final answer's correctness via a GPT-4o judge. The query-quality reward provides dense feedback on the reasoning process, evaluating semantic relevance, logical progression, and cross-modal complementary use of tools. Second, to address the challenge of cascading failures in long-horizon tasks, the method introduces a fatal-aware masking strategy. A trajectory is deemed "fatal" when it experiences K=3 consecutive tool-execution errors, and the policy's gradients are zeroed out for all tokens generated after this fatal step index fi. This prevents the model from learning from incoherent post-failure reasoning. Finally, to preserve useful learning signals from partially successful trajectories, the approach applies one-sided advantage clamping: the advantage A^i is set to max(ri,0) for fatal trajectories, ensuring that only those with a partial reward exceeding the group mean contribute positively to the policy update. This strategy generalizes hard-masking baselines by recovering more useful learning signals while avoiding the pathological penalties of standard group-normalization.
The overall training framework is illustrated in the second figure, which depicts the policy model generating multiple rollouts τi in parallel, each interacting with the environment E via tool calls. The rollouts are then evaluated with the composite reward, and the policy parameters are updated using the fatal-aware GRPO objective. This process enables the model to learn robust, multimodal reasoning strategies that are both effective and reliable in complex, real-world scenarios.
Experiment
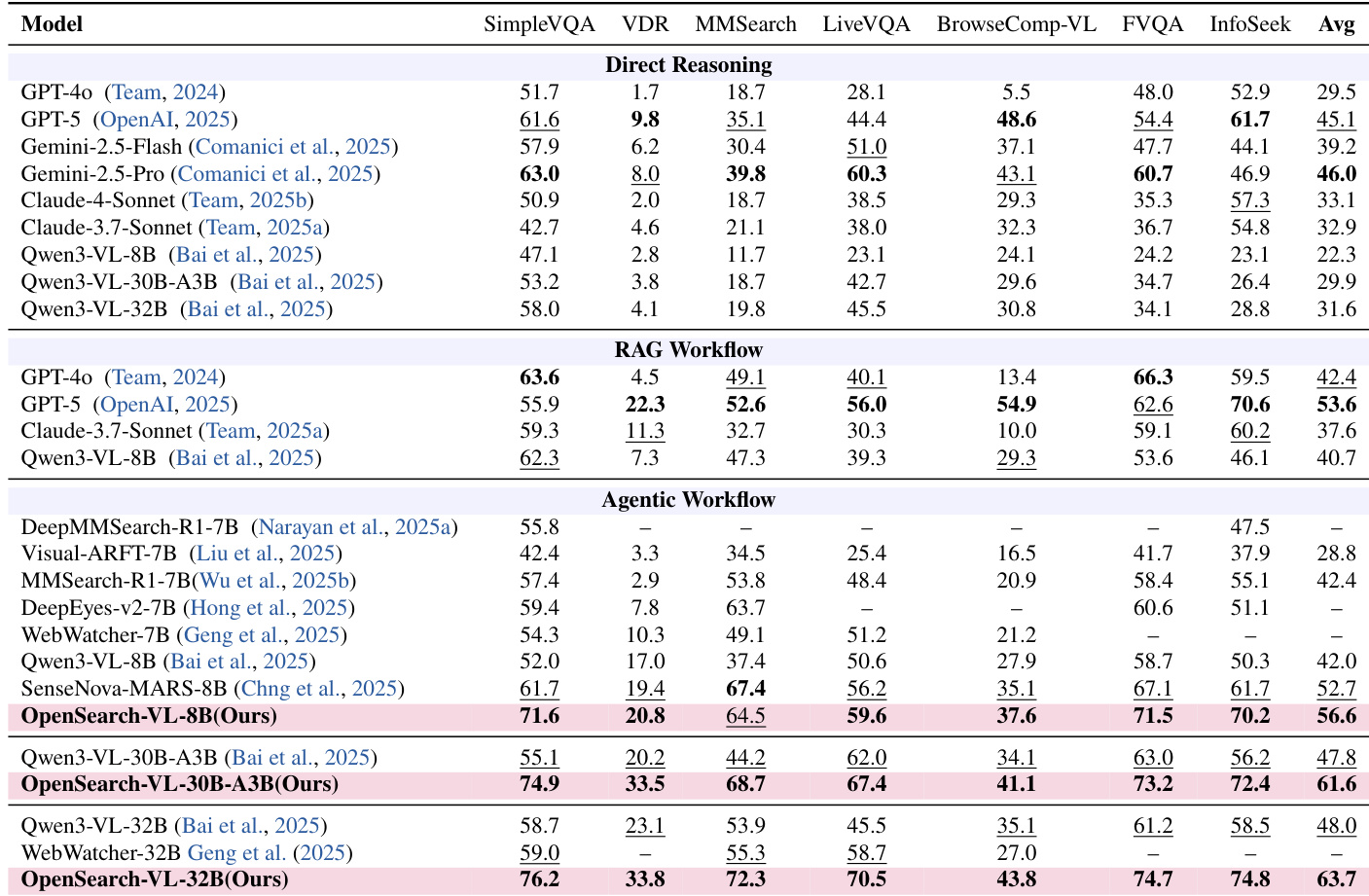
Evaluated across seven multimodal knowledge-intensive benchmarks against direct reasoning, RAG, and agentic baselines, the primary experiments validate the necessity of an autonomous tool-interleaving loop for complex visual queries. The results confirm that this agentic approach consistently outperforms static methods across all model scales, demonstrating effective scalability and superior performance on search-heavy tasks. Counterfactual analyses further validate specific architectural choices, such as query fuzzing and hub avoidance, which are essential for maintaining robust multi-hop reasoning. Finally, qualitative case studies illustrate how the model reliably chains visual inspection and targeted retrievals to progressively verify rather than guess, terminating only when cross-modal confirmation converges.
The authors analyze the impact of key design choices in their pipeline through ablation studies, showing that each component contributes to performance gains. Results demonstrate that the full pipeline outperforms variants with missing components, and the final model achieves the highest scores across benchmarks, indicating the effectiveness of the integrated approach. The full pipeline achieves the highest performance across all benchmarks compared to ablated versions. Removing individual components like source-anchor grounding or fuzzy entity rewriting leads to significant drops in performance. The final model with fatal masking and one-sided clamp outperforms other variants, showing the importance of these design choices.
The authors evaluate OpenSearch-VL across multiple benchmarks, comparing its performance against direct reasoning, RAG workflow, and agentic workflow models. Results show that OpenSearch-VL achieves superior performance in the agentic workflow across all model scales, particularly on complex multimodal tasks requiring tool use and reasoning. The largest model variant outperforms both open and proprietary baselines, demonstrating the effectiveness of the agentic training approach. OpenSearch-VL significantly outperforms direct reasoning and RAG workflow models on all benchmarks, especially in the agentic workflow. The largest model variant achieves the highest average score, surpassing both open and proprietary models. OpenSearch-VL demonstrates strong performance across diverse benchmarks, indicating robustness in handling complex multimodal queries.
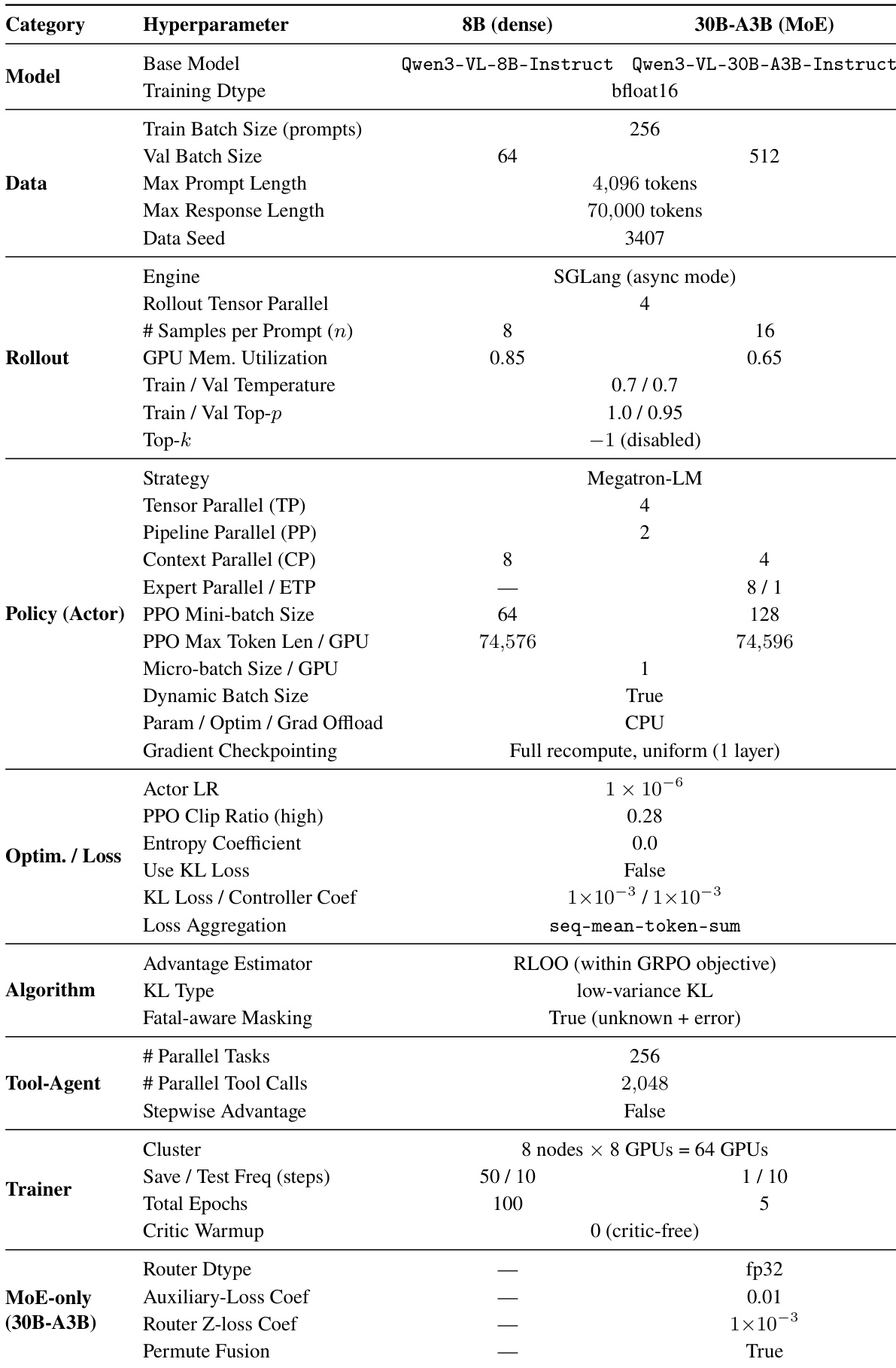
The authors present a detailed configuration of the training setup for their OpenSearch-VL models, highlighting differences in hyperparameters between the 8B dense and 30B-A3B MoE variants. The the the table shows that the two models use different training strategies and hardware configurations, with the MoE model employing a more complex setup involving expert parallelism and a larger number of parallel tool calls. The 8B dense and 30B-A3B MoE models use different training strategies and hardware configurations. The MoE model supports a larger number of parallel tool calls compared to the dense model. The training setup includes specific configurations for rollout, policy, and optimization, with differences in batch sizes and parallelism settings between the two model variants.
The authors validate their approach through comprehensive benchmark evaluations, ablation studies, and detailed training configurations across different model architectures. The ablation experiments confirm that each pipeline component is essential for maintaining peak performance, while the benchmark evaluations demonstrate the framework's superior capability in complex multimodal reasoning and tool use. These results consistently show that the full pipeline outperforms all baseline methods across varying model scales and hardware setups. Ultimately, the findings establish the robustness and scalability of the proposed agentic training strategy.